유비쿼터스 컴퓨팅 환경을 위한 RFID 기반 센서 데이터 처리 미들웨어 기술 동향
유비쿼터스 컴퓨팅을 가능하게 하는 차세대 핵심 기술로 RFID 기술이 주목 받고 있으며, RFID를 기반으로 하는 유비쿼터스 컴퓨팅 환경에서 응용 서비스를 제공하기 위하여 다양한 각도에서 연구 개발이 진행되고 있다. 본 고에서는 RFID를 기반으로 하는 유비쿼터스 컴퓨팅 환경을 구 현하기 위한 EPCglobal의 EPC Network Architecture의 구성 요소에 대하여 알아보고 이를 지원하는 미 들웨어 제품 및 솔루션을 살펴보고, 연속적으로 들어오는 데이터 스트림을 실시간으로 처리하기 위해 수 행되고 있는 프로젝트들의 기술 동향에 대하여 논의한다.
서 론
5C(Computing, Communication, Connectivity, Contents, Calm) 또는 5Any(Any-time, Any-where, Any-network, Any-device, Any-service)를 지향하는, 즉 모든 장소에 컴퓨터가 있어 그것을 자유롭게 누구나가 사용할 수 있는 인간 중심의 미래 컴퓨터 환경인 유비쿼터스 컴퓨팅 환경 실현을 위한 연구 개발이 활발히 진행되고 있다. 마크와이저에 의 하여 제창된 유비쿼터스 컴퓨팅의 주요 사상 중 하나인 고요한 상거래(silent commerce)를 가능하게 하는 차세대 핵심 기술로 RFID 기술이 주목 받고 있으며, RFID를 기반으로 하는 유비쿼터스 서비스 환경 구축을 위한 연구 개발이 진행되고 있다.
사용자의 다양한 요구를 시간과 장소에 상관없이 가능하게 하는 유비쿼터스 서비스 환경을 위해서는 내재되는 다양한 컴퓨팅 디바이스가 생성하는 다양한 대량의 정보를 가공하여 사용자 또는 응용 서비스에게 전달해주는 미들웨어 기술이 요구된다.
본 고에서는 RFID 기술을 기반으로 한 유비쿼터스 컴퓨팅 환경에서 응용 서비스 구축을 지원하는 센서 데이터 처리 미들웨어 기술에 대하여 설명한다. 먼저 유비쿼터스 서비스 환경의 참조 모델로 RFID를 물류, 유통 분야에 적용한 EPCglobal의 EPC Network Architecture에 대하여 살펴보고, RFID 기반의 응용 서비스를 위하여 수집된 RFID 데이터로부터 필요한 데이터를 필터링하여 적절한 장소와 적절한 시간에 전달하는 대표적인 미들웨어 제품에 대하여 소개한다. 또한 이와 같은 미들웨어의 핵심 요소 기술로 끊임없이 연속적으로 들어오는 RFID 데이터를 처리하는 기술인 데이터 스트림 처리 기술 연구 동향에 대하여 설명한다.
EPC Network Architecture
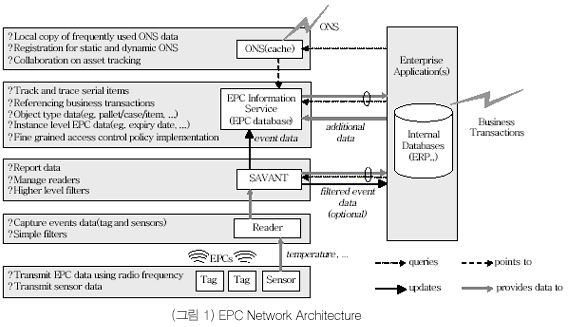
21세기형 차세대 정보 인식을 목적으로 MIT, UCC, P&G 등 46개의 협력사가 공동으로 1999년에 설립된 auto-ID 센터에서는 상품의 세부 정보를 담고 있으며 RF(Radio Frequency) 를 사용하여 내장된 정보를 전송하는 스마트 태그를 각종 상품에 부착해 사물을 지능화하여 사물간, 또는 기업 및 소비자와의 통신을 통해 자동화된 공급망 관리 시스템 구축을 위한 기술을 개발하였다. 이를 표준화하고 상용화하기 위하여 설립된 EPCglobal에서 제안한 EPC Network Architecture는 (그림 1)에 보이는 바와 같이 Electronic Product Code(EPC), 전파식별(Radio Frequency Identification: RFID)와 RFID 리더, SAVANT, EPC 정보서버(Information Server), ONS(Object Name Server) 로 구성된다.
EPC
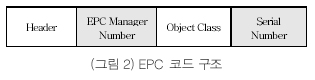
EPC는 새롭게 생성되거나 이미 존재하는 모든 객체들을 유일하게 식별할 수 있도록 주어지는 객체 고유의 코드로 (그림 2)에 보인 것과 같이 EPC 코드에 대한 형식, 버전, 길이 등의 정보를 갖는 EPC 헤더(header), EPC 코드의 관리 책임을 갖는 기업, 즉 제조회사 코드를 표시하는 EPC manager 번호, SKU와 같은 상품의 분류 번호를 표시하는 object class, 그리고 품목 내에서의 개별 제품의 고유 일련번호(serial number)로 구성된다[1]. [1]은 또한 기존의 다양한 코드 체계를 수용하기 위하여 64bit와 96bit 길이의 EPC 코드 체계를 정의하였으며, (현재 256bit 길이의 EPC 코드 체계에대한 표준화 작업이 진행되고 있음) GID(General IDentifier), SGTIN(Serialized Global Trade Identification Number), SSCC(Serial Shipping Container Code), SGLN(Serialized Global Location Number), GRAI(Global Returnable Asset Identifier), GIAI(Global Individual Asset Identifier) 와 같은 다양한 코드 체계를 EPC 코드 체계로 전환하기 위한 매핑 표준을 정의하고 있다.
RFID & RFID 리더
스마트 태그(smart tag)라고도 불리우는 전파식별(RFID)은 무선 주파수를 발산하는 아주 작은 마이크로 칩에 각종 정보를 저장하는 RFID 태그와 태그에 저장되어 있는 정보를 읽거나 기록할 수 있는 RFID 리더와 안테나로 구성된다.
RFID 태그는 태그가 사용하는 전원(power) 의 유무, RFID 태그가 사용하는 주파수 및 RFID 태그가 제공하는 기능에 따라 분류될 수 있다.
전원의 유무에 따라 RFID 태그는 수동형(passive)태그, 반수동형(semi-passive) 태그, 그리고 능동형(active) 태그로 구분할 수 있다. 수동형 태그는 태그의 동작을 위한 전원을 모두 외부(즉, 리더 안테나)에 의존하는 반면, 능동형 태그는 자체 배터리를 내장하고 있고, 반 수동형 태그는 외부 전원과 자체 내장 배터리를 모두 사용한다.
RF의 주파수에 따라 분류하면 접근제어, 동물 관리 등에 사용되는 124~134kHz의 LF(Low Freqeuncy)태그, IC 카드, 신분증 등에 사용되는 13.56MHz의 HF(High Frequency) 태그, 유통 물류 등 컨테이너 식별을 위해 사용되는 400~915MHz의 UHF(Ultra HF) 태그, 그리고 히타치의 뮤칩에서 사용되는 2.45GHz의 마이크로웨이브 태그로 구분할 수 있다 (참고로, 유럽지역에서는 텔레매틱스를 위하여 5.8GHz가 사용되고 있다).
태그의 기능에 따라 RFID 태그를 분류하면 식별태그(identity tag)와 기능 태그(functional tag)로 구분될 수 있다. 식별 태그는 가장 기본적인 형태의 태그로 변경될 수 없는 EPC 코드와 데이터 통신에서 발생할 수 있는 오류를 수정하기 위한 RC(Cyclic Redundancy Checking) 정보만을 갖는 반면, 기능 태그는 식별 태그의 기본적인 정보 외에 임의의 사용자 정보를 저장할 수 있는 기능을 갖는다. 이에 대한 EPCglobal의 표준은 다음과 같다[2]-[4].
• Generation 1 Class 0(C0g1 또는 C0v1): Read-Only(R/O)
• Generation 1 Class 1(C1g1): Write Once, Read Many(WORM)
• Generation 1 Class 2(C2g1): Write Many, Read Many(WMRM)
RFID 태그에 저장된 정보를 읽거나 새로운 정보를 기록하기 위하여 RFID 리더(또는 트랜스폰더)가 사용되며, 각각의 태그의 종류에 따라 서로 통신 프로토콜(air protocol)이 다르기 때문에 하나의 리더로 서로 다른 종류의 태그를 인식할 수 없다.
이와 같은 문제를 해결하기 위하여 EPCglobal에서는 RFID 태그에 대한 Generation 2 표준을 정의 하고 있으며, 2003년 10월 23일 현재 860MHz~960MHz에 해당하는 UHF 클래스에 대하여 공통통신 프로토콜을 사용하는 Class 1(C1g2) 표준화 작업이 “Last Call Working Draft” 상태에 있으며, 2004년 9월까지 완료하여 ISO에 제안할 예정이다.
EPC 정보 서버
EPC Network에서 상품의 제조업자(manufacturer)에 의해 유지되는 EPC 정보 서버(EPC Information Server: EIS)는 생산된 모든 제품에 대한 정보를 제공한다. EPC 정보 서버가 제공하는 데이터는 EPC 코드 데이터, 제조일, 유효기간 같은 인스턴스 데이터, 제품에 대한 카탈로그 정보와 같은 객체 수준의 데이터를 포함한다. 이와 같은 정보를 표현하기 위하여 ML(eXtensible Markup Language)를 기반으로 하는 PML 버전 1.0을 2003년 9월 15일에 발표하였다[5]. 이 규격에는 PML 코어의 범위 및 PML과의 관련성에 대하여 규정하고 있으며, PML 코어의 요구사항과 W3C의 XSD(XML Schema Definition)를 이용한 스키마 구조 및 엘리먼트(element)에 대하여 정의하고 있다.
ONS
웹 상에서 컴퓨터의 위치를 지정해주는 DNS(Domain Name Service)와 유사하게 ONS 는 RFID태그에 저장되어 있는 EPC에 해당되는 제품의 정보 위치를 제공하기 위한 프레임워크이다[6].
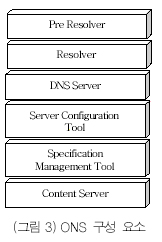
ONS는 DNS 프레임워크 위에서 동작하며, EPC와 연관된 EPC 도메인 이름을 찾아내는 Pre Resolver, EPC 도메인 이름으로 EPC와 연관된 PML 서버들을 구하는 Resolver, PML 서버와 연관된 IP주소와 EPC 도메인 이름 사이의 정보를 매핑하는 DNS 서버, ONS 명세 파일(specification file)을 사용하여 DNS 에 사용되는 바인딩 구성 파일을 생성하는 Server Configuration Tool, ONS가 갱신되었을 때 ONS 명세 파일을 갱신하는 Specification Management Tool, 데이터베이스의 정보를 매핑하여 저장하고 하나 이상의 ONS에 대한 명세 파일을 제공하는 Content Server로 구성되며 (그림 3) 과 같다.
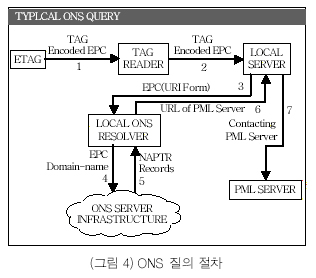
일반적인 ONS로의 질의에 대한 수행절차는 (그림4)에 보인 것과 같이 (1) RFID 태그에 저장되어 있는 비트 시퀀스로 이루어진 EPC를 읽어, (2) 로컬 서버로 보낸다. (3) 로컬 서버는 비트 시퀀스를 URI(Uniform Resource Identifier)로 변경하여 로컬 ONS Resolver로 보내면 (4) Resolver는 URI를 도메인 이름으로 변경하여 DNS 질의를 한다. (5) DNS는 질의의 결과에 해당하는 EPC IS의 URL들을 반환하고, (6) Resolver는 URL들을 로컬 서버로 반환하고 (7)로컬 서버는 반환된 URL에 있는 EPC IS로 EPC에 대한 정보를 얻기 위하여 EPC IS에 접근한다[7].
SAVANT
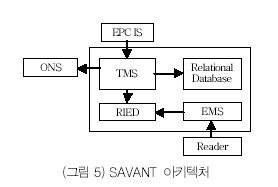
RFID 리더에서 계속적으로 발생하는 EPC 데이터를 기반으로 하는 EPC 이벤트를 처리하고 관리하기 위한 소프트웨어로, EPC 데이터를 캡처하고, 캡처한 데이터를 모니터링 하며, 데이터 전송(transmission)을 담당하는 일종의 라우터 역할을 수행하는 미들웨어이다.
SAVANT의 구조는 (그림 5)과 같이 수집된 데이터를 용도에 맞게 분류하고 해당된 일을 처리하는 곳에 배치하는 역할을 수행하는 이벤트 관리 시스템(Event Management System: EMS), 다중 스냅샷을 유지할 수 있는 실시간 메모리 데이터 구조 (real-time in-memory data structure: RIED), 그리고 기존의 시스템과 연동하여 실제 처리를 수행하는 태스크 관리 시스템(Task Management System: TMS)로 구성되며, 리더 또는 센서와의 통신을 위한 인터페이스, 외부 응용과의 통신을 위한 인터페이스, ONS 또는 EPC IS와의 통신을 위한 인터페이스를 제공하고 있다[7].(현재 SAVANT 규격에는 리더와의 인터페이스와 외부 응용과의 통신을 위한 인터페이스만 정의되어 있다.)
RFID 기반 미들웨어
RFID를 기반으로 하는 유비쿼터스 컴퓨팅 환경에서 응용 서비스 시스템은 고유 정보를 저장하고 있는 RFID 태그, RFID 태그에 저장되어 있는 정보를 판독 및 해독하는 RFID 리더와 안테나, 호스트 컴퓨터와 ERP(Enterprise Resource Planning), SCM(Supply Chain Management)와 같은 응용 서비스 애플리케이션으로 구성된다.
RFID가 다양한 응용 서비스에서 사용되기 위해서는 RFID 장치에 저장되어 있는 데이터를 적절한 장소와 적절한 시간에 응용 서비스로 전달하는 RFID 기반 미들웨어가 요구된다.
RFID 기반 미들웨어가 정확한 데이터를 전달한다는 것은 RFID 장치로부터 수집된 정보 중 응용 서비스가 관심 있는 데이터만을 필터링하여 전달하는 것을 의미한다. 데이터 필터링 기능은 데이터의 형식 및 응용 환경에 따라 요구되는 기능이 달라진다. 단순한 EPC 코드를 활용하는 응용에서 필요한 정보를 얻는 방법과 훨씬 더 복잡한 구조를 갖는 데이터를 이용하 는 응용에서 정보를 필터링하는 방법은 다르다. 또한 처리되어야 할 데이터의 양, 동시에 처리되는 필터링 조건의 수 등을 고려하여 데이터 처리 방법을 채택하여야만 데이터의 손실없이 실시간 처리가 가능하다.
최근에 RFID 기반 미들웨어 제품 및 솔루션들이 많이 개발되고 있으나 주로 EPC 코드 등과 같은 간단한 형식의 데이터를 처리하며, 대량의 데이터 처리에 대한 고려가 미진한 상태로 나와 있는 대표적인 시스템은 다음과 같다.
SUN Savant[8]
EPCglobal의 EPC Network Architecture의 구성 요소인 SAVANT 규격을 기반으로 구현한 선 마이크로시스템사의 Java 플랫폼 기반의 RFID 이벤트 관리기(event manager) 는 여러 개의 리더들로 부터 들어오는 RFID 태그 혹은 센서 데이터 스트림을 처리하는 시스템으로 reader adapter, filter, logger, enterprise gateway로 구성된다. RFID 이벤트 관리기는 RFID 리더와 EPC 네트워크에 연결된 다른 네트워크 장치나 센서들과의 인터페이스와 시스템간에 실시간 데이터를 주고 받을 수 있는 인터페이스를 정의하여 제공함으로써 RFID 데이터와 EPC 정보 서버와의 통합과 라우팅 기능을 제공한다. 또한 서버나 네트워크 장치에 이상이 발생시 이를 수용할 수 있도록 연방 서비스 구조를 지원한다.
TagsWare
자바로 개발된 CapTech사의 TagsWare[9]는 리더를 제어하고, 수집된 데이터를 해석하고, 엔터프라이즈 시스템을 통합하고 패키지된 환경을 확장할 수 있게 하기 위해, 많은 다른 제조사의 RFID 장치를 쉽게 통합할 수 있도록 인터페이스를 추상화하여 제공하며, 응용과의 통합을 위하여 다양한 표준인터페이스를 제공한다. TagsWare는 RFID 리더로 부터 수집된 잡음이 많은 원시 데이터를 엔터프라이즈 시스템에서 사용할 수 있는 추상화된 정보로 변환하기 위해 link라는 컴포넌트를 체인으로 연결된 구조를 통해 정제된 데이터를 제공한다.
RFTagAware
Solaris, Linux, Windows 등 다양한 플랫폼을 지원하는 ConnecTerra사의 RFTagAware[10]는 전사적 응용과의 간편한 통합을 위하여 다양한 형태의 이벤트를 정의할 수 있고, RFID 리더기와 상호작용하여 이를 수행하며, 데이터의 필터링, 카운팅, 그루핑 등을 지원한다. RFTagAware는 데이터를 단순히 전달하는 기능뿐 아니라 안정적인 수행을 위하여 RFID 리더와 서버를 원격 관리하고 모니터링하는 기능을 포함하고 있다.
iMotion
마이크로소프트의 .NET 플랫폼에서 동작하는 GlobeRanger사의 iMotion[11]은 이동 환경에서의 서비스를 지원하기 위한 것으로 RFID 리더에서 읽은 데이터를 처리하여 비즈니스 이벤트로 변환하고, 특정 이벤트에 대한 실시간 알림(alerts) 기능을 제공하고 있다. 또한 비즈니스 로직 구성 및 관리를 용이하게 하기 위한 visual workflow editor와 RFID 리더기, 안테나, 태그의 작동을 에뮬레이터 할 수 있는 visual reader emulator와 같은 도구를 제공한다.
URIS
국내의 ㈜앨릭슨사는 EPC Network Architecture의 구성 요소인 SAVANT 규격을 따르는 RFID 미들웨어인 URIS[12]를 개발하였으며, URIS는 각 제품들의 정보를 읽은 RFID 리더들로부터 실시간 데이터를 수집하는 RFID 멀티 어댑터, RFID 리더로부터 읽은 실시간 데이터들의 필터링과 EPC Network Architecture를 통해 제품의 추적이 가능한 Savant, 그리고 ERP, CRM(Customer Relationship Management), WMS(Warehouse Management System) 등 주요 기업들이 사용하고 있는 기업용 응용과 RFID 시스템을 연동해주는 RFID enterprise middleware로 구성된다.
기타
GenuOne과 Acsis사는 기존의 바코드 미들웨어에 RFID를 지원하기 위한 기능을 추가하였고[13], MIT auto-ID 센터의 초기 참여 기업인 OATSystem사는 장치를 관리 및 모니터링하고 데이터 필터링 기능을 가지고 있는 Senseware를 개발하였다[14],[15].
SAP사는 Java 기반의 솔루션 패키지로 SAP event management와 SAP event portal로 구성되는 SAP auto-ID infrastructure를 제공하고 있으며, RFID 데이터와의 통신뿐 아니라 트래킹 및 추적(tracing) 기능을 가지고 있다[16].
데이터 스트림 처리 프로젝트
RFID를 기반으로 유비쿼터스 환경의 응용 서비스를 지원하는 미들웨어는 지속적으로 끊임없이 입력되는 데이터를 정확하게 실시간으로 처리하고 응용 서비스에서 요구하는 결과를 획득해서 전달하여야 한다. 이와 같은 지속적으로 입력되는 대량의 데이터 스트림을 처리하기 위해 요구되는 사항은 다음과 같이 요약될 수 있다[17].
• 순서(order) 와 시간(time)을 기반으로 하는 데이터 모델과 질의가 허용되어야 한다.
• 질의의 결과로 근사값을 허용하여야 한다.
• 질의에 대한 결과를 얻기 위하여 입력되는 모든 데이터 스트림을 대상으로 하는 블로킹(blocking) 연산을 사용하지 않아야 한다.
• 성능 및 데이터 저장소에 대한 제약으로 인하여 데이터 스트림에 대한 백트래킹(backtracking)은 적절하지 않다.
• 실시간으로 데이터 스트림을 모니터하는 응용에서 비정상적인 데이터에 대하여 빠르게 대응하여야 한다.
• 확장성을 위하여 많은 질의를 공유하여 실행할 수 있어야 한다.
이와 같은 요구사항을 만족하기 위하여 기존의 전형적인 데이터베이스 관리 시스템(Database Management System: DBMS)을 이용하여 데이터 스트림을 일반 테이블에 대한 삽입으로 처리하고, 연속 질의는 트리거(trigger) 또는 객체화된 뷰(materialized view)로 처리할 수 있으나, 다음과 같은 문제점을 갖는다.
• 삽입 연산 부하가 크다.
• 트리거로 표현할 수 있는 조건이 제한적이며, 뷰에는 시퀀스를 표현할 수 없다.
• 근사치와 자원 할당을 표현할 수 없다.
• 지원하는 트리거의 수가 한계가 있다.
• 뷰는 스트림 결과를 제공하지 못한다.
이와 같은 문제점을 해결하고 위에서 언급한 데이터 스트림을 처리하기 위해 요구되는 사항을 만족하기 위하여 (그림 6)과 같은 데이터 스트림 관리 시스템(Data Stream Management System: DSMS)을 개발하기 위한 연구가 진행되고 있다.
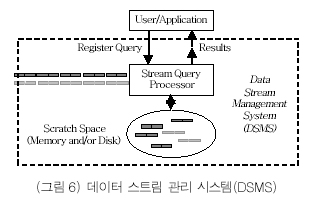
(그림 6)에서 사용자 또는 애플리케이션은 입력되는 데이터 데이터 스트림으로부터 원하는 결과를 얻기위한 질의를 등록해 두고, 지속적으로 입력이 되는 데이터 스트림을 처리하는 스트림 질의 프로세서(stream query processor)는 등록된 질의에 대한 결과를 지속적으로 사용자 또는 애플리케이션으로 반환한다. 이와 같이 특정 저장소에 저장되어 있는 한정된 데이터보다는 끊임없이 계속 만들어지는 데이터에 대한 연속 질의(continuous query)에 대한 처리를 수행하여야 하며, 연속 질의의 결과를 얻기위해 요구되는 데이터를 임시로 유지하기 위한 임시저장 공간(scratch space)을 관리하여야 한다.
이와 같은 DSMS를 구현하기 위한 개략적인 구조는 (그림 7)과 같다[17].
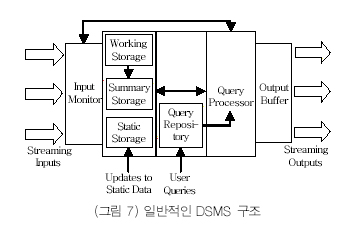
(그림 7)에서 입력 모니터(input monitor) 는 입력되는 데이터 스트림의 양을 조절하기 위한 것이다.
연속 질의를 처리하기 위하여 작업 저장소(working storage), 요약 저장소(summary storage) 그리고 정적 저장소(static storage)가 사용된다. 작업 저장소는 윈도 질의를 처리하기 위해 요구되는 값을 저장하기 위한 저장소이며, 요약 저장소는 근사값 정보를 위한 근사치 데이터를 저장하기 위한 저장소이다. 입력되는 데이터 스트림을 인식한 실제 센서 정보 등의 물리적인 근원지(source)와 같은 메타데이터는 정적 저장소에 유지된다. 질의 저장소(query repository)는 DSMS에서 수행되는 연속 질의를 유지 및 관리하며, 질의 처리기(query processor)는 입력 모니터에서 수집된 값을 기반으로 질의 계획에 대한 최적화와 실제 질의를 수행하여 결과를 출력버퍼(output buffer)에 넣는 역할을 수행한다.
이와 같은 데이터 스트림을 효율적으로 처리하기 위한 다양한 프로젝트가 진행되고 있으며, 그중 대표적인 프로젝트의 개발 목표 및 기능은 다음과 같다.
AURORA 프로젝트
데이터 스트림을 활용하는 애플리케이션들의 요구사항을 효과적으로 충족시키고 애플리케이션들에 제공되는 전반적인 서비스의 질을 극대화하기 위한 기반 인프라를 구축하는 것을 목표로 하고 있는 AURORA 프로젝트[18]는 미국의 Brown 대학, Brandeis 대학, MIT 대학이 공동으로 수행중인 데이터 스트림 관리 시스템(DSMS)을 개발하기 위한 프로젝트이다.
이와 같은 목표를 위하여 데이터 스트림에 대한 실시간 처리, 변화하는 데이터 전송 속도에 따른 메모리 연산 스케줄링 등에 필요한 데이터 스트림 관리 시스템 구조를 개발하고, 로드 밸런싱, 데이터 스트림 관리 시스템 모델 구조, 실시간 질의 처리 모델등을 연구하고 있다. 또한 분산 환경에서 분산 스트림 처리 애플리케이션들에게 높은 확장성과 가용성을 제공하기 위하여 경량화된 비집중화 기술과 부하의 분산 처리, 고장 검출 및 회복 등을 포함한 동적인 연속 내성(introspection)과 최적화를 위한 프로토콜을 개발하고 있다.
AURORA 프로젝트는 데이터 스트림을 처리하기 위해 입력되는 스트림에 대한 한정된 영역에 대해 동작할 수 있는 윈도 기반의 연산자들을 포함하는 Filter, Map, Union, BSort, Aggregate, Join, Resample과 같은 새로운 연산자 집합을 제공하고 있으며, QoS를 위하여 시스템에서 요구되는 시스템의 동작에 대한 명세뿐 아니라 스케줄링과 부하 분산 등의 정책에 대한 QoS 명세를 정의하여 동적인 자원 할당을 가능하게 함으로써 사용자의 실시간 요구 사항을 만족시킨다.
STREAM 프로젝트
STREAM(STanford stREam datA Manager)[19]은 연속적이고 무제한으로 생성되는 데이터 스트림을 효과적으로 처리하고, 연속적으로 입력되는 데이터 스트림과 저장되어 있는 데이터 집합에 대한 연속 질의(Continuous Query: CQ)를 지원하기 위하여 스탠포드 대학에서 수행되고 있다.
이를 위하여 STREAM 프로젝트는 데이터 스트림에 대한 연속 질의를 정의할 수 있도록 표준 SQL을 확장하였으며, QoS를 제공하기 위하여 질의 계획에 대한 모니터링과 재-최적화를 통해 융통성있는 질의 계획과 실행 전략을 수립한다. 또한 제약 조건 탐색, 연산자 스케줄링 등을 통한 한정된 자원 소모를 최소화하고 있으며, 부하 감소(load shedding)를 이용한 근사값 계산을 허용하고 있다.
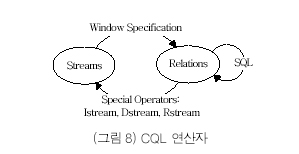
연속 질의를 위한 질의어로 STREAM은 SQL과 유사한 질의 언어인 CQL(Continuous Query Language)를 사용하며, CQL은 데이터 스트림과 윈도를 타임스탬프로 정렬된 테이블로 간주하고 있으며, (그림 8)과 같이 질의에 대한 결과 테이블을 데이터 스트림으로 전달하기 위한 Istream, Dstream, Rstream과 같은 변환 연산자를 제공한다.
NiagaraCQ 프로젝트
NiagaraCQ 프로젝트[20]는 미국 위스콘신 매디슨 대학에서 1999년부터 2002년까지 인터넷 환경에서 연속 질의를 처리하기 위한 고확장성의 시스템을 개발하기 위한 프로젝트이다.
NiagaraCQ 는 기존에 개발한 분산 XML 데이터 검색 엔진인 Niagara에 연속 질의 기능을 확장한 것으로, 분산 환경에서 XML 데이터 스트림에 대한 XML 질의 언어인 XML-QL을 이용한 연속 질의를 지원하며, 고확장성을 위하여 유사한 구조를 갖는 연속 질의를 그룹화함으로써 공통적으로 필요한 연산을 한 번만 수행함으로써 전체적인 질의 처리 성능을 향상시키고 CPU 및 메모리 자원의 사용을 최소화함으로써 단위시간 내에 보다 많은 질의 처리를 가능하도록 한다.
TelegraphCQ 프로젝트
연속 질의를 사용하여 매우 유동적이고 대용량의 데이터 스트림으로부터 원하는 정보를 얻을 수 있도록 하기 위하여 미국 버클리 대학에서 Adaptive Dataflow 구조 개발을 목표로 수행되고 있는 프로젝트로 자바 기반으로 개발된 Telegraph를 데이터 스트림에 대한 연속 질의를 지원하기 위하여 PostgreSQL을 기반으로 새롭게 진행되고 있다.
연속적인 데이터 스트림에 대한 질의 처리를 위하여 입력되는 데이터 스트림에 대한 라우팅과 연산자에 대한 스케줄링을 제공하며, 또한 연산자간의 통신을 제공하고 있다. 또한 질의 처리 비용을 최소화하기 위하여 자원의 공유를 제공하고 있다.
데이터 스트림에 대한 질의를 위하여 TelegraphCQ[21]에서 제공하는 질의 언어인 StreaQuel은 모든 입력과 출력을 스트리밍으로 간주함으로써 스트림과 테이블간의 변환이 필요하지 않다. 또한 윈도 연산을 위하여 WindowIS 연산자를 제공한다.
OpenCQ 프로젝트
인터넷 상의 분산되어 존재하는 이질 정보들의 변화를 효율적으로 모니터링 하기 위해 미국 Georgia Tech에서 1996년부터 진행되고 있는 프로젝트로 인터넷이나 인트라넷에 존재하는 대용량의 분산정보 시스템에서의 정보 변화를 모니터링하기 위하여, 분산되어 있는 서로 다른 시스템들을 동등한 수준으로 접근할 수 있도록 조율함으로써 데이터 전송의 품질 보장과 안정성 그리고 최신 정보를 제공할 수 있는 지능적이며 적응성 있는 구조를 설계하고 분산되어 존재하는 대용량의 정보에서 어떤 특정 정보가 변경되는 것을 변경 시점과 최대한 가까운 시간내에 감지하기 위한 방법과 기술을 개발하고 있다.
OpenCQ[22]는 인터넷상에서 변화된 내용을 감지하여 가져온 후, 그 내용을 사용자에게 전달해주는 시스템으로, 개인별로 알고 싶은 변경사항을 연속 질의로 시스템에 등록하면 시스템이 변경 사항을 모니터링 하여 변경된 내용을 사용자에게 알려준다.
OpenCQ는 입력, 수정, 삭제와 같은 일반적인 변화를 모니터링 함으로써 질의의 대상이 되는 모든 데이터 소스를 검색할 필요 없이 변화된 내용을 반영한 결과를 효율적으로 생산해낼 수 있다.
COUGAR 프로젝트
코넬 대학에서 연구되고 있는 센서 네트워크용 분산 데이터 처리 시스템인 COUGAR[23]는 네트워크의 변화에 동적으로 적응할 수 있고, 유연성(flexibility)과 확장성(scalability) 이 높으며, 고장 감내성(fault tolerant) 을 갖는 데이터 스트림 처리 시스템을 개발하는 것을 목표로 수행되는 프로젝트로, 객체 기반으로 데이터의 수집 및 처리를 중앙에서 처리하는 많은 다른 프로젝트와 달리 데이터 접근과 처리를 모두 분산된 형태로 처리한다.
COUGAR 시스템에서 데이터 스트림은 추상화 자료 구조(Abstract Data Type: ADT)로 표현되며, 모든 데이터 스트림의 소스는 ADT로 모델링 된다. 질의 처리를 위하여 연속 질의의 실행 주기를 표현하기 위한 $every() 절을 포함하는 SQL과 유사 한 질의 언어를 제공한다.
이외의 데이터 스트림 처리 관련 프로젝트로는 버지니아 대학의 DSWare, UCLA의 SensorWare, 프린스턴 대학의 Impala, UC 버클리의 Mate 등이 있다.
결 론
유비쿼터스 컴퓨팅 환경을 구축하기 위하여 차세대 핵심 기술인 RFID 기술을 기반으로 하는 스마트 객체를 활용하는 다양한 응용 서비스를 조기에 구축하기 위해서는 스마트 객체와 응용 서비스를 이음새 없이 연결하는 미들웨어가 요구된다. 즉, 유비쿼터스 컴퓨팅 환경에서 스마트 객체를 활용하는 응용 서비스를 개발하기 위해 요구되는 공통적인 작업은 미들웨어가 처리하도록 하고, 응용 서비스 개발자는 개발하고자 하는 응용 서비스의 본래의 기능만을 고려함으로써 보다 양질의 제품을 조기에 개발할 수 있으며, 새로운 환경으로의 적용을 용이하게 할 수 있다.
본 고에서는 RFID를 기반으로 하는 스마트 객체를 활용하는 유비쿼터스 컴퓨팅 환경을 구축하기 위한 기술들을 표준화하고 상용화하기 위하여 EPCglobal에서 정의한 EPC Network Architecture와 각각의 구성 요소에 대하여 논하고, 유비쿼터스 컴퓨팅 환경의 응용 서비스를 용이하게 구축할 수 있도록 개발된 미들웨어 제품 및 솔루션들의 기능을 살펴봄으로써 현재 미들웨어 기술의 방향에 대하여 살펴보았다. 또한 미들웨어를 구현하기 위하여 지속적으로 끊임없이 생성되는 데이터를 처리하기 위하여 진행되고 있는 데이터 스트림 처리 프로젝트들의 연구동향을 살펴 봄으로써, RFID 기반의 유비쿼터스 컴 퓨터 환경의 응용 서비스를 구축하기 위한 기반 시스템인 미들웨어 기술 개발에 따른 전략 및 정책 방향을 제시하고자 하였다.
원종호 | 데이터베이스연구팀 선임연구원
이미영 | 데이터베이스연구팀 책임연구원, 팀장
김명준 | 인터넷서버그룹 책임연구원, 그룹장
출처 : DB포탈사이트 DBguide.net

원문 : DB포탈사이트 DBguide.net
'Technology > RFID' 카테고리의 다른 글
| RFID 도입, 성공하려면「표준 목매지 마라」 (0) | 2005.04.20 |
|---|---|
| MS 소프트웨어 사업 특명「RFID 잡아라!」 (0) | 2005.03.11 |
| SW업계, "RFID 앞으로!" (0) | 2004.12.08 |
| 「RFID로 데이터센터 관리 쉽게 한다」 (0) | 2004.11.02 |
| RFID, 특허분쟁에 발목 잡히나 (0) | 2004.09.16 |
| 인체용 RFID, 불신받는 진짜 이유 (0) | 2004.09.09 |
