[Ajax] Ajax 마스터하기 - DOM 다루기 [PART 05]
HTML, JavaScript™, DHTML, DOM으로 구성된 Ajax는 볼품없는 웹 인터페이스를 인터랙티브 Ajax 애플리케이션으로 변형하는 획기적인 방식이다. Ajax 전문가인 필자는 이러한 기술들이 어떻게 작용하는지 전체적인 개요를 비롯하여 세부사항 까지 설명한다. 또한 XMLHttpRequest 객체 같은 Ajax의 중심적인 개념들을 소개한다.
5년 전, XML에 대해 무지했다면 아무도 얘기할 상대가 없는 미운 오리 새끼 신세가 되었을지도 모르겠다. Ruby 프로그램이 주목을 받았던 8개월 전, Ruby 프로그램 언어 기능에 대해 알지 못했던 프로그래머들은 냉수기 관련 산업세계에서 환영 받지 못했다. 그런 것처럼, 최신 기술단계로 입문하고자 한다면 Ajax에 대해 알아야 한다.
하지만 Ajax는 일시적으로 유행하는 툴이 아니다. 웹 사이트를 구축하는 강력한 방식이며 완전히 새로운 언어를 배우는 것보다는 그다지 어렵지 않다.
Ajax에 관해 자세히 들어가기 전에 잠시 Ajax의 기능에 대해 알아보자. 오늘날 애플리케이션을 작성할 시 두 가지 애플리케이션이 있다.
두 애플리케이션은 다 친숙한 것들이다. 일반적으로 데스크톱 애플리케이션은 CD상에 배치된 다음 (또는 웹 사이트에서 다운로드) 컴퓨터에 완전 설치된다. 이 애플리케이션은 인터넷을 이용해 업데이트를 다운로드하기도 하지만 애플리케이션 실행 코드는 데스크톱 상에 상주해 있다. 전혀 새로운 것이 아닌 웹 애플리케이션은 웹 서버 상에서 실행되며 웹 브라우저 상에서 접속된다.
하지만 두 애플리케이션에 대한 코드 실행 위치보다 애플리케이션 작동방식 및 애플리케이션과 사용자와의 상호작용방식이 중요하다. 일반적으로 데스크톱 애플리케이션은 상당히 빠르고 (컴퓨터 상에서 실행되고 인터넷 상에서 대기 중인 상태가 안 나온다.), 대형 사용자 인터페이스(일반적으로 운영체제와 상호작용)를 갖추며 상당히 동적이다. 거의 대기시간 없이 메뉴 및 하위 메뉴를 클릭, 지시, 입력하고 풀업한다.
반면 웹 애플리케이션은 가장 최신 것이며 데스크톱에서는 전혀 얻을 수 없는 서비스를 제공한다.(Amazon.com 및 eBay를 생각해 볼 것.) 하지만 웹 애플리케이션 기능으로 인해 서버 응답 대기, 스크린 재생 대기, Request 컴백 및 새 페이지 생성에 관한 대기 기능 등이 부수된다.
분명 지나친 단순화 과정임에는 틀림없지만 기본 개념은 얻게 된다. 이미 눈치를 챘겠지만 Ajax는 데스크톱 애플리케이션 및 항상 업데이트 되는 웹 애플리케이션의 기능 및 상호작용 간의 차이를 줄여주는 역할을 한다. 여러분은 마치 데스크톱 애플리케이션에서 찾은 것처럼 동적 사용자 인터페이스 및 가상 제어기능을 사용한다. 하지만 웹 애플리케이션 상에서 데스크톱 애플리케이션을 이용할 수 있다. 그러면 대기 중인 것이 무엇인가? Ajax 및 볼품없는 웹 인터페이스가 응답 Ajax 애플리케이션으로 변환되는 과정에 대해 살펴보기로 하자.
그러면 대기 중인 것이 무엇인가? Ajax 및 볼품없는 웹 인터페이스가 응답 Ajax 애플리케이션으로 변환되는 과정에 대해 살펴보기로 하자.
오래된 기술, 새로운 기법
Ajax에 관해 살펴보면 Ajax는 실지로 많은 기술들이 응집되어 있다. Ajax의 기본을 마치고 넘어가려면 몇 가지 다른 기술들(필자는 첫 번째 이 시리즈에서 각각의 기술에 관해 설명할 것이다.)을 면밀히 살펴보아야 한다. 하지만 이들 기술 가운데 어느 정도 알고 있는 것이 많은 건 다행이다. 더군다나 각각의 기술 대부분은 Java/Ruby같은 프로그래밍 언어만큼 어려운 게 아니라서 배우기 쉽다.
Ajax 애플리케이션에 포함된 기본기술은 다음과 같다.
웹 양식을 구축하고 애플리케이션 완료 때까지 사용되는 필드를 식별하는 데 HTML을 사용한다.
자바 스크립트 코드는 Ajax 애플리케이션을 실행하는 중심 코드며 서버 애플리케이션과의 커뮤니케이션을 용이하게 한다.
DHTML(동적 HTML)은 웹 양식을 동적으로 업데이트 한다. div, span및 기타 동적 HTML 요소를 사용해 HTML을 마크업 한다.
서버에서 복귀된 HTML 및 (때로) XML 구조를 다루는 데 있어 DOM, 즉 문서 객체 모델(Document Object Model)을 사용한다.
이 기술들에 대해 간략히 요약하고 각 기술의 기능에 대해 좀 더 알아보기로 하는데 각 기술에 관한 자세한 사항은 차후 글에서 다룰 것이다. 우선은 Ajax의 구성요소 및 기술에 대해 친숙해 지는 데 초점을 맞추기로 한다. 자바 스크립트에 익숙할수록 Ajax에 담긴 기술에 관한 일반적인 지식 단계에서 각 기술에 관한 자세한 지식으로 넘어가는 게 더 쉬워진다.(또한 이로 인해 웹 애플리케이션 개발에 관한 문이 열리게 된다.)
Ajax 정의
Ajax는 비동기 JavaScript 및 XML의 약어이다.(DHTML도 마찬가지다.) Adaptive Path사의 Jesse James Garrett이 이 약어를 만들어냈으며(참고자료 참조), Jesse에 따르면 이 약어는 두문자어는 아니라고 한다.
XMLHttpRequest 객체
알고자 하는 객체 중 첫 번째는 아마도 가장 생소한 것이 아닌가 싶다. 그 객체는 일명 XMLHttpRequest인데 자바 스크립트 객체의 일종이며 Listing 1에 나와 있는 것처럼 단순하게 생성된다
Listing 1. 새로운 XMLHttpRequest 객체 생성
<script language="javascript" type="text/javascript">
var xmlHttp = new XMLHttpRequest();
</script>
필자는 다음 글에서 이 객체에 대해 더 논의할 것이다. 하지만 지금 상태에서는 모든 서버 커뮤니케이션을 다루는 객체라는 사실만 알아둔다. 다음 사항으로 가기 전에 잠깐 생각해 보면 자바 스크립트 객체는 XMLHttpRequest를 통해 서버에 전달하는 자바 스크립트 기술의 일종이다. 이 객체는 애플리케이션 흐름이 정상적이지 않으며 Ajax 기술의 많은 부분을 차지하고 있다.
정상적인 웹 애플리케이션에서 사용자는 양식 필드를 기입하며 제출 버튼을 클릭한다. 그러면 전 양식을 서버에 보내며 서버는 처리과정을 통해 양식을 스크립트(일반적으로 PHP, 자바 또는 CGI 과정/이와 유사한 과정)에 전송한다. 스크립트를 실행할 때 스트립트를 통해 완전히 새로운 페이지가 전송된다. 그 페이지는 데이터가 작성된 새로운 양식의 HTML/확인 페이지 또는 원 양식에 기입된 데이터에 근거해 선택된 옵션이 포함된 페이지일 수 있다. 물론, 서버 상의 스크립트/프로그램이 처리되면서 새로운 양식을 다시 보내는 동안 사용자는 대기해야 한다. 서버로부터 데이터를 다시 받을 때까지는 스크린 상에 아무 것도 없게 되며 결국 대화성은 낮게 된다. 사용자는 즉각적으로 응답을 받지 못하며 데스크톱 애플리케이션 상에서 작업하는 기분이 들지 않게 된다.
Ajax는 근본적으로 자바 스크립트 기술 및 웹 양식 및 서버 간의 XMLHttpRequest 객체를 결합한다. 사용자가 웹 양식을 기입할 때 데이터는 직접 서버 스크립트에 전송되지 않고 자바 스크립트 코드에 전달된다. 대신 자바 스크립트 코드는 양식 데이터를 포착해 Request를 서버에 전송한다. 이 과정이 일어나는 동안, 사용자 스크린 상의 양식은 순식간에 나타나거나 깜빡이거나 사라지거나 정지하지 않는다. 즉 자바 스크립트 코드는 몰래 Request를 전송하며 사용자는 Request가 만들어졌는지도 알지 못한다. 게다가 Request를 비동기적으로 전송하기 때문에 더 좋은 상황이 된다. 이는 자바 스크립트에서 서버 응답을 그냥 대기하지 않는다는 것을 의미한다. 따라서, 사용자는 데이터를 계속 기입하고 화면이동하고 애플리케이션을 사용한다.
그런 다음 서버는 자바 스크립트 코드(웹 양식에 대해 아직도 대기 중임)에 데이터를 다시 전송한다. 자바 스크립트 코드에서는 데이터와의 상호기능을 결정하며 연속적으로 양식 필드를 업데이트 하면서 애플리케이션에 즉각적인 응답을 준다. 결국 사용자는 양식을 제출/재생하는 작업 없이 새로운 데이터를 얻게 된다. 자바 스크립트 코드는 데이터를 얻고 계산도 수행하며 또 다른 Request를 전송하며 이런 모든 과정은 사용자 개입 없이도 된다! 이것이 바로 XMLHttpRequest 객체의 장점이다. XMLHttpRequest 객체는 서버와 같이 커뮤니케이션을 주고받고 사용자는 그 과정에서 벌어지는 과정을 알지 못한다. 이로 인해 데스크톱 애플리케이션과 마찬가지로 동적, 상호 반응적인 고도의 양방향 경험을 얻게 되지만 그 속에 인터넷의 모든 장점이 담겨 있다.
자바 스크립트에 대한 부가사항
일단 XMLHttpRequest에 대해 다루게 되면 나머지 자바 스크립트 코드는 상당히 평범한 것들이다. 사실 다음과 같은 기본적인 작업에 자바 스크립트 코드를 이용한다.
양식 데이터 얻기: 자바 스크립트 코드로 HTML 양식에서 데이터를 꺼내 이를 서버에 전송하는 작업이 간단해진다.
양식 상의 값 변환: 필드 값 설정에서 연속적인 이미지 교체작업에 이르는 양식 업데이트 작업 또한 간단하다.
HTML 및 XML 구문분석: 자바 스크립트 코드를 이용해 DOM(다음 섹션 참조)을 처리하고 서버에서 다시 전송하는 HTML 양식 및 임의의 XML 데이터에 관한 구조를 다루게 된다.
첫 번째 두 항목에 대해서 여러분은 Listing 2에 나온 대로 getElementById()에 익숙해지려 할 것이다.
Listing 2. 자바 스크립트 코드에서의 필드 값 포착 및 설정
// Get the value of the "phone" field and stuff it in a variable called phone
var phone = document.getElementById("phone").value;
// Set some values on a form using an array called response
document.getElementById("order").value = response[0];
document.getElementById("address").value = response[1];
Ajax 애플리케이션에서 특별히 획기적인 사항은 없고 상기 사항 정도면 충분하다. 이에 대해 상당히 복잡한 건 없다는 사실을 깨달아야 한다. 일단 XMLHttpRequest만 정복하면 Ajax 애플리케이션에서 나머지는 대부분 Listing 2에 나온 바와 같이 상당히 독창적인 HTML과 결합된 단순 자바 스크립트 코드다. 그런 다음 가끔 약간의 DOM 작업이 발생하게 된다. 이에 관해 살펴 보자.
DOM으로 종료하기
DOM, 즉 문서 객체 모델이라는 것이 있는데 이는 아주 중요하다. DOM에 대해 듣는 것은 그다지 어렵지 않다고 하는 사람들이 있다. HTML 디자이너에 의해서는 종종 사용되지 않으며 하이-엔드 프로그래밍 작업으로 들어가지 않는 한은 JavaScript 코더에서 흔치 않은 것이 바로 DOM이다. 종종 과중-업무 Java 및 C/C++ 프로그램 상에서 DOM을 종종 많이 활용하게 된다. 사실은 DOM이 배우기 어려운 특성 때문에 명성이 자자해 그 프로그램 상에서 종종 사용하는 것이 아닌가 싶다.
다행히도 JavaScript 기술에 있어 DOM을 활용하는 일은 쉽고 대부분 직관적이다. 이 시점에서 필자는 DOM 사용법에 관해 보여 주고 적어도 이에 대한 몇 가지 코드 예를 제시하려 하지만 이 글의 의도와는 벗어나는 것 같다. DOM에 관해 대략적으로 다루는 것 없이도 Ajax에 대해 깊이 다룰 수 있다. 필자는 차후의 글에서 다시 DOM에 관해 다루려 한다. 하지만 지금 상황에서는 언급하지 않으려 한다. JavaScript 코드와 서버 사이에 XML을 이리저리 전송하고 HTML 양식을 변화시킬 때 DOM에 대해 자세히 다루게 될 것이다. 지금은 DOM없이 효과적인 Ajax 애플리케이션을 작동하는 게 쉬우므로DOM은 논외로 한다.
Request 객체 얻기
Ajax 애플리케이션에 관한 기본적 개념에 대해 배웠으면 몇 가지 특수사항에 대해 살펴 보자. XMLHttpRequest 객체는 Ajax 애플리케이션에서 중요하므로, 아마도 많은 이들에게는 생소한 것일 수도 있다. 거기서 필자는 논의를 시작한다. Listing 1에서 보다시피, XMLHttpRequest 객체를 생성, 사용하는 것은 상당히 쉬워야 한다. 잠깐만 기다려 보시라.
수년 동안 브라우저에 관한 논란은 끊이지 않았고 동일한 브라우저로는 아무 것도 얻을 수 없다는 사실을 기억하는가? 믿건 말건, 소규모 브라우저에서도 이와 같은 논쟁은 끊이지 않고 있다. 더군다나 놀라운 사실은 XMLHttpRequest가 이 논란의 희생양 중 하나라는 것이다. 따라서 XMLHttpRequest 객체를 작동시키기 위해선 몇 가지 다른 작업을 해야 한다. 단계별로 설명하겠다.
Microsoft 브라우저 다루기
Microsoft 브라우저, Internet Explorer는 XML을 다룰 시 MSXML 구문분석계를 사용한다.(참고자료 참조) Internet Explorer 상에서 다뤄야 할 Ajax 애플리케이션을 작성할 시 독특한 방식으로 XMLHttpRequest 객체를 작성해야 한다.
하지만 그렇게 간단한 작업은 아니다. Internet Explorer에 설치된 JavaScript 기술 버전에 따라 MSXML 버전도 변하게 되며 실지로 2개의 버전이 있다. 따라서 두 경우를 다루는 코드를 작성해야 한다. Microsoft 브라우저 상에서 XMLHttpRequest 객체를 생성하는 데 필요한 코드에 관해선 Listing 3을 보라.
Listing 3. Microsoft 브라우저 상에서 XMLHttpRequest 객체 생성
var xmlHttp = false;
try {
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
try {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e2) {
xmlHttp = false;
}
}
모든 작업이 정확히 맞아떨어지는 것은 아니다. 하지만 그래도 상관없다. 이 시리즈가 끝나기 전에 JavaScript 프로그래밍, 에러 취급 및 조건부 번역 및 기타 사항에 관해 자세히 다루게 될 것이다. 지금 현 상태에서는 두 가지 중심 라인만 다루고자 한다.
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP");
and
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");.
간단히 말해서, 이 코드로 MSXML의 한 버전을 이용해 XMLHttpRequest 객체 생성을 기한다. 하지만 객체가 생성되지 않는 경우 다른 버전을 사용해 XMLHttpRequest 객체를 생성한다. 두 코드 다 작동되지 않는 경우 xmlHttp 변수는 거짓으로 설정되고 작동되지 않는 것이 있다는 것을 코드에 알려 준다. 그럴 경우, 비-Microsoft 브라우저가 있을 가능성이 있다. 따라서 객체 생성을 위해선 다른 코드를 사용해야 한다.
Mozilla 및 Microsoft 브라우저 다루기
인터넷 브라우저를 선택하지 않거나 비-Microsoft 브라우저를 작성할 경우 다른 코드가 필요하다. 사실, 이 라인은 Listing 1에서 봤던 단순 코드라인이다.
var xmlHttp = new XMLHttpRequest object;.
이 단순한 라인으로 Mozilla, Firefox, Safari, Opera 및 임의의 양식/형태에서 Ajax애플리케이션을 지원하는 기타 비-Microsoft 브라우저에서 XMLHttpRequest 객체를 생성한다.
지원기능 통합
여기서 모든 브라우저를 지원하는 것이 중요하다. Internet Explorer/비-Microsoft 브라우저에서만 작동되는 애플리케이션을 작성하는 사람이 어디 있겠는가? 또한 더 심한 경우, 애플리케이션을 두 번 작성하고자 하는가? 물론 아니라고 믿는다. 따라서 코드에선 Internet Explorer 및 비-Microsoft 브라우저를 지원하는 기능이 포함되어야 한다. Listing 4에서는 다중-브라우저 방식으로 작동하는 코드에 대해 나와 있다.
Listing 4. 다중 브라우저 방식으로 XMLHttpRequest 객체 생성하기
/* Create a new XMLHttpRequest object to talk to the Web server */
var xmlHttp = false;
/*@cc_on @*/
/*@if (@_jscript_version >= 5)
try {
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
try {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e2) {
xmlHttp = false;
}
}
@end @*/
if (!xmlHttp && typeof XMLHttpRequest != 'undefined') {
xmlHttp = new XMLHttpRequest();
}
지금 현재로선, 주석 및 @cc_on와 같은 어려운 태그를 무시한다. 이들은 다음 글에서 깊이 다룰 JavaScript 컴파일러 명령으로 오로지 XMLHttpRequest 객체 상에만 초점이 맞추어져 있다. 이 코드에 관한 핵심은 세 가지 과정으로 요약된다.
1. 변수 xmlHttp를 생성해 앞으로 생성할 XMLHttpRequest 객체를 참조한다.
2. Microsoft 브라우저에서의 객체를 시도, 생성한다.
- Msxml2.XMLHTTP 객체를 사용해 XMLHttpRequest 객체를 시도, 생성한다.
- 과정이 실패할 경우, Microsoft.XMLHTTP 객체를 사용해 XMLHttpRequest 객체를 시도, 생성한다.
3. xmlHttp가 아직도 설정되지 않은 경우 비-Microsoft 방식으로 XMLHttpRequest 객체를 생성한다.
위 과정 끝 단계 시 사용자가 실행하는 브라우저 종류에 관계없이 xmlHttp의 경우 유효한 XMLHttpRequest 객체를 인용한다.
보안
보안이란 무엇인가? 오늘날 브라우저는 사용자들에게 보안 레벨을 올리고 JavaScript 기술을 생성하며 브라우저 옵션을 해제하는 기능을 제공한다. 이 경우 코드가 작동되지 않는 경우도 있을 수 있다. 그 때 발생하는 문제를 적절하게 다뤄야 한다. 이에 관한 내용은 적어도 기사 한 분량을 차지할 정도라 나중에 다루기로 하겠다.(긴 시리즈가 될 것 같다, 그렇지 않은가? 하지만 걱정 마시라. 과정을 다 배우고 나면 이와 관련된 모든 사항을 숙달할 테니까.) 현재로선 강력하지만 완전하지 않은 코드를 작성하는 중이다. 이 코드는 Ajax 애플리케이션을 관리하는 데 좋다.
Ajax 세계에서의 Request/Response
인제 Ajax 애플리케이션에 대해 이해하고 XMLHttpRequest 객체 및 객체 생성에 관한 기본적인 개념을 얻는다. 자세히 읽다 보면 Ajax 애플리케이션은 웹 애플리케이션에 제출되는 HTML 양식보단 서버 상의 임의의 웹 애플리케이션에 대화하는 JavaScript 기술이라는 사실을 알게 된다.
그러면 빠진 부분은 어떤 것인가? 실질적인 XMLHttpRequest 객체 사용법이다. 이 객체는 작성하는 각각의 Ajax 애플리케이션에서 일정 형태로 사용하는 중요 코드라 Ajax 애플리케이션이 포함된 기본 Request/응답 모델 모양을 통해 객체 사용법을 빨리 익힌다.
Request 만들기
새로운 XMLHttpRequest 객체가 있는 경우 이를 시험해 보자. 먼저 웹 페이지에서 호출하는 JavaScript 방법이 필요하다.(사용자가 텍스트에서 입력하거나 메뉴에서 옵션을 선택할 시와 같음.) 그 다음, 거의 모든 Ajax 애플리케이션에서의 동일한 기본 아웃라인을 따른다.
1. 웹 양식으로부터 필요한 모든 데이터 얻기
2. 연결할 URL 구축
3. 서버 연결
4. 서버 실행 종료 시 서버 실행 기능 설정
5. Request 전송
Listing 5는 위의 순서대로 5단계를 진행하는 Ajax 방법의 예에 관해 나와 있다.
Listing 5. Ajax가 포함된 Request 만들기
function callServer() {
// Get the city and state from the web form
var city = document.getElementById("city").value;
var state = document.getElementById("state").value;
// Only go on if there are values for both fields
if ((city == null) || (city == "")) return;
if ((state == null) || (state == "")) return;
// Build the URL to connect to
var url = "/scripts/getZipCode.php?city=" + escape(city) + "&state=" + escape(state);
// Open a connection to the server
xmlHttp.open("GET", url, true);
// Setup a function for the server to run when it's done
xmlHttp.onreadystatechange = updatePage;
// Send the request
xmlHttp.send(null);
}
Ajax 코드에 관한 많은 것이 명백하다. Ajax 코드의 첫번째 비트는 몇 가지 양식 필드 값을 포착하는 기본 JavaScript 코드를 사용한다. 그런 다음 이 코드에서는 연결 최종 목적지로 PHP 스크립트를 설정한다.
PHP 스크립트의 URL을 지정한 다음(양식에서 나온) 단순한 GET 매개변수를 이용해 이 URL에 도시 및 국가를 추가한다. 그 다음 연결하면 먼저 XMLHttpRequest 객체가 작동되는 것을 보게 된다. 연결방법은 연결 URL 뿐만 아니라, GET 매개변수에도 나와 있다. 최종 매개변수를 true로 설정한 경우, 이 매개변수에선 비동기식 연결(Ajax를 만든다.)을 요구한다. false로 설정한 경우엔 Request를 만들 시 서버 상에서 Ajax에서의 JavaScript 코드가 대기하고 응답을 받을 때 코드가 지속된다. 사용자는 최종 매개변수를 true로 설정하면서 서버에서 배경에 있는 Request를 처리하는 동안 사용자는 웹 양식(심지어는 기타 JavaScript 방식)을 여전히 사용한다.
한편 xmlHttp(이것은 XMLHttpRequest 객체의 인스턴스라는 사실을 기억하라.)의 onreadystatechange 속성으로 서버 실행이 종료될 시(5분/5시간 내에 종료될 수 있음) 서버 기능을 명령한다. 이 코드는 서버 상에서 대기하지 않기 때문에 서버가 기능을 인식해 서버에 응답할 수 있도록 하는 게 필요하다. 이 경우 서버에서 Request를 처리하면서 종료 시 이른바 updatePage()라 불리는 특수 방법을 트리거한다.
최종적으로 send() 코드를 0(null) 값으로 호출한다. 데이터를 추가해 이를 서버에 전송하므로 Request에는 추가해서 보낼 게 없다. 이렇게 되면 Request를 발송하고 서버는 서버에 요구된 기능을 실행한다.
이 코드에서 나오는 것이 없는 경우, 코드가 상당히 간단하다는 것을 명심하라. 이 코드는 Ajax 애플리케이션의 비동기적 특성을 제외하고는 상당히 단순하다. 이 코드를 통해 복잡한 HTTP Request/응답 코드보다는 근사한 애플리케이션 및 인터페이스에 완전 초점을 맞추도록 한다는 사실을 여러분은 높게 평가할 것이다.
Listing 5의 코드는 코드를 얻는 방법만큼이나 쉽다. 데이터는 단순 텍스트이고 Request URL의 일부로 포함된다. GET 매개변수는 더 복잡한 POST대신 Request를 전송한다. 여기에 덧붙일 XML/컨텐츠 헤더가 없고 Request 본체에 전송할 데이터도 없다. 이게 바로 Ajax 유토피아다.
그렇다고 미리 겁먹지 마라. 시리즈가 계속될수록 문제는 더 복잡해진다. 그 때는 POST Request를 전송하는 방법, Request 헤더 및 컨텐츠 형식을 설정하는 방법, 메시지에 XML을 설정하는 방법 및 Request에 보안기능을 추가하는 방법을 배우게 되는데 배우는 목록만 해도 상당히 길다! 지금은 이런 어려운 주제에 대해 신경 쓰지 말자! 그냥 기본만 충실하게 익히면 Ajax 전체 툴을 구축하게 된다
응답 취급과정
이제 서버 응답을 실지로 취급해야 한다. 이 시점에서는 정말로 두 가지 사항만 알면 된다.
xmlHttp.readyState 속성이 4와 같을 때까지는 어떤 작업도 해선 안 된다.
서버는 xmlHttp.responseText 속성에 응답한다.
2가지 항목 중 첫번째 항목인 준비 상태에 관해선 다음 글에서 대부분 다룰 것이다. 그 때는 HTTP Request 단계에 대해 알고 싶은 것 이상으로 배우게 된다. 지금 현재로선, xmlHttp.responseText 속성 값 4를 단순 점검하는 경우, 작업이 계속 진행된다.(다음 글에서 기대할 만한 사항이 나오게 된다.) 서버 응답을 얻기 위해 xmlHttp.readyState 속성을 사용하는 과정인 두 번째 항목은 쉽다. Listing 6은 Listing 5에서 전송된 값에 근거해 서버에서 호출하는 방법에 관한 예를 보여준다.
Listing 6. 서버 응답 취급하기
function updatePage() {
if (xmlHttp.readyState == 4) {
var response = xmlHttp.responseText;
document.getElementById("zipCode").value = response;
}
}
다시 보면, xmlHttp.readyState 코드는 그리 어렵거나 복잡하지 않다. 이 코드는 서버에서 해당 준비 상태로의 호출을 대기하고 서버에서 다시 복귀되는 값(이 경우, 사용자 기입 도시 및 국가에 대한 ZIP 코드)을 사용해 또 다른 형태의 양식 필드를 설정한다. 그 결과, zipCode 필드는 ZIP 코드와 함께 갑자기 나타난다. 하지만 사용자는 버튼을 클릭해서는 안 된다! 그게 바로 이전에 말했던 데스크톱 애플리케이션이다. Ajax 코드에는 응답성, 동적 상태 외의 더 많은 것이 있다. 독자들은 zipCode가 정상 텍스트 필드라는 것을 눈치챘을지도 모른다.
일단 서버에서 zipCode를 복귀시키고 updatePage() 방식으로 도시/국가 ZIP 코드와 함께 zipCode 필드 값을 설정하는 경우 사용자는 값을 무효로 한다. 값을 무효로 하는 데는 두 가지 이유가 있다. 예에서 나오는 상황을 단순화시키고, 때로는 사용자가 서버에서 명령하는 것을 무효로 하기 위해서다. 이 두 가지를 명심하라. 좋은 사용자-인터페이스 설계를 위해 중요하다.
웹 양식 다루기
그러면 이 글에서 다룰 게 남아 있는가? 그다지 많지 않다. 양식에 기입할 정보를 포착해 이를 서버에 전송하고 응답에 관해 취급할 또 다른 JavaScript 방법을 제공하면서 심지어는 다시 응답될 때 필드 값을 설정하기까지 하는 JavaScript 방법을 다룬다. 여기서는 첫번째 JavaScript 방법을 호출해 전 과정을 시작하기만 하면 된다. 분명 HTTL 양식에 버튼을 추가하지만 2001년 버전과 거의 동일하다고 생각되지 않는가? Listing 7과 같이 JavaScript 기술을 활용한다.
Listing 7. Ajax 프로세스 시작
<form>
<p>City: <input type="text" name="city" id="city" size="25"
onChange="callServer();" /></p>
<p>State: <input type="text" name="state" id="state" size="25"
onChange="callServer();" /></p>
<p>Zip Code: <input type="text" name="zipCode" id="zipCode" size="5" /></p>
</form>
이런 단면이 루틴 코드의 한 단면 이상을 보여준다고 생각된다면 맞는 말이다. ? 그렇다! 사용자가 도시/국가 필드에 관한 새로운 값을 입력할 경우 callServer() 방식을 전송한 다음 Ajax 애플리케이션이 시작된다. 이제 여러 상황을 다룰 만하다고 느껴지기 시작하는가? 좋다! 바로 그거다!
맺음말
이 시점에서 적어도 리소스 란에서 Ajax 애플리케이션에 관해 깊숙이 알려고 하는 경우, 첫번째 Ajax 애플리케이션을 작성할 준비가 되어 있지 않을 게다. 하지만 이런 애플리케이션이 작동하는 기본 개념 및 XMLHttpRequest 객체의 기본 개념을 이해하기 시작한 경우 이 객체, JavaScript-서버 간 대화 취급방식, HTML 양식 취급 및 심지어 DOM 관리 방식까지 모든 것을 배워야 한다.
지금 현재로선, Ajax 애플리케이션이 얼마나 강력한 툴인지 생각하는 데 시간을 보낸다. 버튼만 클릭할 뿐만 아니라 필드에 입력하고 콤보 상자에서 옵션을 선택하고 심지어는 마우스를 스크린 주위에 끄는 경우 응답하는 웹 형식을 상상해 본다. 비동기식의 정확한 의미 및 Request 상에서 응답하기 위해 서버 상에서 실행하지만 대기하지 않는 JavaScript 코드에 관해 생각해 본다. 여러분이 부딪치는 문제의 종류는 어떤 것인가? 어떤 영역의 문제에 주의를 기울일 것인가? 프로그래밍에 이 새로운 접근방식을 설명하기 위해 양식 설계를 변환하는 방법은 어떤 것인가?
이런 문제에 관해 실지로 생각할 시간을 보낸다면 잘라 붙이는 코드를 가지고 이를 잘 이해하지 못하는 애플리케이션에 포함시키는 것보다는 훨씬 더 낫다. 다음 글에서는 이와 같은 개념을 실제 작업에 응용해 본 작업에서처럼 애플리케이션을 만들어야 하는 코드에 관한 자세한 정보를 제공하기로 한다. 그 때까지 Ajax 애플리케이션의 가능성을 마음껏 즐겨라.
참고자료
교육
- Adaptive Path
- Jesse James Garrett, Ajax.
- XMLHttpRequest object.
- Microsoft Developer Network's XML Developer Center.
- 자바 개발자를 위한 Ajax: 동적 자바 애플리케이션 구현 (developerWorks, September 2005)
- 자바 개발자를 위한 Ajax: Ajax용 자바 객체 직렬화 (developerWorks, October 2005)
- Using Ajax with PHP and Sajax (developerWorks, October 2005)
- Call SOAP Web services with AJAX, Part 1: Build the Web services client (developerWorks, October 2005)
- XML Matters: Beyond the DOM (developerWorks, May 2005)
- Build apps with Asynchronous JavaScript with XML, or AJAX (developerWorks, November 2005)
- Ajax for Java developers: Ajax with Direct Web Remoting (developerWorks, November 2005)
- surveys AJAX/JavaScript libraries.
- XUL Planet's object reference section details XMLHttpRequest
- strategy white paper
- Flickr.com.
- GMail
- Head Rush Ajax (O'Reilly Media, Inc., February 2006)
- JavaScript: The Definitive Guide, 4th Edition (O'Reilly Media, Inc., November 2001)
- developerWorks Web Architecture zone
토론
-포럼에 참여하기.
-Ajax.NET Professional
-developerWorks blogs.

Brett McLaughlin, Author and Editor | O'Reilly Media Inc.

원문 :http://www.dbguide.net/know/know102001.jsp?mode=view&divcateno=14&divcateno_=14&pg=1&idx=3052
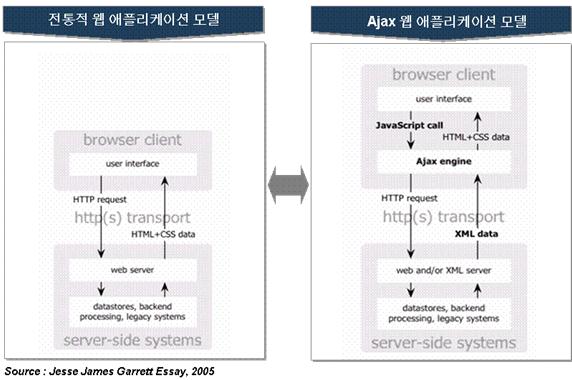
대부분의 웹 애플리케이션들은 서버에서 전체 HTML 페이지를 얻는 요청/응답 모델을 사용합니다. 다시 말해서, 이 모델은 버튼을 클릭하고, 서버를 기다리고, 또 다른 버튼을 클릭하고, 다시 기다리는 일이 다반사입니다. Ajax와 XMLHttpRequest 객체를 사용하면 서버 응답을 기다리지 않아도 되는 요청/응답 모델을 사용할 수 있습니다.
지난 글(참고자료)에서는 Ajax 애플리케이션에 관한 서론 및 이 애플리케이션에 필요한 몇 가지 기본개념에 대해 알아봤다. 본 글에서는 JavaScript, HTML 및 XHTML, 동적 HTML, 심지어는 몇 가지 DOM(동적 객체 모델) 등 이미 알고 있는 수많은 기술에 대해 중점적으로 다뤘다.
본 글에서는 모든 Ajax관련 객체 및 프로그래밍 방식의 기초인 XMLHttpRequest 객체에 대해 먼저 다룰 것이다. 이 객체는 모든 Ajax 애플리케이션 전반에 걸쳐 유일한 공통 줄기가 된다. 예상하다시피, XMLHttpRequest 객체를 완전히 이해해서 프로그래밍의 한계에 다다르고자 할 것이다. 사실, XMLHttpRequest 객체를 적절히 이용해도 분명 그 객체를 사용하지 못하는 경우가 있다. 도대체 XMLHttpRequest 객체는 무엇일까?
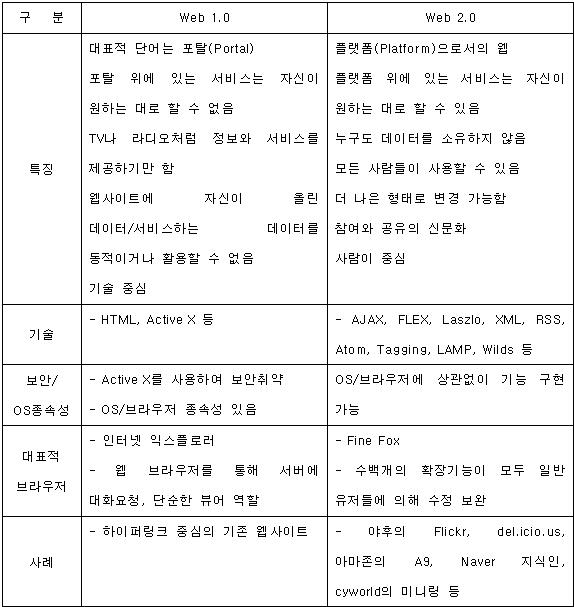
Web 2.0
먼저 코드에 관해 자세히 알아보기 전에 Web 2.0에 관한 개요를 살펴 보면서 확실한 개념을 얻도록 하자. Web 2.0이라는 용어를 들을 때 다음과 같이 " Web 1.0은 무엇입니까?" 라고 물어봐야 한다. Web 1.0에 대해선 거의 들어보지 못했지만 명료한 요청 및 응답 모델이 포함된 전통 웹을 가리켜 Web 1.0이라 한다. 예를 들어 Amazon.com으로 들어가서 버튼을 클릭하거나 탐색 용어를 입력하면 서버에 요청을 생성하고 이에 대한 응답이 브라우저로 다시 보낸다. 그 요청은 책, 타이틀 목록 이상으로 중요하며 실지로 또 다른 완전 HTML 페이지를 만들어낸다. 그 결과 새로운 HTML 페이지가 웹 브라우저 스크린에 다시 나타날 때 플래시/플리커링 현상이 나타나기도 한다. 사실, 각각의 새로운 페이지에서 나오는 요청, 응답을 분명히 알게 된다.
Web 2.0은 이와 같은 왕복이동 움직임이 상당부분 필요 없다. 예를 들어, Google Maps 또는 Flickr(참고자료)를 방문하면 Google Maps 상에서는 맵을 끌어다가 재 드로잉을 약간만 해도 맵이 축소, 확대된다. 물론, 요청 및 응답은 상상을 초월할 정도로 계속 이루어진다. 이로 인해 사용자로서의 경험은 훨씬 짜릿하며 데스크톱 애플리케이션 상에 있는 것과 같이 느껴진다. 이런 새로운 느낌, 패러다임은 누군가가 Web 2.0에 대해 언급할 때 나오는 현상들이다.
이와 같이 새로운 상호작용이 가능하도록 하는 방법에 대해 주의를 기울여야 한다. 분명 요청 및 필드 응답을 생성하지만 이로 인해 매 순간 요청/응답 상호작용에 관한 HTML 재 드로잉이 발생돼 느리고 볼품없는 웹 인터페이스를 생성하게 된다. 따라서 사용자가 요청을 생성하고 전반적인 HTML 페이지보다는 필요한 데이터만 포함하는 응답을 수신하는 방식이 필요하다. 사용자가 새로운 페이지를 보고자 할 때가 완전히 새로운 HTML을 얻는 유일한 경우다.
하지만 대부분의 상호작용으로 인해 상세사항 추가/본문 텍스트 변환/기존 페이지에 데이터 겹쳐쓰기 등이 발생한다. 모든 경우, Ajax 및 Web 2.0방식으로 전체 HTML 페이지를 업데이트하지 않고 데이터를 전송, 수신한다. 이런 기능으로 임의의 수많은 웹 서퍼들은 애플리케이션의 속도가 빨라지고 응답성이 증가하는 것으로 느끼게 되며 상호작용이 반복적으로 이루어지게 된다.
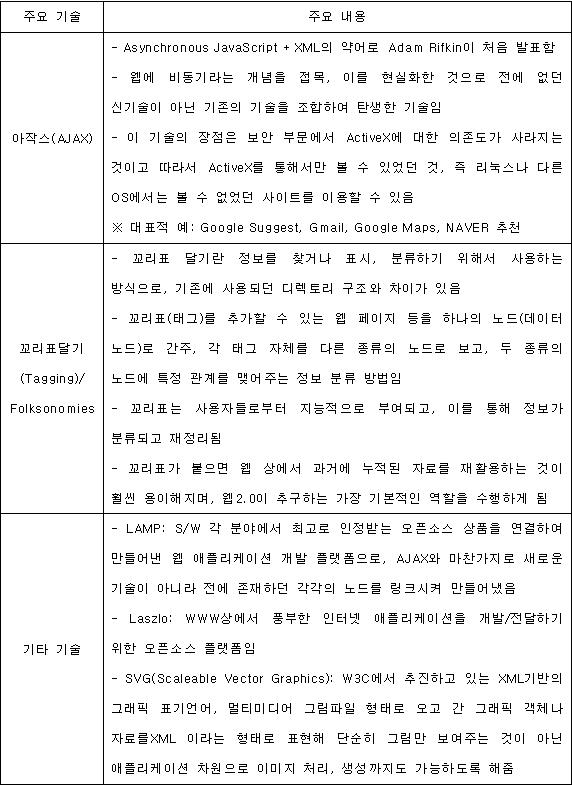
XMLHttpRequest
이렇게 새롭고 놀라운 현상이 실지로 발생하기 위해선 XMLHttpRequest라 하는 JavaScript 객체에 관해 완전 익숙해져야 한다. 오랜 시간 동안 몇몇 브라우저에서 사용된 이 객체는 Web 2.0, Ajax 및 앞으로 이 글에서 배우게 될 기타 사항을 이해하는 데 있어 중요한 역할을 하게 된다. 실지로 빠른 이해를 위해 이 객체에서 사용되는 방법 및 속성에 대해 알아보자.
open(): 새로운 요청을 서버에 설정함.
send(): 요청을 서버에 전송함.
abort(): 현 요청에서 벗어남.
readyState: 현 HTML 준비상태를 제공함.
responseText: 요청에 응답하기 위해 서버에서 재전송하는 텍스트.
위의 모든 명령을 다 이해하지 못하더라도(중요한 것을 이해하지 못한다 하더라도) 걱정하지 마라. 다음 글에서 각 명령에 대한 방법 및 속성에 관해 배우게 된다. 여기서는 XMLHttpRequest와 관련된 좋은 아이디어를 얻는 게 필요하다.여기서, 각 방법 및 속성은 요청 전송 및 응답 처리와 연관된다는 것을 명심하라. 사실, XMLHttpRequest 객체에 관한 방법, 속성을 다는 알지 못하기 때문에 이들이 매우 간단한 요청/응답 모델과 연관 있다는 것도 모르게 된다. 그래서 놀랍고도 새로운 GUI 객체, 또는 사용자 상호작용을 생성하는 흥미로운 몇 가지 방식 등에 관해서도 배우지 않는다. 별로 재미가 없는 것 같지만 XMLHttpRequest 객체 하나만 잘 사용해도 완전 애플리케이션을 변경할 수 있다.
단순함
우선, 새로운 변수를 생성한 다음 이를 XMLHttpRequest객체 인스턴스에 할당한다. JavaScript 상에서는 상당히 간단한 작업이다. 여기서 Listing 1에 보다시피, 객체 이름과 같이 new 키워드를 사용하면 된다.
Listing 1. 새로운 XMLHttpRequest 객체 형성
<script language="javascript" type="text/javascript">
var request = new XMLHttpRequest();
</script>
새로운 객체 형성과정이 그다지 어려운 일은 아니지 않는가? JavaScript에서는 변수 상에 입력하는 과정이 필요 없어 Listing 2(자바에서 XMLHttpRequest 객체를 생성하는 과정)와 같이 값을 전혀 입력할 필요가 없다.
Listing 2. XMLHttpRequest 객체를 생성하기 위한 자바 유사-코드
XMLHttpRequest request = new XMLHttpRequest();
따라서 JavaScript에서 var로 변수를 생성해 변수에 명칭("request" 등)을 부여한 다음 이를 XMLHttpRequest 객체의 새로운 인스턴스에 할당한다. 이 시점에서 XMLHttpRequest 객체를 사용할 준비가 된 것이다.
에러 처리과정
실제 세계에서, 에러가 발생할 수 있어 에러 발생코드는 에러 처리기능을 제공하지 않는다. 따라서 XMLHttpRequest를 생성한 다음 에러가 발생한 경우 이 객체의 기능을 점차 저하시킨다. 일례로, XMLHttpRequest객체를 지원하지 않는 구 브라우저들(믿건 말건, 사람들은 Netscape Navigator의 구 버전을 여전히 이용한다.)이 많아 사용자는 어디서 에러가 났는지 알 필요가 있다. Listing 3은 에러가 난 경우 XMLHttpRequest 객체를 생성하는 방식에 대해 나와 있다. 여기서 XMLHttpRequest 객체로 JavaScript 경고가 발생한다.
Listing 3. 에러 처리기능으로 XMLHttpRequest 객체 생성
<script language="javascript" type="text/javascript">
var request = false;
try {
request = new XMLHttpRequest();
} catch (failed) {
request = false;
}
if (!request)
alert("Error initializing XMLHttpRequest!");
</script>
여기서 다음의 각 단계를 반드시 이해한다.
1.request라는 새 변수를 생성한 다음 이를 거짓으로 설정한다. XMLHttpRequest 객체가 아직 생성되지 않은 상태에서 거짓 값으로 설정한다.
2. try/catch 블록에서 추가로 다음과 같은 작업을 한다.
- XMLHttpRequest 객체를 시험한 다음 생성한다.
- 1번 과정이 실패한 경우(catch (failed)), request가 여전히 거짓으로 설정되어 있는지 확인한다.
3. request가 여전히 거짓으로 설정되어 있는지 확인한다. (에러가 없는 경우, 거짓으로 설정되지 않는다.)
4. 에러가 발생한 경우(request가 거짓인 경우), JavaScript 경고를 사용해 문제가 발생했다는 사실을 사용자에게 알린다.
이런 작업은 상당히 간단하다. 실제로 대부분의 JavaScript 및 웹 개발자들은 객체를 읽고 작성하는 것보다는 이해하는 게 더 빠르다. 이제, XMLHttpRequest 객체를 생성하는 일부 에러-증명 코드가 생성되어 에러 여부를 알게 된다.
Microsoft로 처리하기
적어도 인터넷 상에서 이 코드를 적용하기 전까지는 이와 같은 작업이 무난하다. 이 코드를 적용하면 그림 1과 같이 에러가 나오게 된다.
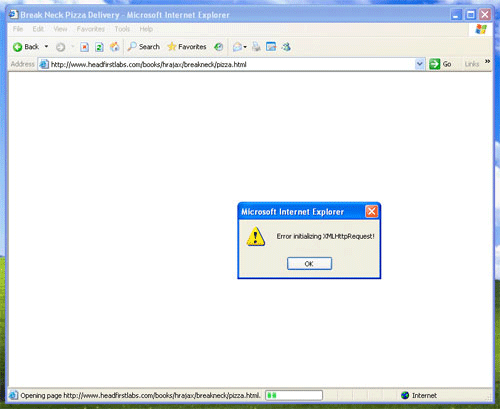
그림1. 에러화면
분명, 에러가 발생하고 있다. Internet Explorer는 구식 브라우저가 아니며, 전 세계의 70% 정도가 사용하는 툴이다. 즉, Microsoft 및 Internet Explorer를 지원하지 않는 한 웹 상에서 잘 운영하지 못하게 된다. 따라서 Microsoft 브라우저를 다룰 다른 방식이 필요하다.
Microsoft는 Ajax를 지원하지만 이전과 다른 XMLHttpRequest 버전을 호출하며 사실은 여러 다른 버전을 호출한다. Internet Explorer의 새로운 버전을 사용하는 경우, Msxml2.XMLHTTP 라 하는 객체를 사용해야 한다. Internet Explorer의 구 버전에서는 Microsoft.XMLHTTP 객체를 사용한다. 그러므로 이와 같은 두 가지 객체 형태를 지원해야 한다. (비-Microsoft 브라우저에 대한 지원기능을 손실하지 않은 상태에서.) 이미 언급한 코드에 Microsoft 지원기능을 추가한 Listing 4를 참조하라.
Microsoft가 잘 작동되는가?
Ajax에 관해 쓴 글이 많고 Microsoft는 이 영역에 있어 점점 더 관심을 기울이고 있다. 사실 2006년 말에 출시될 것으로 예정된 Microsoft사의 Internet Explorer 최신버전인 버전 7.0은 XMLHttpRequest 객체를 직접 지원해 모든 Msxml2.XMLHTTP 생성코드 대신 new 키워드를 사용한다. 하지만 너무 빠져 들지 마라. 아직도 구 브라우저를 지원해야 하므로 크로스-브라우저 코드는 곧장 사라지지는 않을 전망이다.
Listing 4. Microsoft 브라우저에 지원기능 추가
<script language="javascript" type="text/javascript">
var request = false;
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}
}
}
if (!request)
alert("Error initializing XMLHttpRequest!");
</script>
사실 브라우저에 대한 지원기능이 손실되기 쉽다. 따라서 다음과 같이 단계별로 하길 권한다.
1. request 명의 새 변수를 생성한 다음 이를 거짓으로 설정한다. XMLHttpRequest 객체가 아직 생성되지 않았다는 전제 하에 거짓으로 설정한다.
2. try/catch 블록에서 추가로 다음과 같은 작업을 한다.
- XMLHttpRequest 객체를 시험한 다음 생성한다.
- 1번 과정이 실패한 경우 (catch (trymicrosoft)):
- 새로운 Microsoft 버전 (Msxml2.XMLHTTP)을 이용해 Microsoft 호환성 객체를 시험한 다음 생성한다.
- 전 과정이 실패한 경우(catch (othermicrosoft)), 이전 Microsoft 버전(Microsoft.XMLHTTP)을 이용해 Microsoft 호환성 객체를 시험한 다음 생성한다.
- 그래도 실패한 경우(catch (failed))에는, request가 여전히 거짓으로 설정되어 있는지 확인한다.
3. request가 여전히 거짓으로 설정되어 있는지 다시 확인한다. (에러가 나지 않는 경우 거짓으로 설정되지 않는다.)
4. 그래도 문제가 발생한 경우(request가 거짓인 경우), JavaScript 경고를 사용해 사용자에게 문제가 발생했다는 것을 알린다.
코드를 변화시키고 Internet Explorer 상에서 다시 한 번 시도해 보면 에러 메시지 없이 생성한 형태를 보게 된다. 본인의 경우엔 그와 같은 시도가 그림 2와 같은 것으로 나타난다
그림 2. 정상적으로 작동하는 Internet Explorer
동적/정적
Listing 1, 3, 4를 다시 보면 모든 코드는 script 태그 내에 직접 포함되어 있다는 것을 알게 된다. JavaScript가 그와 같이 코드화되고 메소드/기능 본체 내에 들어가지 않은 경우, 이를 정적 JavaScript라 한다. 이는 페이지가 스크린 상에 나타나기 전 코드를 실행했다는 것을 의미한다.(코드 및 브라우저가 따로 실행될 경우, 사양과는 100% 일치하지 않지만 사용자와 페이지가 상호작용하기 전, 코드를 실행했다는 건 확실하다.) 일반적으로 그렇게 해서 대부분의 Ajax 프로그래머가 XMLHttpRequest 객체를 생성한다.
즉, Listing 5처럼, 메소드에 이와 같은 코드를 첨가한다.
Listing 5. XMLHttpRequest 생성코드를 메소드로 이동하기
<script language="javascript" type="text/javascript">
var request;
function createRequest() {
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}
}
}
if (!request)
alert("Error initializing XMLHttpRequest!");
}
</script>
이와 같이 코드를 설정하면, Ajax 작업을 하기 전 이와 같은 메소드를 호출해야 한다. 그럴 경우 Listing 6과 같은 것을 얻을 수도 있다.
Listing 6. XMLHttpRequest 생성 메소드 사용
<script language="javascript" type="text/javascript">
var request;
function createRequest() {
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}
}
}
if (!request)
alert("Error initializing XMLHttpRequest!");
}
function getCustomerInfo() {
createRequest();
// Do something with the request variable
}
</script>
Listing 6을 활용하면 에러 통지기능을 지연시키므로 대부분의 Ajax 프로그래머들은 위의 방법을 활용하지 않는다. 10/15 필드가 있는 복잡한 형태에 선택상자 등등이 있다고 상상해 보면 사용자가 필드 14에 있는 텍스트를 형식에 나온 대로 기입할 때 몇 가지 Ajax 코드를 전송한다. 이 시점에서 getCustomerInfo()를 실행해 XMLHttpRequest 객체를 생성하려 했지만 실패한다. (이 예에서) 그러면 사용자에게 이 애플리케이션을 사용할 수 없다는 것을 경고로 알리게 된다 (많은 경우). 하지만 사용자는 이미 형식 상에서 데이터를 기입하느라 시간을 보냈다. 상당히 짜증을 내게 되면서 사용자는 결국엔 사이트로 관심을 기울이지 않게 된다.
정적 JavaScript를 사용하는 경우, 사용자는 페이지에 에러가 나자마자 에러를 포착하게 된다. 또 짜증나는가? 아마도 사용자로선 웹 애플리케이션이 브라우저 상에서 작동되지 않을 때 상당히 죽을 맛일 게다. 하지만, 10분 동안 정보를 기입한 뒤 동일한 에러가 나오는 것보다는 확실히 낫다. 따라서 정적으로 코드를 설정하고 난 다음 발생할 수 있는 문제에 대해 사용자가 조기에 알도록 하는 게 중요하다고 본다.
XMLHttpRequest로 요청 전송하기
요청 객체가 있으면 요청/응답 사이클을 시작한다. 여기서 요청을 생성한 다음 응답을 수신하는 게 XMLHttpRequest 객체에서 이루고자 하는 유일한 것임을 명심하라. 사용자 인터페이스 변환, 이미지 교환 및 서버에서 재전송하는 데이터 해석 등의 작업은 페이지에 있는 JavaScript, CSS 또는 기타 코드에서 일어나는 현상이다. XMLHttpRequest 객체가 사용 대기 중일 때 서버에 요청을 생성하게 된다.
샌드박스
Ajax는 샌드박스 보안 모델이 포함되어 있다. 그 결과 Ajax 코드(특히 XMLHttpRequest 객체)는 실행 중인 동일한 도메인에만 요청을 생성한다. 다음 글에서 보안 및 Ajax에 관해 더 많은 것을 배우게 되겠지만 지금으로선 로컬 머신 상에서 작동하는 코드만으로도 로컬 머신 상의 서버측 스크립트에 요청을 생성한다는 것을 알게 된다. www.breakneckpizza.com상에서 Ajax 코드를 실행하는 경우, www.breakneckpizza.com상에서 실행하는 스크립트에 관한 요청을 생성한다.
서버 URL 설정
여기서 우선 결정할 것은 연결할 서버의 URL이다. URL은 Ajax에서만 있는 것은 아니다. 분명URL을 구성하는 방법에 대해 알아야 한다. 하지만 URL은 연결 설정 시 여전히 필수적인 것이다. 대부분의 애플리케이션에서 사용자가 다루는 형식에서 나온 데이터와 정적 데이터 세트를 결합해 URL을 구성한다. 예를 들어 Listing 7에서는 전화번호 필드의 값을 알아내고 그 데이터를 이용해 URL을 구성하는 JavaScript에 관해 나와 있다.
Listing 7. 요청 URL 구축
<script language="javascript" type="text/javascript">
var request = false;
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}
}
}
if (!request)
alert("Error initializing XMLHttpRequest!");
function getCustomerInfo() {
var phone = document.getElementById("phone").value;
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
}
</script>
여기서 딴지를 걸만한 게 없다. 먼저 여기 나온 코드는 phone 이라는 이름의 새로운 변수를 생성, 이를 "phone"의 ID로 형식 필드 값을 지정한다. Listing 8에는 phone 필드 및 id 속성에서 알 수 있는 특수 형태에 관한 XHTML에 관해 나와 있다.
Listing 8. Break Neck Pizza 형식
<body>
<p><img src="breakneck-logo_4c.gif" alt="Break Neck Pizza" /></p>
<form action="POST">
<p>Enter your phone number:
<input type="text" size="14" name="phone" id="phone"
onChange="getCustomerInfo();" />
</p>
<p>Your order will be delivered to:</p>
<div id="address"></div>
<p>Type your order in here:</p>
<p><textarea name="order" rows="6" cols="50" id="order"></textarea></p>
<p><input type="submit" value="Order Pizza" id="submit" /></p>
</form>
</body>
사용자가 전화번호를 입력/변경하는 경우, Listing 8에서 보는 대로 getCustomerInfo() 메소드가 나온다는 사실을 알아둔다. 이 방법으로 전화번호를 알아낸 다음 url 변수에 저장된 URL 문자열을 구성하는 데 활용한다. Ajax 코드는 묶여져 있고 동일한 도메인에만 연결되기 때문에 URL에서 도메인 명칭이 필요 없다는 사실을 명심해야 한다. 이 예에서 스크립트 명칭은 /cgi-local/lookupCustomer.php다. 결국 전화 번호는 상기 스트립트에 Get 매개변수로서 추가된다. ("phone=" + escape(phone))
이전에 escape() 메소드를 알지 못한 경우, 이 메소드는 정확히 명백한 텍스트로 전송될 수 없는 문자로부터 벗어나는 데 사용된다. 예를 들어, 전화번호에서의 임의의 공간은 %20 문자로 바뀌며 이로 인해 URL과 같이 문자를 전송할 수 있게 된다.
그런 다음 필요한 많은 매개변수를 추가한다. 예를 들어 또 다른 매개변수를 추가하고자 한다면 URL 상에 추가해 여러 매개변수를 ampersand(&) 문자로 분리시킨다. (첫 번째 매개변수는 의문부호(?)로 스크립트 명칭으로부터 분리되어 있다.)
요청 열기
URL이 연결된 상태에서 XMLHttpRequest 객체 상의 open() 메소드를 사용해 요청을 구성한다. 이 메소드는 5가지 매개변수가 있다.
request-type: 전송 요청 형태. GET/POST가 일반적인 값이고 HEAD 요청도 전송함.
url: 연결된 URL.
asynch: 비동기 요청을 설정할 경우 참값, 동기식 요청인 경우에는 거짓임. 이 매개변수는 옵션이고 기본값이 참값임.
username: 사용인증을 요구할 경우 사용자이름을 지정한다. 옵션 매개변수고 기본값이 없다.
password: 사용인증을 요구할 경우 암호를 지정한다, 옵션 매개변수고 기본값이 없다.
일반적으로 5개의 매개변수 중 3개의 첫 매개변수만 사용한다. 사실, 비동기식 요청을 원할 경우, 제3의 매개변수로 "true"을 설정한다. 그게 기본값 설정이다. 하지만 훌륭한 자체 문서화 작업으로 이 작업을 통해 항상 요청이 비동기식인지 아닌지 여부를 알 수 있다.
기본값 설정을 완료한 다음 일반적으로 Listing 9와 비슷한 라인으로 작업을 완료한다.
open() 메소드가 열릴까?
인터넷 개발자들은 open() 메소드의 정확한 기능에 대해 서로 의견이 다르다. 실제로 이 메소드에 없는 기능은 요청 열기 기능이다. 네트워크 및 XHYML/Ajax 페이지와 연결 스크립트 간 데이터 이동을 감시했더라면 open() 메소드 호출 시 트래픽 현상이 발생하지도 않았을 것이다. Open() 명칭이 선택된 이유는 여전히 불분명하지만 분명 훌륭한 명칭선택이라 볼 수는 없다.
Listing 9. 요청 열기
function getCustomerInfo() {
var phone = document.getElementById("phone").value;
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
request.open("GET", url, true);
}
일단 URL을 이해했으면 그 다음에는 상당히 단순하다. 대부분의 요청의 경우, GET을 사용하는 것만으로도 충분하다. (다음 글에서 POST를 사용하고자 하는 경우를 보게 된다.) URL과 같이 open() 메소드를 사용하기만 하면 된다.
비동시성에 대한 문제
이 시리즈의 후반부에서는 비동기식 코드 작성 및 사용에 관한 설명에 할애할 것이다. 하지만 open() 메소드에서 마지막 매개변수가 중요한 이유에 대해 알아야 한다. 정상 요청/응답 모델에서 Web 1.0,을 생각해 보면 클라이언트(로컬 머신 상에서 실행하는 브라우저/코드)는 서버에 요청을 생성한다. 그 요청은 동기식이다. 다시 말하면 클라이언트는 서버로부터의 응답이 올 때까지 대기한다. 클라이언트가 대기 중일 때 일반적으로 적어도 대기 중인 여러 통지 형태 중 하나만 얻으면 된다.
Hourglass (Windows 경우에만).
회전 비치볼(일반적으로 Mac 머신에서의 경우임).
애플리케이션은 기본적으로 정지되고 때로 커서가 변환되기도 한다.
이런 특성으로 웹 애플리케이션은 볼품없거나 느린 것으로 보여진다. 즉 실제 대화성이 부족한 것이다. 버튼을 누르면 트리거된 요청이 응답되기 전까지는 애플리케이션을 사용할 수 없다. 광범위한 서버 처리작업을 요구하는 요청을 생성할 경우 대기시간은 어마어마할 것이다. (적어도 오늘날 멀티 프로세서, DSL, 비대기 세계의 경우처럼.)
하지만 비동기식 요청은 서버가 응답할 때까지 대기하지 않는다. 요청을 전송한 다음에는 애플리케이션을 계속 실행한다. 사용자는 웹 형식에서 데이터를 기입한 다음 기타 버튼을 클릭하고 형식 기입을 종료한다. 회전하는 비치볼, 소용돌이치는 hourglass 및 대형 애플리케이션 정지 등의 현상이 생기지 않는다. 서버는 재빨리 요청에 응답하고 서버가 종료된 경우, 요청으로 인해 원 요청자는 서버가 종료되었음을 알게 된다. 결국 볼품없고 느린 대신 민감하고 대화성 있고 빠른 애플리케이션을 얻게 된다. 정확한 GUI 구성요소 및 웹 디자인 패러다임만 가지고는 느리고 동기적인 요청/응답 모델의 한계를 극복할 수 없다.
요청 전송
일단 open() 메소드로 요청을 구성하고 나면 요청 전송 준비를 한다. 다행히도, 요청을 전송하는 메소드를 open()의 경우에 비해 더 적절하게 명명한다. 명칭은 단순히 send()이다.
send() 메소드는 단 하나의 매개변수인 전송 컨텐트만 있으면 된다. 그 메소드에 대해 너무 깊게 생각하기 이전에 이미 URL 자체를 통해 데이터를 전송했음을 기억하라.
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
send() 메소드를 사용해 데이터를 전송하지만 URL자체를 통해서도 된다. 사실, GET 요청(일반 Ajax 이용률의 80%를 이루고 있음.)에서는 URL에서 데이터를 전송하는 게 더 용이하다. 안전한 정보/XML을 전송하기 시작한 경우, send() 메소드를 통한 전송 컨텐트에 대해 알아보려고 할 것이다. (이 시리즈 후반부에 안전한 데이터 및 XML 메시징에 대해 논의한다.) send()를 통해 데이터를 전송하지 않아도 되는 경우, 이 메소드에 대한 인수로 null을 전송하면 된다. 따라서 이 글을 통해 알게 된 예에서 보듯 요청 전송작업을 하는 게 필요하다.(Listing 10)
Listing 10. 요청 전송
function getCustomerInfo() {
var phone = document.getElementById("phone").value;
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
request.open("GET", url, true);
request.send(null);
}
콜백 메소드 지정
이 시점에서, 새롭고 혁신적이거나 비동기적이라고 생각될 만한 작업을 거의 하지 못했다. open() 메소드의 키워드 "true"는 비동기식 요청을 설정한다고 하는 게 정확하다. 하지만 그거 말고도 open() 메소드 코드는 Java servlets및 JSP, PHP/Perl이 함께 어우러진 프로그래밍과 유사하다. 그렇다면 Ajax 및 Web 2.0에 담긴 커다란 비밀은 무엇일까? 그 비밀은 onreadystatechange라는 명칭의 XMLHttpRequest의 단순한 속성에서 나오게 된다.
먼저, open() 코드에서 생성된 과정에 대해 확실히 이해한다.(Listing 10) 요청을 설정하고 생성한다. 게다가 이 XMLHttpRequest는 동기식 요청이라 자바 메소드(예에 나온 getCustomerInfo())는 서버 상에서 대기하지 않는다. open() 코드는 계속 진행되고 이 경우 자바 메소드는 정지되며 제어기능은 형태로 나오게 된다. 사용자들은 계속 정보를 입력하고 애플리케이션은 서버 상에서 대기하지 않는다.
이렇게 되면 재미있는 질문이 나오게 된다. 서버가 요청 처리 과정을 완료할 시 발생하는 현상은 어떤 것인가? 적어도 코드가 지금 당장 유지되는 한은 아무 현상도 없다 라는 말이 정답이다. 분명 좋은 현상은 아니다. 따라서 서버에 XXMLHttpRequest객체에 의해 전송된 요청에 관한 처리과정을 완료할 경우 서버는 몇 가지 형태의 명령어를 포함해야 한다
이런 상황에서 바로 onreadystatechange 속성이 작용한다. 이 속성으로 콜백 메소드를 지정한다. 콜백 메소드로 서버는 웹 페이지 코드로 다시 호출한다. 그러면서 서버에 어느 정도의 제어 기능이 전달된다. 또한 서버에서 요청을 종료할 때 콜백 메소드는 XMLHttpRequest 객체, 특히 onreadystatechange 속성에서 나타난다. 그 속성에서 지정된 방법이 어떤 메소드든 모두 호출된다. 웹 페이지 자체에서 벌어지는 현상에 관계없이 웹 페이지로 다시 호출할 때 서버에서 개시하기 때문에 콜백이라 부르는 것이다. 예를 들어, 사용자가 의자에 앉아 키보드를 사용하지 않는 동안 콜백 메소드를 호출하기도 한다. 하지만 사용자가 입력하고 마우스를 움직이고, 화면 이동시키고 버튼을 클릭하는 동안에도 콜백 메소드를 호출하기도 한다. 사용자가 하는 업무는 그다지 중요하지 않다.
이런 상황에서 비동시성이 작용한다. 사용자는 다른 레벨에 있는 동안 한 레벨에 있는 형식을 작동하고 서버는 요청에 응답한 다음 onreadystatechange 속성에서 명시된 콜백 메소드를 전송한다. 따라서 Listing 11에 나온 대로 코드에 콜백 메소드를 지정해야 한다.
JavaScript에서의 기능 참조
JavaScript는 약결합 언어며 이 언어에서 모두 다 변수로 참조 가능하다. updatePage()라는 이름의 함수를 선언한 경우, JavaScript는 그 함수 이름을 변수로 취급한다. 즉 updatePage()라는 이름의 변수로 코드에 있는 함수를 참조한다.
Listing 11. 콜백 메소드 설정
function getCustomerInfo() {
var phone = document.getElementById("phone").value;
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
request.open("GET", url, true);
request.onreadystatechange = updatePage;
request.send(null);
}
특히 onreadystatechange 속성이 결정된 코드 위치에 주의를 기울인다. 그 위치는 바로 send()가 호출되기 전의 위치다. 요청을 전송하기 전 onreadystatechange 속성을 설정해야 한다. 그래야만, 서버에서 요청 응답을 종료할 때 onreadystatechange 속성을 탐지하게 된다. 인제는 이 글의 마지막 부분에서 중점적으로 다룰 updatePage() 코드에 대해 알아보겠다.
서버 응답 처리
요청을 만들면 사용자는 웹 형식에서 여유롭게 작업하며 (서버에서 요청을 처리하는 동안에는) 서버는 요청 처리과정을 완료한다. 서버는 onreadystatechange 속성에서 나타나며 호출방법을 결정한다. 그런 일이 일어나면 비동기식/동기식 애플리케이션 등의 기타 다른 애플리케이션으로 애플리케이션을 생각할 수도 있다. 즉, 서버에 응답하는 특수 액션 작성 메소드를 취할 필요가 없다. 형식을 변환하고, 사용자를 또 다른 URL에 안내하거나 서버에 응답하는 데 필요한 것들을 하면 된다. 이 단락에서 우리는 서버 응답 및 이에 대한 일반조치 및 사용자가 아는 형식의 일부를 자유롭게 변경하는 것에 대해 중점적으로 다루겠다.
콜백 및 Ajax
이미 서버가 종료될 때의 현상을 서버가 인식하는 방법에 대해 이미 알았다. 일단 XMLHttpRequest 객체의 onreadystatechange 속성을 실행함수 이름에 설정한다. 그 다음 서버에서 요청을 처리하면 서버는 자동적으로 그 함수를 호출한다. 또한 콜백 메소드에 있는 임의의 매개변수에 대해 그리 걱정하지 않아도 된다. Listing 12와 같이 단순한 메소드에서 시작하기 때문이다.
Listing 12. 콜백 메소드 코드화
<script language="javascript" type="text/javascript">
var request = false;
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}
}
}
if (!request)
alert("Error initializing XMLHttpRequest!");
function getCustomerInfo() {
var phone = document.getElementById("phone").value;
var url = "/cgi-local/lookupCustomer.php?phone=" + escape(phone);
request.open("GET", url, true);
request.onreadystatechange = updatePage;
request.send(null);
}
function updatePage() {
alert("Server is done!");
}
</script>
이렇게 하면 간단한 경고가 울리면서 서버가 종료될 때를 알려준다. 자체 페이지에 updatePage() 코드를 시험하고 페이지를 저장한 다음 브라우저에 페이지를 끌어올린다.(이 예에서 XHTML을 원할 경우, Listing 8을 참조한다.) 전화번호를 입력하고 필드를 설정하지 않을 경우 경고는 팝업되어야 한다. 하지만 확인을 클릭한 경우에도 경고는 팝업을 연속한다.
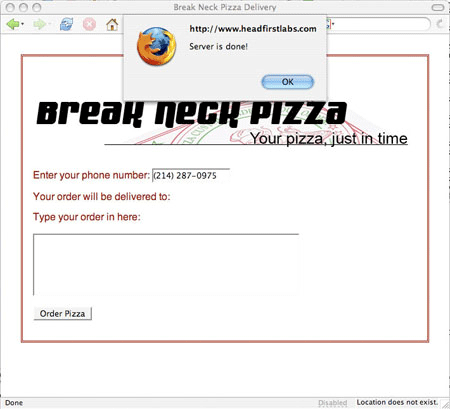
그림 3. 경고를 팝업하는 Ajax 코드
브라우저에 ‘따라 웹 형식에서 경고 팝업을 중지할 때까지 경고가 두 번, 세 번, 심지어는 네 번까지 울린다. 그러면 무슨 일이 벌어지고 있는 것인가? 요청/응답 사이클의 중요 구성요소인 HTTP 준비상태에 대해 고려하지 않았다.
HTTP 준비 상태
초기에 필자는 서버에서 요청이 종료되면 XMLHttpRequest의 onreadystatechange 속성에서 호출되는 메소드를 탐지한다고 가르쳤다. 사실, HTTP 준비 상태가 변할 때마다 서버에서는 방금 전에 언급한 메소드를 호출한다. 그러면 그 말이 의미하는 것은 무엇인가? 일단 먼저 HTTP 준비상태에 관해 이해해야 한다.
HTTP 준비상태는 요청의 상태를 나타내며 주로 요청을 시작했는지, 요청에 응답했는지, 요청/응답 모델을 완성했는지 여부를 결정하는 데 활용된다. HTTP 준비상태는 서버에서 공급되는 모든 응답 텍스트/데이터를 읽어 들이는 데 안전한지 여부를 결정하는 데 도움이 되기도 한다. 여기서 Ajax 애플리케이션에서의 5가지 준비상태에 관해 알아야 한다.
0: 요청이 개시되지 않음.(open()을 호출하기 전)
1: 요청을 설정했지만 전송되지는 않았음.(send()를 호출하기 전)
2: 요청을 설정한 다음 처리 중(이 시점에서 일반적으로 응답에서 나온 컨텐트 헤더를 얻는다.)
3: 요청 처리 중; 종종 응답에서 부분적인 데이터를 사용할 수 있다. 하지만 서버는 자체 응답이 완료되지 않았다.
4: 응답 완료. 서버 응답을 얻은 다음 이를 활용한다.
거의 모든 크로스-브라우저 이슈에서도 그렇듯 예상치 못한 방식으로 이와 같은 준비 상태를 이용한다. 준비상태는 항상 0~1, 2, 3, 4로 단계적으로 이동한다고 예상할지도 모른다. 하지만 실지로는 그렇지 않다. 0/1상태를 보고하지 않고 곧바로 2로 건너뛰어 3,4까지 가는 브라우저도 있고 모든 상태를 보고하는 브라우저도 있다. 지난 단락에서 보듯, 서버에서는 몇 번이고 updatePage()코드를 호출하고 호출 때마다 경고 상자가 팝업된다. 그건 여러분이 의도하는 바가 아닐 것이다!
Ajax 프로그래밍의 경우, 직접 다뤄야 할 상태는 오로지 상태 4다. 이는 서버 응답이 완료되었고 응답 데이터를 점검, 사용하는 데 안전하다는 것을 의미한다. 이를 설명하기 위해 콜백 메소드에 나온 첫 번째 라인은 Listing 13에서 나온 바여야 한다.
Listing 13. 준비상태 점검
function updatePage() {
if (request.readyState == 4)
alert("Server is done!");
}
이런 변환으로 서버가 정말로 그 과정을 종료했는지 확인한다. Ajax 코드의 이 버전을 실행한다. 그러면 한 번에 경고 메시지만을 얻어야 한다.
HTTP 상태 코드
Listing 13에서의 코드의 성공에도 불구하고 여전히 문제는 상존한다. 그러면 서버가 요청에 응답하고 요청 처리과정을 완료했지만 에러를 보고한 경우는 어찌 되는가? Ajax, JSP, 정규 HTML 형식 또는 기타 형태의 코드로 서버측 코드를 호출 중인 경우에 서버측 코드를 관찰해야 한다는 점을 주목한다. 웹 세계에서는 HTTP 코드로 요청에서 발생할지도 모르는 여러 가지 상황을 다룬다.
예를 들어, URL에 관한 요청을 입력했지만, URL을 부정확하게 입력해 404 에러코드가 나와 페이지가 없어졌다고 해보자. 이 코드는 HTTP 요청을 상태로 수신하는 여러 상태 코드 가운데 하나에 지나지 않는다.(참고자료) 403, 401 코드는 둘 다 안전하거나 금지된 데이터 처리를 의미하는 것으로 역시 공통적이다. 각 경우에 있어 이런 코드들은 완전 응답에서 나오는 코드들이다. 즉, 서버는 요청을 수행하지만(HTTP 준비상태는 4임), 클라이언트가 예상한 데이터가 나오지 않을 수도 있다.
여기서 준비 상태에 덧붙여, HTTP 상태를 점검할 필요가 있다. 단순히 확인을 의미하는 상태코드 200을 탐색하는 중에 있다. 준비상태 4와 상태코드 200인 상태에서 서버 데이터를 처리할 준비가 되어 있고 그 데이터는 반드시 요청된 형태여야 한다. (에러 또는 문제가 있는 정보 단편이 아님.) Listing 14에서 보듯이 콜백 메소드에 또 다른 상태 점검기능을 추가한다.
Listing 14. HTTP 상태 코드 점검
function updatePage() {
if (request.readyState == 4)
if (request.status == 200)
alert("Server is done!");
}
복잡성을 줄이고 더 강력한 에러 처리기능을 추가하려면 기타 상태코드에 관한 점검기능/두 가지 기능을 추가할지도 모른다. Listing 15에 있는 updatePage()의 수정 버전을 점검한다.
Listing 15. 간단한 에러 점검기능 추가
function updatePage() {
if (request.readyState == 4)
if (request.status == 200)
alert("Server is done!");
else if (request.status == 404)
alert("Request URL does not exist");
else
alert("Error: status code is " + request.status);
}
이제 getCustomerInfo()에 있는 URL을 비실제 URL로 변환시킨 다음 일어나는 현상을 보면 요청한 URL은 존재하지 않는다는 의미의 경고가 울린다. 이런 경고 가지고도 모든 에러상태를 거의 처리하지 않는다. 하지만 웹 애플리케이션에서 발생할 수 있는 문제의 80%는 해결하는 단순한 진전이 아닐 수 없다.
응답 텍스트 읽기
인제 요청을 준비상태를 통해 완전히 처리하고, 서버로 정상적인 확인 응답을 상태 코드를 통해 받았으므로 서버에서 재전송되는 데이터를 최종적으로 처리한다. 이 데이터는 XMLHttpRequest객체의 responseText 속성에 저장된다.
포맷/길이에 의한 responseText 속성의 텍스트 모양에 관한 상세사항은 이 장에서는 논하지 않기로 한다. 이렇게 되면 서버는 이 텍스트를 실지로 임의로 설정한다. 예를 들어, 한 스크립트로 콤마-분리 값 및 파이프-분리 값이 나오고 또 다른 파이프-분리 값은 텍스트의 긴 문자열로 나올 수도 있다. 이런 현상은 서버에 따라 다르게 된다.
이 글에서 사용된 예의 경우, 서버는 파이프 기호로 분리된 고객의 마지막 순서 및 주소가 나오게 된다. 형식의 구성요소 값을 설정하는 데 순서 및 고객의 마지막 순서 및 주소를 활용한다. Listing 16은 디스플레이를 업데이트하는 코드에 대해 나와 있다.
Listing 16. 서버 응답 처리
function updatePage() {
if (request.readyState == 4) {
if (request.status == 200) {
var response = request.responseText.split("|");
document.getElementById("order").value = response[0];
document.getElementById("address").innerHTML =
response[1].replace(/\n/g, "");
} else
alert("status is " + request.status);
}
}
우선 JavaScript split() 메소드를 이용해 파이프 기호 상에서 responseText를 얻고 분할한다. 값은 response의 형태로 배열된다. 고객의 마지막 순서에 관한 첫 번째 값은 response[0] 형태의 배열로 처리되고 "순서" ID와 함께 필드 값으로 설정된다. response[1]에서 두 번째 값은 고객 주소로 처리하는 데 좀 더 오랜 시간이 걸린다. 주소 라인은 정상 라인 분리자("\n" 문자) 로 분리되기 때문에 코드는 정상라인 분리자를 XHTML-형 라인 분리자(< br />)로 바꾸어야 한다. 정규 식 및 replace() 함수의 활용을 통해 분리자를 바꾸는 과정이 이루어진다. 결국 변경 텍스트는 HTML 형태에서 div 의 내부 HTML로 설정된다. 결국 그림 4에도 나오듯이 텍스트 형식은 순식간에 고객정보로 업데이트된다.
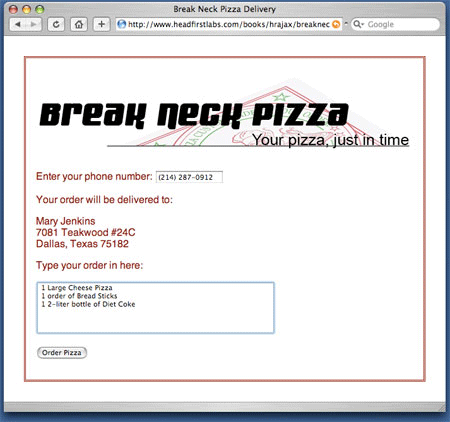
그림 4. 고객 데이터 검색 후의 Break Neck 형식
이 글을 마치기 전에 XMLHttpRequest 객체의 중요한 속성 중 하나인 responseXML 속성에 대해 언급한다. 이 속성은 서버가 XML과의 응답을 선택한 경우, XML 응답을 포함한다. (상상이 되는가?) XML 응답 처리는 평범한 텍스트 처리과정과 상당히 다르며, 문장분석 및 문서 객체 모델(DOM)을 포함한다. 다음 글에서는 XML에 대해 다루게 된다. responseXML 은 공통적으로 responseText과 관련된 논의에서 나오기 때문에 언급할 가치가 있는 것이다. 많은 단순 Ajax 애플리케이션의 경우, responseText만 있으면 된다. 하지만 Ajax 애플리케이션을 통해 XML을 처리하는 방법에 대해서도 곧 배우게 된다.
맺음말
XMLHttpRequest 객체에 대해서는 인제 좀 지루하게 들릴지도 모른다. 필자는 단일 객체, 특히 간단한 객체에 대한 전반적인 글을 거의 읽지 못했다. 하지만 Ajax를 사용하고 작성하는 각 페이지 및 애플리케이션에서 계속 XMLHttpRequest 객체를 사용하게 된다. 아직도 XMLHttpRequest 객체에 대해 언급되지 않은 것들이 많은 건 사실이다. 다음 글에서는 요청에서 GET 및 POST를 사용하고 서버로부터의 응답 및 요청의 컨텐트 헤더를 설정하고 읽어들이는 방법을 배운다. 그러면 요청을 코드화하고 심지어는 요청/응답 모델에서 XML을 다루는 방법을 배우게 될 것이다.
좀 더 상세하게 나가면 일반적으로 사용하는 Ajax 툴킷에 관해서도 알게 된다. 이 툴킷은 본 글에서 논의된 상세사항의 대부분을 실지로 요약한 것이다. 한편 툴킷을 손쉽게 이용하는 경우, 낮은 레벨의 상세사항을 코드화하는 이유에 대해 궁금해할 수도 있다. 사실은 애플리케이션 상에서 발생하는 현상을 이해하지 못하는 경우, 애플리케이션에서 일어나는 에러를 이해하는 게 어려워진다.
따라서, 이와 같은 사항을 간과하거나 지나치면 안 된다. 가변성 툴킷에서 에러가 발생할 경우, 머리를 끄적이면서 e-메일을 보내지 않아도 된다. 직접 XMLHttpRequest 사용법을 이해하면 가장 이상한 문제를 디버그하고 수정하는 것도 쉬워진다. 툴킷에 집중하면서 모든 문제를 해결하지 않는 한 툴킷은 그런대로 괜찮다.
따라서, XMLHttpRequest 객체에 대해 친숙해져라. 사실, 툴킷을 사용하는 Ajax 코드를 실행할 경우 XMLHttpRequest 객체 및 속성, 메소드를 사용해Ajax 코드를 재작성한다. 상당히 좋은 연습이 될 것이며 현재 이 객체에서 벌어지는 현상에 대해 더 잘 이해하게 될 것이다.
다음 글에서는 XMLHttpRequest에 대해 좀 더 자세하게 들어간다. 이 객체에서 어려운 속성(responseXML등의), POST 요청 사용법 및 몇 가지 다른 포맷에서의 데이터를 전송하는 방법을 조사할 것이다. 한 달 동안 코드화 작업을 시작해 코드를 다시 점검한다.
참고자료
교육
- Ajax 마스터, Part 1: Ajax 소개 (developerWorks, December 2005)
- 자바 개발자를 위한 Ajax: 동적 자바 애플리케이션 구현 (developerWorks, September 2005)
- 자바 개발자를 위한 Ajax: Ajax용 자바 객체 직렬화 (developerWorks, October 2005)
- Call SOAP Web services with Ajax (developerWorks, October 2005)
- Google GMail
- Flickr
- Ajax: A New Approach to Web Applications
- Why Ajax Matters Now
- Microsoft Developer Network's XML Developer Center.
- online documentation.
- HTTP status codes
- developerWorks Web Architecture zone
제품 및 기술 얻기
- Head Rush Ajax by Elisabeth Freeman, Eric Freeman, and Brett McLaughlin (February 2006, O'Reilly Media, Inc.)
- Java and XML, Second Edition by Brett McLaughlin (August 2001, O'Reilly Media, Inc.)
- JavaScript: The Definitive Guide by David Flanagan (November 2001, O'Reilly Media, Inc.)
- Head First HTML with CSS & XHTML by Elizabeth and Eric Freeman (December 2005, O'Reilly Media, Inc.)
토론
-포럼에 참여하기.
-developerWorks blogs.
Brett McLaughlin, Author and Editor | O'Reilly Media Inc.
원문 :http://www.dbguide.net/know/know102001.jsp?mode=view&divcateno=14&divcateno_=14&pg=1&idx=3054
많은 웹 개발자들에게 간단한 요청을 만들고 간단한 응답을 받는 것은 사실 그들이 필요로 하는 전부이다. 하지만 Ajax를 마스터하고자 하는 개발자들에게는 HTTP 상태 코드, 준비 상태, XMLHttpRequest 객체에 대한 완벽한 이해가 필요하다. Brett McLaughlin은 다양한 상태 코드들을 보여주고 브라우저가 이들 각각을 핸들하는 방법을 설명한다. 비교적 덜 사용되는 HTTP 요청에 대해서도 설명한다.
지난 글에서는 , XMLHttpRequest 객체에 대해 구체적으로 소개했다. 이것은 서버측 애플리케이션이나 스크립트에 대한 요청을 핸들하고, 서버측 컴포넌트에서 리턴 데이터를 처리하는 Ajax 애플리케이션의 주요 특징이다. 모든 Ajax 애플리케이션은 XMLHttpRequest 객체를 사용하기 때문에 Ajax 애플리케이션의 작동은 여기에 얼마나 익숙해지냐에 달려있다.
이번에는 지난 글에서 다루었던 기초를 넘어서 요청 객체의 세 가지 핵심 부분들에 대해 자세히 설명하겠다.
HTTP 준비 상태
HTTP 상태 코드
요청 유형들
이들 각각은 요청이라는 배관의 일부로 간주된다. 결국, 작은 상세가 이러한 주제들에 대해 기록된다. 하지만 Ajax 프로그래밍을 염두하고 있다면 준비 상태, 상태 코드, 요청에 익숙해 져야 한다. 애플리케이션에서 무엇인가 잘못되고 있다면 준비 상태, HEAD 요청을 하는 방법, 또는 400 상태 코드가 의미하는 것이 무엇인지를 이해하면 5분의 디버깅으로 끝낼 수 있거나 5시간 동안 좌절과 혼돈 속에서 방황할 수 있다.
HTTP 준비 상태 먼저 보도록 하자.
HTTP 준비 상태
지난 글에서 XMLHttpRequest 객체는 readyState 라는 속성을 갖고 있다고 설명했다. 이 속성은 서버가 요청을 완료하고 콜백 함수가 그 서버에서 온 데이터를 사용하여 웹 폼이나 페이지를 업데이트 하도록 한다. Listing 1은 이것에 대한 예제이다.(참고자료 참조)
Listing 1. 콜백 함수에서 서버의 응답 처리하기
function updatePage() {
if (request.readyState == 4) {
if (request.status == 200) {
var response = request.responseText.split("|");
document.getElementById("order").value = response[0];
document.getElementById("address").innerHTML =
response[1].replace(/\n/g, "< br />");
} else
alert("status is " + request.status);
}
}
XMLHttpRequest 또는 XMLHttp: 또 다른 이름의 장미
Microsoft™와 Internet Explorer는 Mozilla, Opera, Safari, 비 Microsoft 계열 브라우저에서 사용되는 XMLHttpRequest 객체 대신 XMLHttp 라는 객체를 사용한다. 단순하게 하기 위해서 이 두 가지 객체 모두 XMLHttpRequest로 칭하기로 한다. 웹을 검색하다 보면 이런 경우가 비일비재 하고 마이크로소프트도 Internet Explorer 7.0의 요청 객체의 이름으로 XMLHttpRequest를 사용하고 있다. ("JavaScript와 Ajax를 이용한 비동기식 요청" 참조)
이것은 전형적인 준비 상태의 사용법이다. "4"라는 숫자에서 짐작하듯 여러 가지 다른 준비 상태들이 있다.(참고자료 참조)
0: (open()을 호출하기 전에는) 요청이 초기화 되지 않는다.
1: (send()를 호출하기 전에는) 요청은 설정은 되지만 보내지지 않는다.
2: 요청이 보내지고 처리 중에 있다. (이 시점에서 응답에서 콘텐트 헤더를 얻을 수 있다.)
3: 요청이 처리 중에 있다. 부분적인 데이터를 응답에서 사용할 수 있지만 서버는 이 응답으로는 종료되지 않는다.
4: 응답이 완료된다. 서버의 응답을 받고 이를 사용한다.
Ajax 프로그래밍의 기초 이상으로 넘어가고 싶다면 이러한 상태 뿐만 아니라 이들이 언제 발생하고 어떻게 사용하는지에 대해 알아야 한다. 우선, 가장 중요한 것은 어떤 요청 상태가 될 것인지를 배워야 한다. 이는 별로 기분 좋은 일이 아니고 몇 가지 특별한 경우가 포함되어 있다.
숨어있는 준비 상태
readyState 0 (readyState == 0)으로 표시되는 첫 번째 준비 상태는 초기화 되지 않은 요청을 나타낸다. 요청 객체에 대해 open()을 호출하면 속성은 1로 설정된다. 대부분 요청을 초기화 하면서 open()을 호출하기 때문에 readyState == 0을 보는 일은 드물다. 더욱이 초기화 되지 않은 준비 상태는 실제 애플리케이션에서는 쓸모 없다.
Listing 2를 보면 0으로 설정된 준비 상태가 되는 방법을 알 수 있다.
Listing 2. 준비 상태 0
function getSalesData() {
// Create a request object
createRequest();
alert("Ready state is: " + request.readyState);
// Setup (initialize) the request
var url = "/boards/servlet/UpdateBoardSales";
request.open("GET", url, true);
request.onreadystatechange = updatePage;
request.send(null);
}
이 간단한 예제에서 getSalesData()는 웹 페이지가 요청을 시작하기 위해 호출하는 함수이다. (예를 들어, 버튼이 클릭 될 때.) open()이 호출되기 전에 준비 상태를 체크 해야 한다. 그림 1은 이 애플리케이션을 실행한 결과이다.
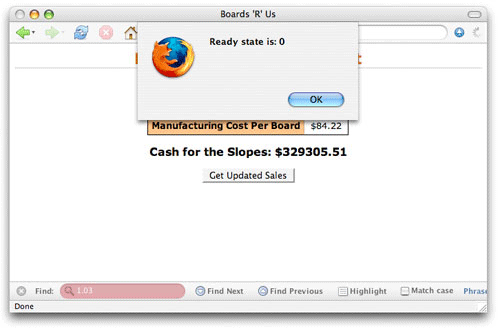
그림 1. 준비 상태 0
분명히 이것은 좋지 않다. open()이 호출되지 않았다는 것을 확인해야 한다. 실제 Ajax 프로그래밍에서 이러한 준비 상태의 유일한 사용은 다중 함수들에 같은 XMLHttpRequest 객체를 사용하여 다중 요청을 만드는 경우이다. 그러한 상황에서, 여러분은 요청 객체가 새로운 요청을 만들기 전에 초기화 되지 않은 상태(readyState == 0)에 있다는 것을 확인해야 한다. 이로서 또 다른 함수가 동시에 객체를 사용하는 것을 방지할 수 있다.
진행중인 요청의 준비 상태 보기
0 준비 상태 외에 요청 객체는 전형적인 요청 응답에서 또 다른 준비 상태를 경험하게 된다. 그리고 마지막으로는 준비 상태 4로 끝난다. 이 때는 대부분의 콜백 함수에서 if (request.readyState == 4)가 된다. 서버가 완료되고 웹 페이지를 업데이트 하거나 서버에서 받은 데이터를 기반으로 액션을 취하는 시기이다.
프로세스를 실제로 보는 것은 간단하다. 준비 상태가 4 라면 콜백에서 단순히 코드를 실행시키는 것 대신 콜백이 호출될 때 마다 준비 상태를 출력한다.(Listing 3)
Listing 3. 준비 상태 점검
function updatePage() {
// Output the current ready state
alert("updatePage() called with ready state of " + request.readyState);
}
0이 4와 같을 때
다중 JavaScript 함수들이 같은 요청 객체를 사용하는 경우, 그 요청 객체가 사용되고 있지 않다는 것을 확인하기 위해 준비 상태 0을 확인하면 문제가 많아질 수 있다. readyState == 4는 완료된 요청을 나타내기 때문에, 4로 설정된 준비 상태인 채로 사용되지 않은 요청 객체를 종종 보게 된다. abort()이라고 하는 요청 객체를 리셋하는 함수가 있지만 이는 여기에 사용하는 것이 아니다. 다중 함수들을 사용해야 한다면 다중 함수에 객체를 공유하는 것 보다 각 함수용 요청 객체를 생성 및 사용하는 것이 낫다.
이것이 어떻게 실행되는지 확실히 모르겠다면 웹 페이지에서 호출할 함수를 만들고 서버측 컴포넌트로 요청을 보내도록 한다.(Listing 2) 요청을 설정할 때 콜백 함수를 updatePage()로 설정한다. 요청 객체의 onreadystatechange 속성을 updatePage()로 설정한다.
이 코드는 onreadystatechange가 정확히 무엇을 의미하는지 잘 보여주고 있다. 요청의 준비 상태가 변할 때 마다 updatePage()가 호출되고 경고를 받는다. 그림 2는 호출되는 함수의 샘플이다. 이 경우 준비 상태는 1이다.
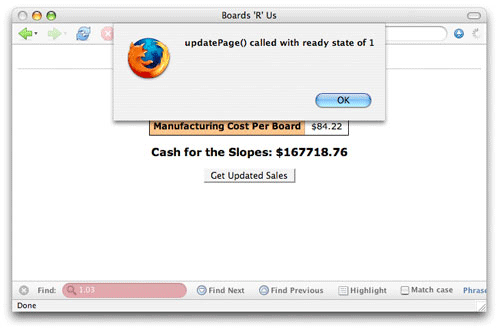
그림 2. 준비 상태 1
코드를 직접 실행해 보라. 웹 페이지에 넣고 이벤트 핸들러를 활성화 한다. (버튼을 누르거나, 요청을 실행하기 위해 설정하는 모든 메소드를 사용하라.) 콜백 함수는 여러 번 실행될 것이다. 요청의 준비 상태가 변할 때 마다 각 준비 상태에 대한 경고를 보게 된다. 이는 각 단계를 통해 요청을 따라가는 최상의 방법이다.
브라우저 차이
이 프로세스에 대해 기본적인 개념이 쌓였다면 여러 가지 다양한 브라우저에서 웹 페이지로 액세스 해보라. 준비 상태가 처리되는 방식에 차이가 있을 것이다. 예를 들어, Firefox 1.5에서, 준비 상태는 다음과 같다.
요청의 각 단계들이 다 나타나기 때문에 놀랍지도 않다. 하지만 Safari를 사용하여 같은 애플리케이션에 액세스 하면 재미있는 것을 발견하게 된다. 다음은 Safari 2.0.1에서 보게 되는 상태이다.
Safari는 첫 번째 준비 상태를 배제하고 그 이유에 대해서는 자세히 나와있지 않다. 바로 이것이 Safari 방식이다. 또한 중요한 포인트이기도 하다. 서버에서 데이터를 사용하기 전에 요청의 준비 상태가 4라는 것을 확인하는 것은 좋은 생각인 반면 일시적인 준비 상태에 의존하는 코드를 작성하는 것은 다른 브라우저 마다 다른 결과를 얻을 수 있는 확실한 방법이다.
예를 들어, Opera 8.5를 사용할 때 상황은 더 악화된다.
Internet Explorer는 다음과 같은 상태로 반응한다.
요청과 관련하여 문제가 있다면 문제의 원인을 찾을 수 있는 첫 번째 장소이다. 요청의 준비 상태를 보여주는 경고를 추가하여 상황이 정상적으로 돌아가는지를 확인할 수 있다. Internet Explorer와 Firefox 모두 테스트 하면 네 개의 모든 준비 상태를 얻을 수 있고 각 요청 단계를 검사할 수 있다.
이제는 응답 쪽을 살펴보도록 하자.
응답 데이터
요청 동안에 다양한 준비 상태가 발생할 수 있다는 것을 이해했다면 XMLHttpRequest객체의 또 다른 중요한 부분에 대해 살펴보도록 하자. 바로 responseText 속성이다. 이것은 서버에서 데이터를 얻을 때 사용되는 속성이다. 서버가 요청 처리를 완료하면 그 요청에 응답하는데 필요한 데이터를 요청의 responseText에 둔다. 그런 다음 콜백 함수가 그 데이터를 사용한다.(Listing 1과 Listing 4 참조)
Listing 4. 서버에서 응답 사용하기
function updatePage() {
if (request.readyState == 4) {
var newTotal = request.responseText;
var totalSoldEl = document.getElementById("total-sold");
var netProfitEl = document.getElementById("net-profit");
replaceText(totalSoldEl, newTotal);
/* Figure out the new net profit */
var boardCostEl = document.getElementById("board-cost");
var boardCost = getText(boardCostEl);
var manCostEl = document.getElementById("man-cost");
var manCost = getText(manCostEl);
var profitPerBoard = boardCost - manCost;
var netProfit = profitPerBoard * newTotal;
/* Update the net profit on the sales form */
netProfit = Math.round(netProfit * 100) / 100;
replaceText(netProfitEl, netProfit);
}
Listing 1은 매우 간단하다. Listing 4는 좀 더 복잡하다. 시작하려면 준비 상태를 검사하고 responseText 속성에서 값을 얻어야 한다
요청하는 동안 응답 텍스트 보기
준비 상태와 마찬가지로 responseText 속성의 값은 요청의 수명 주기에 걸쳐 변화한다. Listing 5의 코드를 사용하여 요청의 응답 텍스트를 테스트한다. 준비 상태도 마찬가지로 테스트 한다.
Listing 5. responseText 속성 테스트 하기
function updatePage() {
// Output the current ready state
alert("updatePage() called with ready state of " + request.readyState +
" and a response text of '" + request.responseText + "'");
}
브라우저에서 웹 애플리케이션을 열고 요청을 활성화 한다. 이 코드를 최대한 활용하려면 Firefox나 Internet Explorer를 사용한다. 이 두 개의 브라우저는 요청 동안 모든 준비 상태들을 보고하기 때문이다. 준비 상태 2에서 responseText 속성은 정의되지 않는다.(그림 3) JavaScript 콘솔이 열려있었다면 에러가 생겼을 것이다.
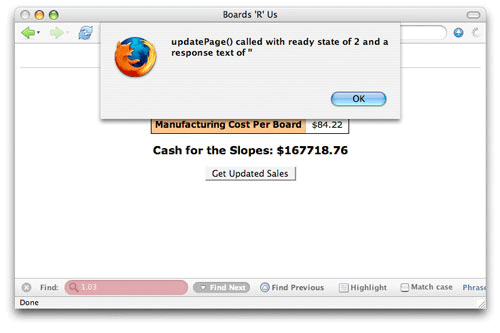
그림 3. 준비 상태 2의 응답 텍스트
준비 상태 3에서, 서버는 responseText 속성에 값을 배치한다.(그림 4)
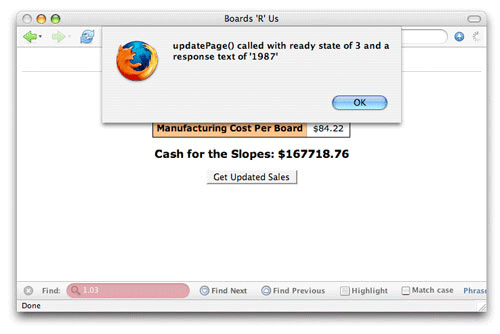
그림 4. 준비 상태 3의 응답 텍스트
준비 상태 3의 응답은 스크립트 마다, 서버 마다, 브라우저 마다 다르다. 애플리케이션을 디버깅 하는데 매우 유용하다.
안전한 데이터 얻기
모든 문서와 스팩들에서는 준비 상태가 4가 되어야지만 데이터를 안전하게 사용할 수 있다고 나와있다. 나를 믿으라. 준비 상태가 3일 때에도 responseText 속성에서 데이터를 얻을 수 있다. 하지만 여러분의 애플리케이션에서 이것에 의존하는 것은 좋지 않은 생각이다. 준비 상태 3에서 완전한 데이터에 의존하는 코드를 작성하는 것은 데이터가 불완전하다는 증거이다.
준비 상태가 3일 때 사용자에게 피드백을 제공하는 것이 좋은 생각이다. alert() 같은 함수를 사용하는 것은 좋지 않다. Ajax를 사용하고 사용자와 경고 다이얼로그 박스를 차단시키는 것은 좋지 않지만 준비 상태가 변할 때 마다 폼이나 페이지에 대한 필드를 업데이트 할 수 있다. 예를 들어, 프로그레스 인디케이터의 넓이를 준비 상태 1에 25 퍼센트, 준비 상태 2에 50 퍼센트, 준비 상태 3에 75 퍼센트, 준비 상태 4에 100 퍼센트를 설정한다.
물론 알다시피, 이 방식은 좋기는 하지만, 브라우저에 의존적이다. Opera에서는 첫 번째 두 개의 준비 상태를 결코 얻지 못하고 Safari는 처음 1 상태를 누락시킨다.
이제 상태 코드에 대해 알아보자.
HTTP 상태 코드
Ajax 프로그래밍 기술에서 준비 상태와 서버의 응답 외에도, Ajax 애플리케이션에 또 다른 고급 레벨을 추가할 수 있다. 바로 HTTP 상태 코드이다. 이 코드들은 Ajax에서는 새우울 것이 없다. 웹에 있는 한 언제나 존재하는 것들이다. 웹 브라우저를 통해 이들을 보았을 것이다.
- 401: Unauthorized
- 403: Forbidden
- 404: Not Found
이 외에도 더 있다.(참고자료) Ajax 애플리케이션에 또 다른 제어 및 응답 레이어를 추가하려면 요청과 반응에 상태 코드를 검사해야 한다.
200: Everything is OK
많은 Ajax 애플리케이션에서 준비 상태를 점검하고 서버 응답으로 온 데이터로 작업하는 콜백 함수를 볼 수 있다.(Listing 6)
Listing 6. 상태 코드를 무시하는 콜백 함수
function updatePage() {
if (request.readyState == 4) {
var response = request.responseText.split("|");
document.getElementById("order").value = response[0];
document.getElementById("address").innerHTML =
response[1].replace(/\n/g, "
");
}
}
이것은 근시안적이고 에러를 많이 만드는 Ajax 프로그래밍 방식이다. 스크립트가 인증을 필요로 하는데 요청이 유효 증명을 제공하지 않으면 서버는 403 또는 401 같은 에러를 리턴한다. 하지만 서버가 요청에 응답하기 때문에 준비 상태는 4로 설정될 것이다. 결과적으로 사용자는 유효 데이터를 얻지 못하고 JavaScript가 존재하지 않는 서버 데이터를 사용하려고 할 때 에러를 얻게 된다.
서버가 요청을 완료하고 "Everything is OK" 상태 코드를 리턴했다는 것을 확인하는 것은 간단한 일이다. 이 코드는 "200"이고 XMLHttpRequest 객체의 status 속성을 통해서 보고된다. 서버가 요청으로 끝나고 OK 상태를 리포트 했다는 것을 확인하려면 추가 체크를 콜백 함수에 추가한다.(Listing 7)
Listing 7. 유효 상태 코드 추가
function updatePage() {
if (request.readyState == 4) {
if (request.status == 200) {
var response = request.responseText.split("|");
document.getElementById("order").value = response[0];
document.getElementById("address").innerHTML =
response[1].replace(/\n/g, "
");
} else
alert("status is " + request.status);
}
}
코드에 몇 줄을 추가하는 것으로 무엇이 잘못되었는지를 알 수 있고 사용자는 아무런 설명이 없는 데이터 데신 유용한 에러 메시지들을 받을 수 있다.
리다이렉션과 재 라우팅
에러에 대해 이야기 하기 전에 Ajax를 사용할 때 걱정하지 않아도 될 부분에 대해 말해두겠다. 바로 리다이렉션이다. HTTP 상태 코드에서, 이것은 300 대의 상태 코드이다.
301: Moved permanently
302: Found (요청이 또 다른 URL/URI로 리다이렉션 된다.)
305: Use Proxy (요청은 프록시를 사용하여 요청 받은 리소스에 액세스 해야 한다.)
Ajax 프로그래머가 리다이렉션에 대해 염려 할 필요가 없는 이유가 두 가지 있다.
Ajax 애플리케이션들은 특정 서버측 스크립트, 서블릿, 애플리케이션을 위해 작성된다. 그 컴포넌트를 없애거나 다른 곳으로 이동하기 위함이다. 리소스는 변경되었다는 것을 (이미 이동했기 때문에)알고, 요청에서 URL을 변경하고 이러한 종류의 결과를 절대 만나지 않게 된다.
보다 관련성 있는 이유가 있다. Ajax 애플리케이션과 요청들은 샌드박스화 되어있다. Ajax 요청을 만드는 웹 페이지를 공급하는 도메인은 그러한 요청에 응답해야 하는 도메인이다. 따라서 ebay.com에서 공급 받은 웹 페이지는 Ajax 스타일의 요청을 amazon.com에서 실행되는 스크립트에 할 수 없다. ibm.com 상의 Ajax 애플리케이션은 netbeans.org에서 실행되는 서블릿으로 요청할 수 없다.
결국, 요청은 보안 에러를 만들지 않고서는 또 따른 서버로 리다이렉션 될 수 없다. 그러한 경우에, 상태 코드를 전혀 얻을 수 없다. 디버그 콘솔에 JavaScript 에러를 갖게 된다. 따라서 많은 상태 코드에 대해 생각하는 동안 리다이렉션 코드 정도는 무시할 수 있는 것이다.
엣지 케이스와 하드 케이스
이 부분에서, 신참 프로그래머들은 이러한 혼란에 대해 궁금할 것이다. Ajax 요청의 5 퍼센트 정도는 2와 3 정도의 준비 상태와 403 같은 상태 코드로 작동해야 한다. (사실, 1 퍼센트 미만이다.) 이러한 케이스는 중요하고, 엣지 케이스(edge cases)라고 일컬어진다. 이상한 조건들이 부합되는 특수한 상황인 것이다. 일상적인 것은 아니지만 사용자를 곤란에 처하게 한다.
일반적인 사용자들은 애플리케이션이 정확히 작동하는지 매번 잊지만 그렇지 않을 때는 분명히 기억한다. 엣지 케이스와 하드 케이스를 핸들 할 수 있다면 사이트 사용자들을 만족시킬 수 있을 것이다.
에러
일단, 상태 코드 200을 관리했고 300 계열의 상태 코드는 대충 무시하면 다양한 유형의 에러들을 나타내는 400 계열의 코드만 남게 된다. Listing 7을 보면 에러가 처리되는 동안 사용자에게 출력되는 매우 일반적인 에러 메시지라는 것을 알게 된다. 이것은 올바른 방향으로 가는 단계지만 사용자와 프로그래머에게는 매우 쓸모없는 메시지이다.
우선 소실된 페이지에 대한 지원을 추가한다. 이는 제품 시스템에서는 실제로 발생하지는 않지만 스크립트를 이동시키는 테스트나 정확하지 않은 URL을 입력할 때 자주 일어나는 일이다. 404 에러를 보고하면 혼란스러워 하는 사용자와 프로그래머에게 더 많은 도움말을 제공할 것이다. 예를 들어, 서버 상의 스크립트가 제거되거나 Listing 7에서 그 코드를 사용하면 다음과 같은 에러가 생긴다.(그림 5)
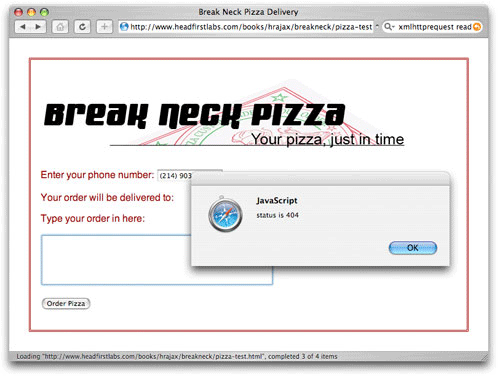
그림 5. 일반적인 에러 핸들링
사용자는 문제가 무엇인지 잘 모른다. 인증에 관련된 것인지, 소실된 스크립트 인지, 사용자 에러인지 알 수 없다. 몇 가지 간단한 코드 추가로 이 에러는 더욱 구체화 된다. Listing 8을 보면 소실된 스크립트와 인증 에러까지 구체적인 메시지와 함께 처리된다.
Listing 8. 유효 상태 코드 점검
function updatePage() {
if (request.readyState == 4) {
if (request.status == 200) {
var response = request.responseText.split("|");
document.getElementById("order").value = response[0];
document.getElementById("address").innerHTML =
response[1].replace(/\n/g, "
");
} else if (request.status == 404) {
alert ("Requested URL is not found.");
} else if (request.status == 403) {
alert("Access denied.");
} else
alert("status is " + request.status);
}
}
이는 오히려 더 간단하지만 추가 정보 까지 제공한다. 그림 6은 그림 5와 같은 에러를 보여주지만 이번에는 에러 핸들링 코드가 더 나은 그림을 제공하고 있다.
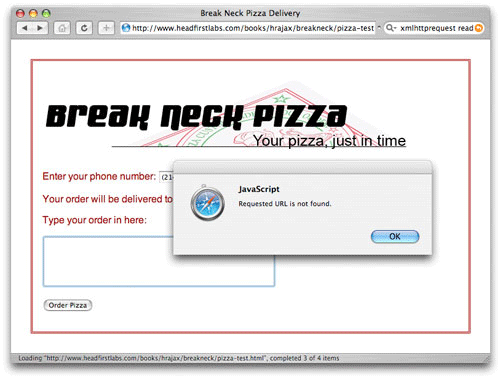
그림 6. 구체적인 에러 핸들링
여러분의 애플리케이션에서 인증 때문에 오류가 발생했을 때 사용자 이름과 패스워드를 지우고 에러 메시지를 스크린에 추가하는 것을 고려할 수도 있다. 이와 비슷한 방식이 소실된 스크립트나 다른 400 유형의 에러들을 핸들하는데 사용될 수 있다. 여러분이 어떤 선택을 하든 서버에서 리턴 된 상태 코드를 핸들하는 것으로 시작한다.
추가 요청 유형
XMLHttpRequest 객체를 제어하고 싶다면 HEAD 요청을 레파토리에 추가하라. 이전 두 개의 기사에서 GET 요청을 하는 방법을 설명했다. 앞으로는 POST 요청을 사용하여 서버로 데이터를 보내는 것을 설명하도록 하겠다. 향상된 에러 핸들링과 정보 수집을 위해 HEAD 요청에 대해 배워야 한다.
요청하기
HEAD 요청은 실제로 매우 간단하다. 첫 번째 매개변수로서 "GET" 또는 "POST" 대신 "HEAD"로 open() 메소드를 호출한다.(Listing 9)
Listing 9. HEAD 요청
function getSalesData() {
createRequest();
var url = "/boards/servlet/UpdateBoardSales";
request.open("HEAD", url, true);
request.onreadystatechange = updatePage;
request.send(null);
}
이와 같이 HEAD 요청을 하면 서버는 GET이나 POST 요청 때 처럼 실제 응답을 리턴하지 않는다. 대신, 서버는 응답에 있는 콘텐트가 마지막으로 수정된 시간이 포함된 리소스의 헤더를 리턴한다. 게다가 몇 가지 재미있는 정보도 추가한다. 이들을 사용하여 서버가 리소스를 처리 및 리턴하기 전에 리소스에 대해 알 수 있다.
이와 같은 요청으로 할 수 있는 가장 쉬운 일은 모든 응답 헤더들을 나누는 것이다. 이로서 HEAD 요청을 통해 무엇이 가능한지를 알 수 있다. Listing 10은 HEAD 요청에서 모든 응답 헤더를 출력하는 콜백 함수이다.
Listing 10. HEAD 요청에서 모든 응답 헤더 프린트 하기
function updatePage() {
if (request.readyState == 4) {
alert(request.getAllResponseHeaders());
}
}
그림 7에서 서버에 HEAD 요청을 한 간단한 Ajax 애플리케이션에서 온 응답 헤더를 볼 수 있다.
그림 7. HEAD 요청에서 온 응답 헤더
이러한 헤더들을 개별적으로 사용하여 Ajax 애플리케이션에서 추가 정보나 기능을 제공할 수 있다.
URL 검사
URL이 존재하지 않을 때 404 에러를 검사하는 방법을 이미 보았다. 이것이 일반적인 문제라면, 특정 스크립트나 서블릿이 잠시 동안 오프라인에 있었다면, GET 또는 POST 요청을 하기 전에 URL을 검사해 보는 것이 좋다. HEAD 요청을 하고 콜백 함수에서 404 에러를 검사한다. Listing 11은 샘플 콜백을 보여준다.
Listing 11. URL이 존재하는지 여부 검사
function updatePage() {
if (request.readyState == 4) {
if (request.status == 200) {
alert("URL exists");
} else if (request.status == 404) {
alert("URL does not exist.");
} else {
alert("Status is: " + request.status);
}
}
}
솔직히 말하면 이것의 가치는 별로 없다. 서버는 요청에 응답해야 하고 응답을 분석하여 응답 헤더에 파퓰레이트 하기 때문에 여러분은 프로세싱 시간을 저축할 수 없다. 게다가 요청을 하고 HEAD 요청을 사용하여 URL이 존재하는지 보는 것에도 많은 시간이 걸린다. Listing 7에서 처럼 에러를 핸들링 하기 보다 GET이나 POST를 사용하여 요청하기 때문이다. 무엇을 사용할 수 있는지를 정확히 아는 데는 가끔 유용하다.
유용한 HEAD 요청
HEAD 요청이 유용한 한 가지 부분은 콘텐트 길이나 콘텐트 유형을 검사할 때이다. 요청을 처리하기 위해 많은 양의 데이터를 보낼 것인지, 서버가 HTML, 텍스트, XML 대신 바이너리 데이터를 리턴해야 할지를 결정할 수 있다. (이 세 가지 모두 바이너리 데이터 보다 JavaScript에서 처리하는 것이 더 쉽다.)
이 경우, 적절한 헤더 이름을 사용하고 이를 XMLHttpRequest 객체의 getResponseHeader() 메소드로 보낸다. 따라서 응답의 길이를 알려면 request.getResponseHeader("Content-Length");를 호출한다. 콘텐트 유형을 알려면 request.getResponseHeader("Content-Type");를 사용한다.
많은 애플리케이션에서 HEAD 요청을 하면 어떤 기능도 추가하지 않고 요청의 속도를 늦출 수 있다. (HEAD 요청을 실행하여 응답에 대한 데이터를 얻고 후속 GET 또는 POST 요청을 통해 응답을 실제로 받는다.) 하지만 스크립트나 서버측 컴포넌트에 대해 확실하지 않은 경우 HEAD 요청으로 기본적인 데이터를 받을 수 있다.
결론
Ajax와 웹 프로그래머에게 이 글은 다소 어려울 것이다. HEAD 요청을 하는 것의 가치는 무엇인가? JavaScript에서 리다이렉션 상태 코드를 핸들해야 하는 때는 언제인가? 이 모두 좋은 질문이다. 간단한 애플리케이션의 경우, 이 모든 것은 가치가 별로 없다.
하지만 웹이 단순한 애플리케이션만 수용하는 것은 아니다. 사용자는 점점 고급화 되고 고객들도 강력한 에러 리포팅을 원한다. 관리자 역시 애플리케이션이 조금만 느려져도 해고를 당하게 된다.
간단한 애플리케이션을 넘어 XMLHttpRequest에 대한 이해를 높여야 할 때이다.
다양한 준비 상태를 이해하고 이들이 브라우저 마다 어떻게 다른지를 이해하면 애플리케이션을 빠르게 디버깅 할 수 있다. 준비 상태에 기반하여 창조적인 기능을 만들고 요청자의 상태에 대해 사용자와 고객에게 보고할 수 있다.
상태 코드를 핸들했다면 스크립트 에러, 예기치 못한 응답들, 엣지 케이스들을 다룰 수 있다. 결국, 애플리케이션은 언제나 잘 작동될 것이다.
여기에 더하여 HEAD 요청을 만들고, URL의 존재를 검사하고 파일이 언제 수정되었는지를 파악하고 사용자가 유효 페이지를 얻었는지를 확인할 수 있다면 언제나 최신의 정보와 강력한 기능으로 사용자들을 만족시킬 수 있을 것이다.
이들은 모두 Ajax의 강점이지만 극히 일부분이다. Ajax를 사용하여 애플리케이션이 에러와 문제들을 부드럽게 해결할 수 있는 강력한 토대를 구현한다면 사용자는 여러분의 사이트를 방문할 것이다. 다음 글에서는 보다 더 재미있고 흥미 있는 주제들을 나누도록 하겠다.
다운로드 하십시오
| 설명 |
이름 |
크기 |
다운로드 방식 |
| Example code for this article |
wa-ajaxintro3_ajax-xhr_adv.zip |
183 KB |
HTTP |
참고자료
교육
- "Ajax 마스터, Part 1: Ajax 소개" (developerWorks, December 2005)
- "Ajax 마스터하기, Part 2: JavaScript와 Ajax를 이용한 비동기식 요청" (developerWorks, January 2006)
- "자바 개발자를 위한 Ajax: 동적 자바 애플리케이션 구현" (developerWorks, September 2005)
- "자바 개발자를 위한 Ajax: Ajax용 자바 객체 직렬화" (developerWorks, October 2005)
- "Call SOAP Web services with Ajax, Part 1: Build the Web services client" (developerWorks, October 2005)
- Google GMail, Google Maps
- Flickr
- "Ajax: A New Approach to Web Applications
- HTTP status codes
- Head Rush Ajax by Elisabeth Freeman, Eric Freeman, and Brett McLaughlin (February 2006, O'Reilly Media, Inc.)
- Java and XML , Second Edition by Brett McLaughlin (August 2001, O'Reilly Media, Inc.)
- JavaScript: The Definitive Guide by David Flanagan (November 2001, O'Reilly Media, Inc.)
- Head First HTML with CSS & XHTML by Elizabeth and Eric Freeman (December 2005, O'Reilly Media, Inc.)
- developerWorks Web architecture zone
- developerWorks technical events and Webcasts
제품 및 기술 얻기
-IBM trial software
토론
-포럼에 참여하기.
-developerWorks blogs.
Brett McLaughlin, Author and Editor | O'Reilly Media Inc.
원문 :http://www.dbguide.net/know/know102001.jsp?mode=view&divcateno=14&divcateno_=14&pg=1&idx=3055
프로그래머(백엔드 애플리케이션)와 웹 프로그래머(주로 HTML, CSS, JavaScript를 작성)사이에는 오래 전부터 엄격한 구분이 있었습니다. 하지만 Document Object Model (DOM)이 그 틈을 메우면서 백 엔드에서는 XML과, 프론트 엔드에서는 HTML과의 작업이 가능해 졌습니다.
많은 웹 프로그래머들과 마찬가지로 여러분도 HTML로 작업을 해봤을 것이다. HTML은 프로그래머들이 웹 페이지 상에서 작업할 때 사용한다. HTML은 애플리케이션이나 사이트를 마감하면서 수행하는 마지막 작업이고, 배치, 색상, 스타일 등을 끝까지 작업한다. 웹 페이지의 디자인과 공급과 관련한 프로세스를 명확히 파악할 필요가 있다.
1. 누군가가(대개는 여러분이) 텍스트 에디터나 IDE에서 HTML을 만든다.
2. 그런 다음, HTML을 Apache HTTPD 같은 웹 서버에 업로딩하고 이것을 인터넷이나 인트라넷에 퍼블리시 한다.
3. 사용자는 Firefox 또는 Safari 같은 브라우저를 사용하여 웹 페이지에 요청한다.
4. 사용자의 브라우저는 여러분의 웹 브라우저에 HTML용 요청을 만든다.
5. 브라우저는 서버에서 받는 페이지를 그래픽 또는 테스트로 렌더링 한다. 사용자는 웹 페이지를 보고 활성화 한다.
매우 기본적인 것처럼 보이지만 실상은 매우 흥미롭다. 사실, 엄청난 양의 “성분(stuff)”들이 있다. 이것은 주로 4 단계와 5 단계 사이에 발생하고 바로, 이 부분을 이 글에서 중점적으로 다룰 것이다. 대부분의 프로그래머들은 사용자의 브라우저가 이것을 디스플레이 하도록 요청 받으면 대부분의 프로그래머들은 자신들의 마크업에 어떤 일이 발생하는지 정확히 고려하지 않기 때문이다.
브라우저가 단순히 HTML에 있는 텍스트를 읽고 디스플레이 하는가?
CSS가 외부 파일에 있을 경우, CSS는 어떤가?
외부 파일에 있는 JavaScript는 어떤가?
브라우저는 이러한 아이템들을 어떻게 핸들하며 이벤트 핸들러, 기능, 스타일들을 텍스트 마크업으로 어떻게 매핑하는가?
이 모든 질문들에 대한 답은 Document Object Model이다. 이제 본격적으로 DOM을 논해보자.
웹 프로그래머와 마크업
프로그래머의 작업이 끝날 때 웹 브라우저가 시작된다. 다시 말해서, HTML 파일을 웹 서버 상의 디렉토리에 얹어 놓으면 보통 이것을 "완료된 것 "으로 정리해 놓고 절대로 다시는 생각하지 않는다! 깨끗하고, 구성이 잘된 페이지를 작성할 때도 이것은 너무 멋진 목표이다. 여러분의 마크업이 브라우저를 통해 다양한 버전의 CSS와 JavaScript로 디스플레이 하기를 원하는데 이것도 잘못은 아니다.
문제는 이러한 접근 방식이 브라우저에서 실제로 무슨 일이 일어나는지에 대해 프로그래머가 알 수 있는 범위를 제한한다는 점이다. 더욱이 클라이언트 측 JavaScript를 사용하여 웹 페이지를 동적으로 업데이트, 변경, 재구현 할 수 있는 기능 까지 제한한다. 이러한 한계를 제거하고 더 나아가 웹 사이트에서 더 나은 인터랙션과 생산성을 도모할 수 있다.
프로그래머가 하는 일
웹 프로그래머로서 여러분은 텍스트 에디터와 IDE를 시작하고 HTML, CSS, 심지어 JavaScript를 입력하기 시작한다. 태그, 셀렉터, 애트리뷰트를 사이트가 올바르게 보일 수 있도록 하는 작은 태스크라고 생각하기 쉽다. 하지만 그러한 관점을 좀더 확장 할 필요가 있다. 여러분이 콘텐트를 구성하고 있다는 것을 깨달아야 한다. 걱정하지 말라. 마크업의 가치에 대해 일장 연설을 늘어놓으려는 것은 아니다. 웹 페이지의 진정한 가치를 깨닫는 방법 내지는 형이상학적인 무엇인가를 설명하려는 것도 아니다. 여러분이 이해해야 할 것은 웹 개발 시 여러분의 역할이 정확히 무엇인가를 이해해야 한다.
페이지를 보이게 해야 하는 시점에 와서 여러분은 제안만 할 수 있을 뿐이다. 여러분이 CSS 스타일시트를 제공하면 사용자는 여러분의 스타일을 무시할 수 있다. 폰트 사이즈를 제공하면 사용자의 브라우저는 그러한 사이즈를 변경할 수 있고 모니터에 맞게 스케일링 할 수 있다. 폰트와 컬러도 사용자의 모니터에 맞게 선택할 수 있다. 페이지를 스타일링 할 때 최선을 다하는 것도 중요하지만 이는 웹 페이지에 큰 영향을 주지 못한다.
여러분이 완벽히 제어하는 것은 웹 페이지의 구조이다. 여러분의 마크업은 변경할 수 없고 사용자는 이것을 망칠 수 없다. 브라우저는 웹 서버에서 이것을 가져와서 디스플레이 한다. (여러분의 구미 보다 사용자의 구미에 따라 스타일로) 하지만 이 페이지의 구성은-이 단어가 그 문단 내에 있든 다른 div에 있든-전적으로 여러분에 달려있다. 페이지를 실제로 변경할 때(이것은 대부분의 Ajax 애플리케이션들이 집중하는 것이다.) 이것은 여러분이 운영하는 페이지의 구조이다. 텍스트의 조각의 색상을 변경하는 것이 좋지만 텍스트나 전체 섹션을 기존 페이지에 추가하는 것이 훨씬 더 좋다. 사용자가 그 섹션을 어떻게 스타일링 하던지 간에 페이지 그 자체의 구성을 가지고 작업한다.
마크업이 수행하는 일
마크업이 구성에 관한 것이라는 것을 깨달으면 이것을 달리 볼 수 있다. h1이 텍스트를 크고, 검고, 두껍게 만든다고 생각하는 대신 h1을 헤딩으로서 생각하라. 사용자가 어떻게 보는가, 그리고 사용자가 여러분의 CSS를 사용하는 자신들의 것을 사용하든 두 개를 결합하여 사용하든 이것은 두 번째 문제이다. 대신 마크업은 이 정도의 구성을 제공하는 것이라는 것을 깨달아라. P는 텍스트가 단락(paragraph)이라는 것을 나타내고, img는 이미지를, div는 페이지를 섹션으로 나눈다.
스타일과 작동(이벤트 핸들러와 JavaScript)가 fact 뒤에 이 구성에 적용된다는 것도 명확해 진다. 마크업은 적소에서 작동되거나 스타일링 되어야 한다. 따라서 HTML에 대한 외부 파일에 CSS를 갖는 것처럼 마크업의 구성도 스타일, 포맷팅, 작동과 분리된다. 엘리먼트의 스타일 또는 텍스트 조각을 JavaScript로부터 확실히 변화시킬 수 있고 마크업이 레이아웃 한 구성을 실제로 바꿀 수 있다는 것은 더 흥미 있는 사실이다.
마크업이 페이지에 구성 또는 프레임웍만 제공한다는 것을 마음에 새긴다면 본격적인 게임에 돌입해보자. 브라우저가 모든 텍스트 구성을 가지고, 이를 변경, 추가, 삭제 가능한 객체로 바꾸는 방법을 보자.
텍스트 마크업의 장점
웹 브라우저를 논하기 전에 왜 플레인 텍스트가 HTML을 저장하기에 최상의 선택인지를 생각해 봐야 한다. (마크업에 대해 더 알아야 할 것들 참조) 찬반을 논하기 전에, 페이지가 보여질 때 마다 HTML이 네트워크를 통해 웹 브라우저로 보내진다는 것을 생각해 보라. (캐싱 같은 문제는 차후에 논하기로 한다.) 텍스트와 함께 전달하는 것 보다 효율적인 방법은 없다. 바이너리 객체, 그래픽으로 구현된 페이지, 재구성된 마크업 청크 등, 이 모든 것들은 플레인 텍스트 파일 보다 네트워크를 통해 전송할 때 더 어려운 것들이다.
브라우저를 이러한 방정식에 대입해 보자. 오늘날의 브라우저에서는 사용자가 텍스트의 크기길 변경하고, 이미지를 스케일링 하고 CSS나 JavaScript를 다운로드 할 수 있다. 이 모든 것은 페이지의 온갖 종류의 그래픽 표현을 브라우저로 보내는 전조가 된다. 대신 브라우저는 미가공 HTML을 필요로 한다. 왜냐하면 이것은 태스크를 핸들하기 위해 서버를 믿기 보다 어떤 프로세싱이든 브라우저에 있는 페이지에 적용할 수 있기 때문이다. 같은 맥락에서, CSS와 JavaScript를 분리하고, 이들을 HTML 마크업에서 분리할 때에는 분리하기 쉬운 포맷이 필요하다.
HTML 4.01, XHTML 1.0/ 1.1 같은 새로운 표준들이 콘텐트(페이지의 데이터)를 표현과 스타일(보통 CSS에 의해 적용됨)에서 분리하겠다는 약속을 기억하는가? 프로그래머들이 CSS에서 HTML을 분리하려면 브라우저를 실행하여 페이지에서 몇몇 구현들을 가져오고 그러한 표준의 많은 장점들을 없앤다. 브라우저에서 이렇게 다른 부분들을 계속 분리시키면 브라우저는 서버에서 HTML을 가져올 때 최상의 유연성을 보인다.
마크업에 대해 더 알아야 할 것들
플레인 텍스트 편집: 옳은가, 그른가?
플레인 텍스트 파일은 마크업을 저장하는 데는 이상적이지만 그 마크 업을 편집하는 데는 그렇지 못하다. Macromedia DreamWeaver 또는 Microsoft ?? FrontPage ?? 같은 IDE를 사용하는 것이 바람직하다. 이러한 환경은 종종 웹 페이지를 구현할 때 도움이 되는 지름길과 도움말을 제공한다. 특히 CSS와 JavaScript를 사용할 때 그렇다. 많은 사람들은 여전히 Notepad나 vi를 선호한다. (고백하건데 나도 그 중 하나이다.) 이것 역시 좋은 선택이다. 두 경우 모두 마지막 결과는 마크업으로 가득 찬 텍스트 파일이다.
네트워크를 통한 텍스트: 좋은 것
이미 언급했듯이 텍스트는 HTML이나 CSS 같은 문서에 있어 훌륭한 미디어이다. 이것은 네트워크를 통해 수백, 수천 번 이동한다. 브라우저가 텍스트를 나타내는데 어려움을 겪는다면 텍스트를 시각적 페이지와 그래픽 페이지로 변환한다는 의미이다. 브라우저가 웹 서버에서 페이지를 실제로 가져오는 방법과는 관련이 없다. 이 경우 텍스트는 여전히 최상의 옵션이다.
웹 브라우저 분석
지금까지 여러분이 읽은 모든 것은 웹 개발 프로세스에서의 여러분의 역할에 대한 리뷰에 불과하다. 하지만 웹 브라우저가 무엇을 수행하는지를 논해야 하는 시점에서 유능한 많은 웹 디자이너와 개발자들은 보이지 않는 곳에서 실제로 어떤 일이 발생하는지 종종 깨닫지 못한다. 이 섹션에서는 바로 그 부분을 설명하도록 하겠다. 걱정하지 말라. 코드도 함께 등장할 것이다. 잠시 코딩하고 싶은 조바심을 접어두라. 웹 브라우저가 정확히 어떤 일을 수행하는지를 이해하는 것이 정확한 코딩 작업의 필수이기 때문이다.
텍스트 마크업의 단점
텍스트 마크업이 디자이너나 페이지 생성자에게 엄청난 이득을 주듯이 브라우저에는 비교적 큰 단점을 갖고 있다. 특히 브라우저는 텍스트 마크업을 사용자에게 시각적으로 직접 나타내기가 매우 힘들다. (마크업에 대해 더 알아야 할 것들 참조) 다음과 같은 브라우저 태스크를 생각해 보라.
CSS 스타일?외부 파일에 있는 다중 스타일시트?을 HTML 문서의 엘리먼트 유형, 클래스, 아이디, 위치에 기반하여 마크업에 적용한다.
JavaScript 코드에 기반한 스타일과 포맷팅?외부 파일에도 있음?을 HTML 문서의 다른 부분들에 적용한다.
JavaScript 코드에 기반하여 폼 필드의 값을 변경한다.
JavaScript 코드에 기반하여 이미지 롤오버와 이미지 스와핑 같은 시각 효과를 지원한다. 복잡함은 이러한 태스크들을 코딩 하는데 있는 것이 아니다. 이러한 일들을 하기는 정말 쉽다. 복잡함은 브라우저가 실제로 요청된 액션을 수행하는 데서 온다. 마크업이 텍스트로 저장되면 center-text 클래스에서 텍스트를 센터링 해야 한다. (text-align: center) 이것을 어떻게 할 것인가?
텍스트에 인라인 스타일링을 추가하는가?
브라우저의 HTML 텍스트에 스타일링을 적용하고 어떤 것이 센터링 되는지, 어떤 것이 센터링 되지 않는지를 지켜보는가?
스타일링 되지 않은 HTML을 적용한 다음 팩트 다음에 포맷을 적용하는가?
이 같은 매우 어려운 질문들 때문에 몇몇 사람들이 오늘날 브라우저를 코딩을 한다.
확실히, 플레인 텍스트는 브라우저를 위해 HTML을 저장하는 최상의 방법은 아니다. 텍스트가 페이지의 마크업을 가져오는 좋은 솔루션이었지만 말이다. 이 외에도 JavaScript가 페이지의 구조를 변경하는 기능은 트릭이 조금 있다. 브라우저가 수정된 구조를 디스크에 재작성 해야 하는가? 문서의 현재 어떤 단계에 있는지를 어떻게 파악할 수 있는가?
확실히 텍스트는 답이 못 된다. 수정하기도 어렵고, 스타일과 작동을 추가하기에는 불편하고, 궁극적으로 오늘날 웹 페이지의 동적인 특징과 거리가 멀다.
트리 뷰로 이동하기
이 문제에 대한 답, 오늘날의 웹 브라우저에 맞는 답은 트리 구조를 사용하여 HTML을 나타내는 것이다. 텍스트 마크업으로 구현된 단순하고 지루한 HTML 페이지 대신 Listing 1을 보자.
Listing 1. 텍스트 마크업의 간단한 HTML 페이지
<html>
<head>
<title>Trees, trees, everywhere</title>
</head>
<body>
<h1>Trees, trees, everywhere</h1>
<p>Welcome to a <em>really</em> boring page.</p>
<div>
Come again soon.
<img src="come-again.gif" />
</div>
</body>
</html>
그림 1. 이 브라우저는 이것을 트리 구조로 변환한다.
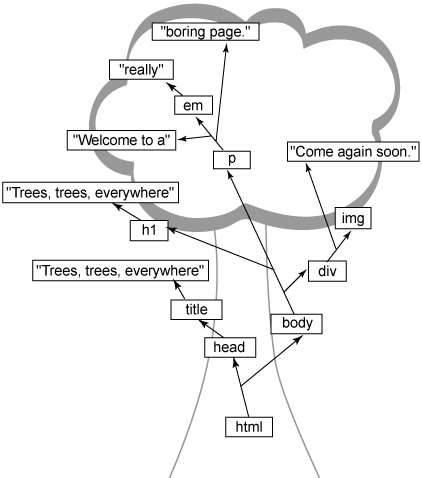
그림 1. Listing 1의 트리 뷰
이 글을 위해 단순함을 유지했다. DOM과 XML 전문가는 공백이 문서에 있는 텍스트가 구현되고 웹 브라우저의 트리 구조에서 깨지는 방법에 영향을 줄 수 있다는 것을 알 것이다. 공백의 효과에 대해 알고 있다면 정말 대단하다. 그렇지 않다면 공부하면 된다. 걱정 말라. 이것이 문제가 될 때 필요한 것이 무엇인지를 깨닫게 될 것이다.
실제 트리 백그라운드 외에 여기에서 알아야 할 첫 번째 것은 트리에 있는 모든 것이 가장 바깥쪽에서 시작되고 HTML의 엘리먼트(html)를 포함하고 있다는 것이다. 이는 트리 메타포에서 루트(root) 엘리먼트라고 불린다. 이것이 트리의 바닥에 있지만 트리를 분석할 때면 언제나 이것부터 시작한다. 완전히 거꾸로 뒤집어보면 도움이 될 것이다.
루트에서부터 마크업의 다양한 조각들 간 관계를 보여주는 라인의 흐름을 따라가 보라. head와 body 엘리먼트는 html 루트 엘리먼트의 자식들이다. title은 head의 자식이고 "Trees, trees, everywhere" 텍스트는 title의 자식이다. 전체 트리는 브라우저가 그림 1과 비슷한 구조가 될 때까지 이와 같이 구성된다.
몇 가지 추가 용어
트리 메타포를 이해하기 위해서 head와 body 는 html의 브랜치(branch)라고도 일컬어진다. 이들은 자신들의 자식이 있기 때문에 브랜치이다. 트리의 말단에 다다르면 "Trees, trees, everywhere"와 "really" 같은 텍스트로 가게 된다. 이들은 자식들이 없기 때문에 잎(leave)으로 일컬어진다. 이 용어들을 다 기억할 필요는 없고 특정 용어가 무엇을 의미하는지를 파악하려면 나무의 구조를 머리속에 그려보면 된다.
객체의 가치
기본적인 용어들을 익혔으니 엘리먼트 이름과 텍스트가 들어있는 작은 직사각형에 집중해 보자.(그림 1) 각 직사각형들은 객체이다. 여기에서 브라우저는 텍스트와 관련된 문제들을 해결한다. 객체를 사용하여 HTML 문서의 조각들을 나타냄으로서 구성을 변경하고, 스타일을 적용하며, JavaScript를 문서에 액세스 시키기가 매우 쉬워진다.
객체 유형과 속성
모든 가능한 유형의 마크업은 고유의 객체 유형을 갖는다. 예를 들어, HTML에 있는 엘리먼트는 Element 객체 유형에 의해 구현된다. 문서에 있는 텍스트는 Text 유형에 의해 구현된다. 애트리뷰트는 Attribute 유형에 의해 표현된다.
따라서 웹 브라우저는 객체 모델을 사용하여 문서를 표현하고?정적 텍스트를 다룰 필요가 없음?객체 유형에 따라 즉각 구분할 수 있다. HTML 문서는 파싱되고 그림 1의 객체들로 바뀐다. 그런 다음 대괄호 같은 이스케이프 시퀀스로 바뀐다. 이는 브라우저의 작업을 훨씬 쉽게 만든다. 적어도 인풋 HTML을 파싱한 후에도 말이다. 어떤 것이 엘리먼트이고 어떤 것이 애트리뷰트인지 파악하고 객체 유형을 어떻게 다룰지를 결정하는 작동은 간단하다.
객체들을 사용함으로서 웹 브라우저는 그러한 객체들의 속성들을 변경할 수 있다. 예를 들어, 각 엘리먼트 객체는 하나의 부모와 자식 리스트를 갖고 있다. 새로운 자식 엘리먼트나 텍스트를 추가하는 것은 새로운 자식을 엘리먼트의 자식 리스트에 추가하는 문제에 지나지 않는다. 이러한 객체들은 또한 style 속성을 갖고 있어서 엘리먼트의 스타일이나 텍스트 조각을 쉽게 변경할 수 있다. 예를 들어, 다음과 같이 JavaScript를 사용하여 div의 높이를 수정할 수 있다.
someDiv.style.height = "300px";
다시 말해서, 웹 브라우저는 이와 같이 객체 속성들을 사용하여 트리의 모양과 구조를 쉽게 변경한다. 이것을 복잡한 것과 비교해 보라. 속성과 구조가 변할 때 마다 브라우저는 정적 파일을 재작성 하고, 재 파싱 하고 이를 스크린에 다시 디스플레이 해야 한다. 이 모든 것이 객체로도 가능해진다.
이 시점에서 HTML 문서에 대해 알아보고 이를 트리로 그려보자. 평범한 요청은 아닌 것 같지만 이들을 다룰 수 있으려면 이러한 트리 구조에 익숙해져야 한다. 보통의 요청은 아닌 것 같지만 이 트리 구조에 익숙해져야 한다. 이들을 조작할 수 있으려면 말이다.
이 프로세스에서 몇 가지 이상한 점들을 발견하게 된다. 다음과 같은 상황을 생각해 보자.
애트리뷰트에는 어떤 일이 발생하는가?
em과 b 같은 엘리먼트로 나뉜 텍스트는 어떻게 되는가?
정확하게 구축되지 않은 HTML은 어떻게 되는가? (닫기 p 태그가 소실 되는 경우) 일단 이러한 유형의 문제에 익숙해지면 다음 섹션을 이해하기가 더 쉬울 것이다.
엄격함을 유지한다.
내가 언급했던 것을 직접 해본다면 마크업의 트리 뷰에 잠재적 문제 몇 가지들을 발견할 것이다. (직접 하지 않을 것이라면 내 말을 믿어라.) 사실, Listing 1과 그림 1에서 여러 가지를 발견할 것이다. p 엘리먼트가 나뉘어지는 방법부터 시작해서 말이다. 전형적인 웹 개발자에게 p 엘리먼트의 텍스트 콘텐트가 무엇인지를 묻는다면 일반적으로 "Welcome to a really boring Web page"라고 답할 것이다. 이것을 그림 1과 비교하면 이러한 대답이 논리적이긴 하지만 전혀 맞지 않다는 것을 알게 될 것이다.
p 엘리먼트는 세 개의 다른 자식 객체들을 갖고 있고, 이 중 어떤 것도 전체 "Welcome to a really boring Web page" 텍스트를 포함하고 있지 않다. "Welcome to a "와 " boring Web page" 같은 텍스트의 일부를 볼 수는 있어도 이것이 전체 문장은 아니다. 이를 이해하려면 마크업의 모든 것이 어떤 유형의 객체로 바뀌어야 한다는 것을 기억하라.
더욱이 순서도 문제가 된다. 정확한 마크업이지만 여러분의 HTML에서 제공된 순서와 다르다면 사용자가 웹 브라우저에 어떻게 대응할지를 상상할 수 있겠는가? 문서를 구성했던 방식이 아닐 때에도 제목과 헤딩 사이에 끼게 될 것이다. 브라우저는 엘리먼트와 텍스트의 순서를 보존해야 한다.
이 경우, p 엘리먼트는 세 개의 구별된 부분들을 갖는다.
- em 엘리먼트 앞에 오는 텍스트
- em 엘리먼트
- em 엘리먼트 뒤에 오는 텍스트
이 순서를 섞는다면 텍스트의 잘못된 부분에 강조를 적용한 것이다. 이 모든 것을 바로잡으려면 p 엘리먼트는 Listing 1의 HTML에 나타났던 순서 대로 세 개의 객체 자식들을 가져야 한다. 더욱이 강조된 텍스트인 "really"는 p의 자식 엘리먼트가 아니다. 이것은 p의 자식인 em의 자식이다.
이 개념을 이해하는 것은 매우 중요하다. "really" 텍스트가 나머지 p 엘리먼트의 텍스트와 함께 디스플레이 되더라도 이것은 여전히 em 엘리먼트의 직접적인 자식이다. 이것은 나머지 p와는 다른 포맷팅을 가질 수 있고 나머지 텍스트와 개별적으로 움직일 수 있다.
이를 유념하면서 Listing 2와 3의 HTML을 다이어그램으로 그리면서 텍스트에 정확한 부모를 유지하도록 한다. 정확한 부모로 유지시킨다.
Listing 2. 약간의 트릭이 들어간 엘리먼트 중첩이 있는 마크업
<html>
<head>
<title>This is a little tricky</title>
</head>
<body>
<h1>Pay <u>close</u> attention, OK?</h1>
<div>
<p>This p really isn't <em>necessary</em>, but it makes the
<span id="bold-text">structure <i>and</i> the organization</span>
of the page easier to keep up with.</p>
</div>
</body>
</html>
Listing 3. 보다 트릭이 심한 엘리먼트의 중첩
<html>
<head>
<title>Trickier nesting, still</title>
</head>
<body>
<div id="main-body">
<div id="contents">
<table>
<tr><th>Steps</th><th>Process</th></tr>
<tr><td>1</td><td>Figure out the <em>root element</em>.</td></tr>
<tr><td>2</td><td>Deal with the <span id="code">head</span> first,
as it's usually easy.</td></tr>
<tr><td>3</td><td>Work through the <span id="code">body</span>.
Just <em>take your time</em>.</td></tr>
</table>
</div>
<div id="closing">
This link is <em>not</em> active, but if it were, the answers
to this <a href="answers.html"><img src="exercise.gif" /></a> would
be there. But <em>do the exercise anyway!</em>
</div>
</div>
</body>
</html>
이러한 관행에 대한 해답은 이 글 끝부분의 GIF 파일인 (그림 2)와 (그림 3)에서 찾을 수 있다. 스스로 알아내기 전에 몰래 보지 않기를 바란다. 엄격한 규칙이 트리를 구성하는데 어떻게 적용되는지를 이해하면 도움이 될 것이다. HTML과 트리 구조를 마스터 한다면 정말로 도움이 될 것이다.
애트리뷰트
애트리뷰트를 어떻게 다루어야 하는지를 파악할 때 문제가 생긴 적이 있는가? 앞서 언급했지만 애트리뷰트는 고유의 객체 유형을 갖고 있지만 애트리뷰트는 엘리먼트의 자식이 아니다. 중첩 엘리먼트와 텍스트는 같은 레벨의 애트리뷰트가 아니고 Listing 2와 3에 대한 답에는 애트리뷰트가 나타나지 않는다는 것을 알 수 있다.
사실 애트리뷰트는 브라우저가 사용하는 객체 모델에 저장되지만 이들은 특별한 경우이다. 각 엘리먼트는 여기에 사용되는 애트리뷰트 리스트를 갖고 있고 자식 객체의 리스트에서 분리된다. 따라서 div 엘리먼트는 "id" 애트리뷰트와 또 다른 이름 " class "를 포함하고 있는 리스트를 갖게 된다.
엘리먼트용 애트리뷰트가 유일한 이름을 갖고 있어야 한다는 것을 기억하라. 다시 말해서, 하나의 엘리먼트가 두 개의 "id" 또는 두 개의 "class"애트리뷰트를 가질 수 없다. 보존하고 액세스 할 리스트를 매우 쉽게 만든다. 다음 글에서 보겠지만 getAttribute("id") 같은 메소드를 호출하여 애트리뷰트 값을 이름 별로 얻을 수 있다. 애트리뷰트를 추가하고 기존 애트리뷰트의 값을 비슷한 메소드 호출을 설정(재설정)할 수 있다.
애트리뷰트의 독자성은 리스트를 자식 객체들의 리스트와 구별시킨다. p 엘리먼트는 그 안에 여러 em 엘리먼트를 갖고 있기 때문에 자식 객체의 리스트에는 중복 아이템이 포함될 수 있다. 자식 리스트와 애트리뷰트 리스트는 비슷하게 작동하지만 하나는 중복을 포함할 수 있고(객체의 자식) 하나는 그럴 수 없다는 것이다. (엘리먼트 객체의 애트리뷰트) 마지막으로 엘리먼트만이 애트리뷰트를 가질 수 있기 때문에 텍스트 객체는 여기에 첨부될 리스트가 없다.
어지러운 HTML
더 진행하기에 앞서 브라우저가 마크업을 트리 구현으로 변환하는 방법, 브라우저가 엉성한 폼의 마크업을 어떻게 다루는지를 볼 필요가 있다. 구성이 잘되었다(Well-formed)는 용어는 XML에서 광범위하게 사용되고 두 가지 기본적인 의미가 있다.
모든 오프닝 태그는 여기에 매칭되는 클로징 태그를 갖고 있다. 따라서 모든 <p>는 </p>와 <div>는 </div>와 매칭된다.
가장 안쪽의 오프닝 태그는 가장 안쪽의 클로징 태그와 매칭된다. 그 다음 안쪽의 오프닝 태그는 그 다음 안쪽의 클로징 태그와 매칭되는 식이다. 따라서 <b><i>bold and italics</b></i>는 옳지 않다. 가장 안쪽의 오프닝 태그인 <i>가 <b>와는 맞지 않기 때문이다. 이를 잘 구성하려면 오프닝 태그 순서를 바꾸거나 클로징 태그 순서를 바꾼다. (둘 다 바꾼다면 똑 같은 문제가 생긴다.)
이 두 가지 규칙들을 자세히 연구해 보자. 두 규칙 모두 문서의 간단한 구성을 늘릴 뿐만 아니라 모호함을 제거한다. Bolding이 먼저 적용되고 그 다음에 italics를 적용해야 하는가? 아니면 그 반대인가? 순서와 다의성이 큰 문제인 것처럼 보이지만 CSS에서는 이 규칙들이 다른 규칙들을 무시할 수 있도록 한다. 따라서 b 엘리먼트 안에 있는 텍스트의 폰트가 i 엘리먼트 내의 폰트와 다르다면 포맷팅이 적용되는 순서는 매우 중요하다. 따라서 HTML 페이지의 좋은 구성이 중요한 것이다.
잘 구성되지 않은 문서를 브라우저가 받는 경우 할 수 있는 최선을 다한다. 결과 트리 구조는 가장 좋은 경우는 원래 페이지 작성자가 의도했던 것과 비슷한 것이고 최악의 경우 완전히 다른 것이다. 브라우저에 페이지를 로딩하고 기대했던 것과 완전히 다른 일이 발생한다면 구조에 대해 다시 생각해 봐야 한다. 물론 픽스는 간단하다. 문서가 잘 구성되었는지를 확인하는 것이다. 표준화된 HTML을 작성하는 방법을 모르겠다면 참고자료를 참조하라.
DOM
지금 까지, 브라우저가 웹 페이지를 객체 구현으로 변환하는 것에 대해 배웠다. 아마도 여러분은 객체 구현이 DOM 트리라고 생각해왔을 것이다. DOM은 문서 객체 모델(Document Object Model)을 의미하고 World Wide Web Consortium (W3C)에서 사용할 수 있는 스팩이다.(참고자료 참조)
DOM은 브라우저가 마크업을 나타낼 수 있도록 하는 객체의 유형과 속성들을 정의한다. (다음 글에서는 JavaScript와 Ajax 코드에서 DOM을 사용하는 방법을 설명하겠다.)
문서 객체
무엇보다도 객체 모델에 액세스 해야 한다. 이것은 매우 쉽다. 웹 페이지에서 실행되는 JavaScript 코드 조각에 있는 빌트인 document 변수를 사용하려면 다음과 같이 코드를 작성한다.
var domTree = document;
물론 이 코드는 그 자체로는 쓸모가 없지만 모든 웹 브라우저가 document 객체를 JavaScript 코드에 사용할 수 있도록 하고 객체는 완벽한 마크업 트리를 나타낸다.(그림 1)
모든 것이 노드이다!
확실히, document 객체는 중요하지만 단지 시작에 불과하다. 더 진행하기 전에 또 다른 용어인 노드(node) 개념을 익혀야 한다. 마크업의 각 부분이 객체에 의해 구현되지만 이는 하나의 객체(특정 유형의 객체)인 DOM 노드에 불과하다는 것을 이미 알 것이다. 보다 특별한 유형인 텍스트, 엘리먼트, 애트리뷰트는 이러한 기본적인 노드 유형에서 확장된다. 따라서 여러분은 텍스트 노드, 엘리먼트 노드, 애트리뷰트 노드를 갖고 있는 것이다.
JavaScript로 프로그래밍을 했다면 DOM 코드를 사용하는 방법도 알 것이다. 이 Ajax 시리즈를 충실히 이행했다면 여러분도 DOM 코드를 사용한 것이다. 예를 들어, var number = document.getElementById("phone").value; 라인은 DOM을 사용하여 특정 엘리먼트를 찾아 그 엘리먼트의 값(이 경우 폼 필드)을 가져온다. 따라서 여러분이 인식 못했더라도 여러분은 document를 JavaScript 코드에 타이핑 할 때마다 DOM을 사용한 것이었다.
여러분이 배웠던 용어를 정비하기 위해 DOM 트리는 객체의 트리지만 보다 구체적으로는 노드 객체들의 트리이다. Ajax 애플리케이션 또는 JavaScript에서 그러한 노드들과 작업하여 엘리먼트와 이것의 콘텐트를 지우고 특정 텍스트 조각을 강조하고 새로운 이미지 엘리먼트를 추가하는 등 특별한 효과를 만들 수 있다. 이 모든 것은 클라이언트 측(웹 브라우저에서 실행되는 코드)에서 발생하기 때문에 이러한 효과는 서버와 통신 없이 즉시 발생한다. 결국 보다 반응성 있는 애플리케이션이 될 것이다.
대부분의 프로그래밍 언어에서 각 노드 유형에 맞는 실제 객체 이름들을 배우고 속성들을 배우고 유형과 캐스팅을 파악해야 한다. 하지만 이중 어떤 것도 JavaScript에서는 필요하지 않다. 변수를 만들어서 여기에 원하는 객체를 할당한다.
var domTree = document;
var phoneNumberElement = document.getElementById("phone");
var phoneNumber = phoneNumberElement.value;
변수를 만들고 여기에 정확한 유형을 핸들하는 유형과 JavaScript는 없다. 결과적으로 JavaScript에서 DOM을 사용하기가 매우 쉬워진다. (다음 글에서는 XML과 관련한 DOM에 초점을 맞춰 설명하겠다.)
결론
지금 여기에서 설명한 것이 DOM의 전부는 아니다. 사실 이 글은 DOM의 개요서에 지나지 않는다. 오늘 설명한 것 이상의 것이 DOM에는 있다.
다음 글에서는 JavaScript에서 DOM을 사용하여 웹 페이지를 만들고 HTML을 수정하고 사용자 인터랙션을 높이는 방법을 설명하겠다. DOM을 주제로 다시 한면 설명하겠다. Ajax 애플리케이션의 중요한 부분인 DOM에 익숙해지기 바란다.
바로 지금 DOM을 더 깊이 연구할 수 있다. DOM 트리로 옮기는 방법, 엘리먼트와 텍스트의 값을 얻는 방법, 노드 리스트를 통해 반복하는 방법 등을 자세히 설명하겠다.
무엇보다도 트리 구조에 대해 생각해 보고 HTML을 통해서 웹 브라우저가 HTML을 마크업의 트리 뷰로 어떻게 전환하는지에 대해 생각해 보고 다음 글에 임하기 바란다. 또한, DOM 트리의 구성을 생각해 보고 이 글에 설명된 특별한 경우를 생각해 보라. 애트리뷰트, 그 안에 엘리먼트와 혼합된 텍스트, 텍스트 콘텐트를 갖고 있지 않은 엘리먼트(img 엘리먼트) 등을 생각해 보라.
이러한 개념을 확실히 이해하고 JavaScript와 DOM의 신택스를 배운다면 도움이 될 것이다.
여기 Listing 2와 2에 대한 답을 제시하겠다. 샘플 코드도 포함되어 있다.
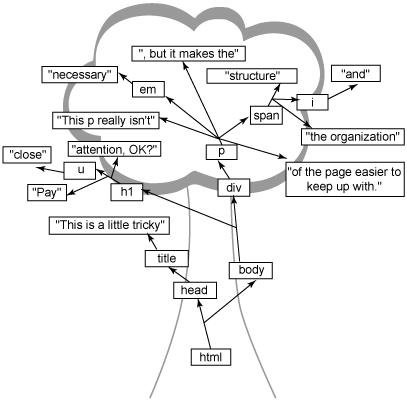
그림 2. Listing 2에 대한 답
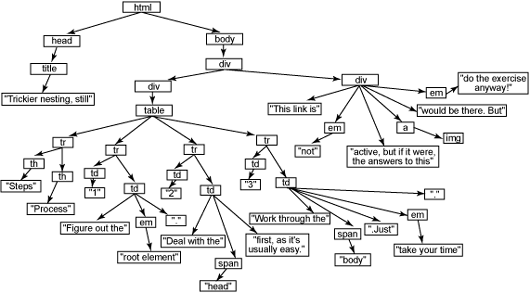
그림 3. Listing 3에 대한 답
참고자료
교육
- developerWorks Ajax series :
- "Ajax 마스터, Part 1: Ajax 소개" (December 2005).
- "Ajax 마스터하기, Part 2: JavaScript와 Ajax를 이용한 비동기식 요청"(January 2006).
- "Ajax 마스터하기, Part 3: Ajax의 고급 요청 및 응답" (February 2006).
- DOM Home Page
- DOM Level 3 Core Specification.
- ECMAScript language bindings for DOM
- "자바 개발자를 위한 Ajax: 동적 자바 애플리케이션 구현"(developerWorks, September 2005).
- "자바 개발자를 위한 Ajax: Ajax용 자바 객체 직렬화" (developerWorks, October 2005).
- "Call SOAP Web services with Ajax, Part 1: Build the Web services client:" (developerWorks, October 2005).
- "Ajax: A New Approach to Web Applications:"
- HTTP status codes.
- Head Rush Ajax by Elisabeth Freeman, Eric Freeman, and Brett McLaughlin (February 2006, O'Reilly Media, Inc.)
- Java and XML, Second Edition by Brett McLaughlin (August 2001, O'Reilly Media, Inc.)
- JavaScript: The Definitive Guide by David Flanagan (November 2001, O'Reilly Media, Inc.)
- Head First HTML with CSS & XHTML by Elizabeth and Eric Freeman (December 2005, O'Reilly Media, Inc.)
- developerWorks Web architecture zone
- developerWorks technical events and Webcasts
제품 및 기술 얻기
-IBM trial software
토론
-developerWorks blogs.
Brett McLaughlin, Author and Editor | O'Reilly Media Inc.
원문 :http://www.dbguide.net/know/know102001.jsp?mode=view&divcateno=14&divcateno_=14&pg=1&idx=3056
지난 달에는 웹 페이지를 정의하는 문서 객체 모델을 소개했습니다. 이번 달에는 돔을 보다 자세히 연구합니다. 돔 트리의 부분들을 생성, 제거, 변경하는 방법을 설명하고 그 다음 단계인 웹 페이지를 업데이트 하는 방법을 설명합니다.
지난 회에는 웹 브라우저가 웹 페이지들 중 하나를 디스플레이 할 때 어떤 일이 일어나는지에 대해 설명했다. 페이지에 정의했던 HTML과 CSS가 웹 브라우저로 보내지면 이것은 텍스트에서 객체 모델로 변환된다. 코드가 단순하건 복잡하건 간에, 하나의 파일에 저장하든 또는 개별 파일들에 모든 것을 저장하든 간에 이것은 사실이다. 브라우저는 제공된 텍스트 파일 보다는 객체 모델을 사용한다. 브라우저가 사용하는 모델을 문서 객체 모델(Document Object Model)이라고 한다. 이것은 문서에 있는 엘리먼트, 애트리뷰트, 텍스트를 나타내는 객체들을 연결한다. HTML과 CSS에 있는 모든 스타일, 값, 심지어 거의 모든 공간들은 객체 모델로 통합된다. 웹 페이지에 대한 특정 모델은 그 페이지의DOM 트리라고 한다.
DOM 트리가 무엇인지를 이해하고 이것이 어떻게 HTML과 CSS를 나타내는지를 아는 것이 웹 페이지를 제어하는 첫 번째 단계이다. 그런 다음에는 특정 웹 페이지에 DOM 트리를 사용하여 작동시키는 방법을 배워야 한다. 예를 들어, 한 엘리먼트를 DOM 트리에 추가하면 그 엘리먼트는 페이지 리로딩 없이 사용자의 웹 브라우저에 즉시 나타난다. DOM 트리에서 몇몇 텍스트를 제거하면 그 텍스트는 사용자의 스크린에서 사라진다. 여러분은 DOM을 통해서 사용자 인터페이스를 변경할 수 있고 인터랙팅 할 수 있다. 이것은 실로 엄청난 프로그래밍의 힘과 유연성을 제공해 준다. 일단 DOM 트리로 작업하는 방법을 배우면 풍부하고 동적인 인터랙티브 웹 사이트를 마스터하는 단계로 넘어갈 수 있다.
지난 회 "웹 응답에 DOM 활용하기"를 참조하라. 아직 읽어 보지 않았다면 이 글을 읽기 전에 일어보기 바란다.
크로스 브라우저, 크로스 언어
Document Object Model은 W3C 표준이다. (참고자료 참조) 따라서 모든 현대의 웹 브라우저는 DOM을 지원하고 있다. 브라우저 간 차이는 있겠지만 핵심 DOM 기능을 사용한다면-그리고 특별한 케이스와 예외에 주의를 기울이면- 여러분의 DOM 코드는 어떤 브라우저 상에서도 같은 방식으로 작동할 것이다. Opera의 웹 페이지를 수정하기 위해 여러분이 작성한 코드는 Apple의 Safari??, Firefox??, Microsoft?? Internet Explorer??, Mozilla?? 상에서도 실행될 것이다.
DOM은 크로스 언어(cross-language) 스팩이기도 하다. 다시 말해서 대부분의 프로그래밍 언어에서 이것을 사용할 수 있다. W3C는 DOM을 위한 여러 언어 바인딩을 정의하고 있다. 언어 바인딩은 단순한 API로서 특정 언어에 DOM을 사용할 수 있도록 해준다. 예를 들어, C, Java, JavaScript용으로 정의가 잘 된 DOM 언어 바인딩을 찾아볼 수 있다. 따라서 여러분은 어떤 언어에서도 DOM을 사용할 수 있다. 언어 바인딩 역시 여러 다른 언어에도 사용할 수 있다. 비록 이 언어들이 W3C가 아닌 삼자에 의해 정의되더라도 말이다.
이 시리즈에서 나는 JavaScript 바인딩에 초점을 맞출 것이다. 대부분의 비동기식 애플리케이션 개발이 JavaScript 코드를 작성하여 웹 브라우저에서 실행하기 때문이다. JavaScript와 DOM을 사용하여 사용자 인터페이스를 수정할 수 있고 사용자 이벤트와 인풋에 대응할 수 있다. 이 모두가 완전히 표준화된 JavaScript를 사용한다.
다른 언어로 된 DOM 언어 바인딩도 검토해보기 바란다. 예를 들어, 자바 언어 바인딩을 사용하여 HTML 뿐만 아니라 XML로도 작업할 수 있다. 따라서 여기에서 배운 레슨을 HTML 외에도 적용할 수 있고 클라이언트 측 JavaScript 말고도 여러 환경에 적용할 수 있다.
약어 문제
Document Object Model은 그 동안 Document Node Model로 불려졌다. 물론 대부분의 사람들은 노드(node)라는 단어가 무엇을 의미하는지 모르고, "DNM"은 "DOM"만큼 발음하기 쉬운 것도 아니기 때문에 W3C에서도 DOM이라는 용어를 채택했다.
개념상의 노드
노드는 DOM에서 가장 기본적인 객체 유형이다. 사실, 이 글에서 밝혀지겠지만 DOM에 의해 정의된 거의 모든 객체는 노드 객체를 확장한다. 하지만 의미론으로 들어가기 전에 노드의 개념을 이해해야 한다. 그렇게 하면 실제 속성과 노드의 방식을 배우는 것은 식은 죽 먹기다.
DOM 트리에서 여러분이 만나게 되는 거의 모든 것이 노드이다. 가장 기본적인 레벨에 있고, DOM 트리에 있는 노드이다. 모든 애트리뷰트는 하나의 노드이다. 모든 텍스트 조각도 하나의 노드이다. 심지어 코멘트, (카피라이트 상징을 나타내는 © 같은) 특별 문자도 모두 노드이다. 이러한 개별 유형들의 특성을 설명하기 전에, 여러분은 노드가 무엇인지를 이해해야 한다.
노드란..
간단히 말해서, 노드는 DOM 트리에 있는 그저 단순한 하나의 존재이다. "존재(thing)"라고 한 것은 다분히 의도적이다. 예를 들어, HTML에 있는 엘리먼트 img와 HTML의 텍스트 조각인 "Scroll down for more details"는 많은 공통점이 있다. 하지만 그러한 개별 유형의 기능에 대해 생각하기 때문에 이들이 어떻게 다른지에 초점을 맞추겠다.
DOM 트리에 있는 각 엘리먼트와 텍스트 조각이 부모를 갖고 있다고 생각해 보자. 부모는 또 다른 엘리먼트의 자식일 수도 있고(img가 p 엘리먼트 안에 중첩될 때) 또는 DOM 트리의 가장 위에 있는 엘리먼트일 수 있다. (이것은 각 문서에 대해 단 한번의 특별한 경우이고 이곳에서 html 엘리먼트를 사용한다.) 또한 엘리먼트와 텍스트 모두 type을 갖고 있다고 생각해 보라. 한 엘리먼트의 type은 분명히 하나의 엘리먼트이다. 텍스트의 type은 텍스트이다. 각 노드는 또한 정의가 잘된 구조를 갖고 있다. 이 밑에 자식 엘리먼트 같은 하나의 노드(또는 노드들)을 갖는가? 이것이 자매 노드(sibling node) (엘리먼트나 텍스트 옆에 있는 노드)를 갖는가? 각 노드에는 어떤 문서에 속하는가?
다분히 추상적으로 들린다. 사실 엘리먼트의 유형은 음… 엘리먼트이다 라고 말하는 것은 어리석어 보인다. 하지만 일반 객체 유형으로서 노드를 갖는다는 것의 가치는 추상적으로 이해해야 한다.
공통 노드 유형
여러분의 DOM 코드에서 그 어떤 것 보다 많이 수행하는 일은 도움 트리 안을 검색하는 것이다. 예를 들어, "id" 애트리뷰트 별로 form을 배치하고 그 form 안에 중첩된 엘리먼트와 텍스트로 작업하기 시작한다. 텍스트 명령어, 인풋 필드용 레이블, 실제 input 엘리먼트, img 엘리먼트와 링크(a 엘리먼트) 같은 HTML 엘리먼트가 있을 것이다. 엘리먼트와 텍스트가 완전히 다른 유형유형이라면 여러분은 완전히 다른 코드를 작성하여 한 유형에서 다른 유형으로 옮겨가야 한다.
공통 노드 유형을 사용한다면 상황은 달라진다. 이 경우 노드에서 노드로 간단히 움직일 수 있고 엘리먼트나 텍스트의 특정의 것을 수행하고 싶을 때에만 노드의 유형을 생각하면 된다. DOM 트리 주위로 이동할 때 같은 연산을 사용하여 엘리먼트의 부모 또는 자식으로 이동한다. 엘리먼트의 애트리뷰트 같은 특정 노드 유형에서 구체적인 작업이 필요하다면 엘리먼트나 텍스트 같은 하나의 노드 유형에 대해서만 작업하면 된다. DOM 트리에 있는 각 객체를 하나의 노드로 생각하면 훨씬 간단하게 작업할 수 있다. 이제부터는 DOM Node 구조가 정확히 무엇을 제공하는지를 설명하겠다. 속성과 메소드부터 시작한다.
노드의 속성
DOM 노드와 작업할 때 여러 속성과 메소드를 사용한다면 다음 사항들을 먼저 생각해야 한다. 다음은 DOM 노드의 핵심 속성이다.
nodeName은 노드의 이름을 나타낸다. (아래 참조)
nodeValue:는 노드의 "값"을 제공한다. (아래 참조)
parentNode는 노드의 부모를 리턴한다. 모든 엘리먼트, 애트리뷰트, 텍스트는 부모 노드를 갖고 있다는 것을 기억하라.
childNodes는 노드의 자식들의 리스트이다. HTML로 작업할 때 엘리먼트를 다룰 경우 이 리스트는 유용하다. 텍스트 노드와 애트리뷰트 노드는 어떤 자식도 갖지 않는다.
firstChild는 childNodes 리스트에 있는 첫 번째 노드로 가는 지름길이다.
lastChild도 또 다른 지름길이다. childNodes 리스트에 있는 마지막 노드로 가는 지름길이다.
previousSibling은 현재 노드 앞에 있는 노드를 리턴한다. 다시 말해서, 현재 것 보다 앞에 있는 노드를 리턴한다. 현재 노드의 부모의
childNodes 리스트에 있는 것 보다 선행하는 노드를 리턴한다. (헷갈린다면 마지막 문장을 다시 한번 더 읽어라.)
nextSibling은 previousSibling 속성과 비슷하다. 부모의 childNodes 리스트에 있는 다음 노드로 돌린다.
attributes는 엘리먼트 노드에서 유일하게 유용한 것이다. 엘리먼트의 애트리뷰트 리스트를 리턴한다.
몇몇 다른 속성들은 보다 근본적인 XML 문서로 적용되고 HTML 기반의 웹 페이지로 작업할 때 많이 사용되지 않는다.
특별한 속성
위에서 정의된 대부분의 속성들이 다분히 설명적이다. nodeName과 nodeValue 속성을 빼면 말이다. 이러한 속성들을 설명하지 않고 대신 기이한 질문 두 가지를 생각해 보자. 텍스트 노드용 nodeName은 무엇인가? 혹은 엘리먼트용 nodeValue는 무엇이 될까?
이러한 질문들이 당황스럽다면 이러한 속성들에 내재해 있는 혼돈을 이미 이해하고 있는 것이다. nodeName과 nodeValue는 실제로 모든 노드 유형에 적용되는 것은 아니다. (한 노드 상의 다른 속성들의 경우도 마찬가지다.) 이 속성들은 null 값을 리턴할 수 있다. (JavaScript에서는 "undefined"로 나타난다.) 예를 들어, 텍스트 노드용 nodeName 속성은 무효이다. (또는 어떤 브라우저에서는 "undefined"이다. 텍스트 노드는 이름이 없기 때문이다. nodeValue는 노드의 텍스트를 리턴한다.)
비슷하게, 엘리먼트는 nodeName --엘리먼트의 이름--을 갖고 있지만 엘리먼트의 nodeValue 속성의 값은 언제나 무효이다. 애트리뷰트는 nodeName과 nodeValue, 이 두 가지 속성에 대한 값을 갖는다. 이 개별 유형들을 다음 섹션에서는 자세히 설명하도록 하겠다.
Listing 1은 실행 중인 여러 노드 속성들을 보여주고 있다.
Listing 1. DOM에서 노드 속성 사용하기
// These first two lines get the DOM tree for the current Web page, // and then the element for that DOM tree
var myDocument = document;
var htmlElement = myDocument.documentElement;
// What's the name of the element? "html"
alert("The root element of the page is " +htmlElement.nodeName);
// Look for the element
var headElement = htmlElement.getElementsByTagName("head")[0];
if (headElement != null) {
alert("We found the head element, named " +headElement.nodeName);
// Print out the title of the page
var titleElement = headElement.getElementsByTagName("title")[0];
if (titleElement != null) {
// The text will be the first child node of the
var bodyElement = headElement.nextSibling;
while (bodyElement.nodeName.toLowerCase() != "body") {
bodyElement = bodyElement.nextSibling;
}
// We found the element...
// Remove all the top-level![]() elements in the body
elements in the body
if (bodyElement.hasChildNodes()) {
for (i=0; ivar currentNode = bodyElement.childNodes[i];
if (currentNode.nodeName.toLowerCase() == "img") {
bodyElement.removeChild(currentNode);
}
}
}
}
}
:badtag -->
JavaScript and DOM are a perfect match.
You can read more inHead Rush Ajax.

이 페이지를 브라우저로 로딩하면 그림 1과 같이 된다.
그림 1. JavaScript를 실행하는 버튼이 있는 간단한 HTML 페이지
Click Test me!를 클릭하면 경고 박스가 나타난다. (그림 2)
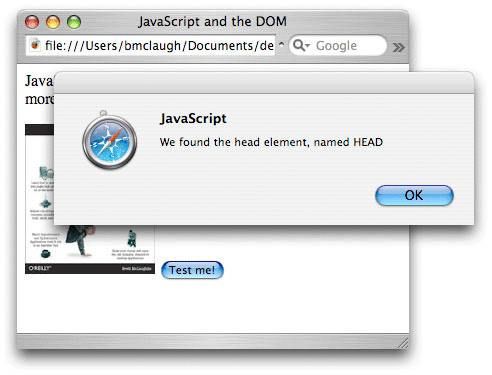
그림 2. nodeValue를 사용하여 엘리먼트의 이름을 보여주는 경고 박스
코드 실행이 종료되면 이미지가 페이지에서 실시간으로 제거된다. (그림 3)
그림 3. JavaScript를 사용하여 실시간으로 제거되는 이미지
API 디자인 설명
각 노드에서 사용할 수 있는 속성과 메소드를 다시 한 번 보자. 이것은 객체 지향(OO) 프로그래밍에 익숙한 사람들을 위해 DOM의 핵심 포인트를 나타낸다. DOM은 객체 지향 API가 아니다. 우선, 많은 경우 여러분은 노드 객체에 메소드를 호출하기 보다는 객체의 속성들을 직접적으로 사용할 것이다. 예를 들어, getNodeName() 메소드가 없다. 다만 nodeName 속성을 직접 사용한다. 따라서 노드 객체들은(그리고 다른 DOM 객체들은) 함수가 아닌 속성들을 통해 많은 데이터를 노출한다.
두 번째로, DOM의 객체와 메소드의 네이밍은 약간 낯설다. 만약 여러분이 객체와 객체 지향 API로 작업했다면 그렇게 느낄 것이다. (특히 자바나 C++). DOM은 C, 자바, JavaScript)에서 작동하기 때문에 일부 잉여물들이 API 디자인에 만들어 진다. 예를 들어, NamedNodeMap 메소드에 있는 두 개의 다른 메소드를 보자.
- getNamedItem(String name)
- getNamedItemNS(Node node)
OO 프로그래머에게는 이것은 매우 이상해 보인다. 같은 목적을 갖고 있는 두 개의 메소드지만 하나는 String을 또 하나는 Node를 취한다. 대부분의 OO API에서 두 버전에 같은 메소드 이름을 사용한다. 코드를 실행하는 가상 머신은 메소드로 전달된 객체 유형에 기반하여 어떤 메소드를 실행할 것인지를 규명한다.
문제는 JavaScript가 메소드 오버로딩(method overloading)이라는 기술을 지원하지 않는다는 점이다. 다시 말해서, JavaScript에서는 주어진 이름에 대해 하나의 메소드나 함수를 가져야 한다는 의미이다. 따라서 스트링을 취하는 getNamedItem() 메소드를 갖고 있다면 getNamedItem()이라는 이름의 다른 메소드나 함수를 가질 수 없다. 두 번째 버전이 다른 유형의 인자를 취하더라도 말이다. (또는 완전히 다른 인자를 취해도 마찬가지다.) 그럴 경우 JavaScript는 에러를 보고하고 코드는 작동하지 않는다.
본질적으로 DOM은 메소드 오버로딩과 다른 OO 프로그래밍 기술들을 피한다. OO 프로그래밍 기술을 지원하지 않는 언어를 포함하여 API는 여러 언어들을 통해서 작동한다는 확신 때문이다. 결국 몇 가지 추가적인 메소드 이름을 배워야 한다는 것이다. 예를 들어 자바 같은 언어에서 DOM을 배울 수 있고 같은 메소드 이름과 코딩 구조가 자바스크립트 같은 DOM 구현을 가진 다른 언어들에도 작동할 것이라는 것을 알 수 있다.
프로그래머를 조심시켜라!
여러분이 API 디자인에 몰두해 있다면 궁금할 것이다. "왜 속성은 모든 노드에 대해 공통적이지 않는가?" 이것은 기술적인 이유 보다는 정치적이고 의사 결정에 관한 것이다. 간단히 말해서 정답은, "누가 알겠는가! 너무 귀찮다." 라고 밖에 말할 수 없다.
nodeNamenodeName 속성은 모든 유형이 이름을 가질 수 있도록 하고 있다. 하지만 많은 경우 그 이름은 정의되지 않았거나 프로그래머에게는 어떤 가치도 없는 낯선 이름이다. (예를 들어, 자바에서 텍스트 노드의 nodeName은 많은 경우 "#text"로 리포팅 된다. 근본적으로 에러 핸들링은 여러분에게 남겨지게 된다. 단순히 myNode.nodeName에 액세스 하여 그 값을 사용하는 것은 안전한 방법이 아니다. 많은 경우 그 값은 무효가 될 것이다. 따라서 프로그래밍에 이것이 적용될 때 프로그래머들이 주의해야 한다.
일반 노드 유형들
DOM 노드의 기능과 속성에 대해 알아보았으니 이제 여러분이 작업 할 특정 유형의 노드에 대해 배울 차례이다. 대부분의 웹 애플리케이션에서 네 가지 유형의 노드로 작업한다.
문서 노드는 전체 HTML 문서를 나타낸다.
앨리먼트 노드는 a 또는 img 같은 HTML 엘리먼트를 나타낸다.
애트리뷰트 노드는 href (a 엘리먼트에 대해) 또는 src (img 엘리먼트에 대해) 같은 HTML 엘리먼트에 대한 애트리뷰트를 나타낸다.
텍스트 노드는 "Click on the link below for a complete set list" 같은 HTML 문서에 있는 텍스트를 나타낸다. 이는 p, a, h2 같은 엘리먼트 내부에 나타나는 텍스트이다.
HTML을 다룰 때 거의 모든 시간을 이러한 노드 유형으로 작업한다. 이제부터 이 부분을 상세히 설명하겠다. (향후 기술 자료에서는 XML에 대해 설명하겠다.)
문서 노드
첫 번째 노드 유형은 DOM 기반 코드의 거의 모든 부분에서 여러분이 사용하게 될 유형이다. 바로 문서 노드이다. 문서 노드는 실제로 HTML(또는 XML) 페이지에 있는 엘리먼트가 아니라 페이지 그 자체이다. 따라서 HTML 웹 페이지에서 문서 노드는 전체 DOM 트리이다. 자바스크립트에서 document 키워드를 사용하여 문서 노드에 액세스 할 수 있다.
// These first two lines get the DOM tree for the current Web page,
// and then the element for that DOM tree
var myDocument = document;
var htmlElement = myDocument.documentElement;
자바스크립트의 document 키워드는 현재 웹 페이지에 대한 DOM 트리를 리턴한다. 여기에서부터 여러분은 트리에 있는 모든 노드들과 작업할 수 있다.
또한 document 객체를 사용하여 다음과 같은 메소드를 사용하는 새로운 노드를 만들 수 있다.
createElement(elementName)는 제공된 이름을 가진 엘리먼트를 만든다.
createTextNode(text)는 제공된 텍스트를 가진 새로운 텍스트 노드를 만든다.
createAttribute(attributeName)는 제공된 이름을 가진 새로운 애트리뷰트를 만든다.
여기에서 주목해야 할 것은 이러한 메소드들이 노드를 만들지만 이들을 첨부하거나 이들을 특정 문서에 삽입하지 않는다는 점이다. 따라서 이미 봤던 insertBefore() 또는 appendChild() 같은 메소드들 중 하나를 사용해야 한다. 따라서 다음과 같은 코드를 사용하여 새로운 엘리먼트를 만들어 문서에 붙여야 한다.
var pElement = myDocument.createElement("p");
var text = myDocument.createTextNode("Here's some text in a p element.");
pElement.appendChild(text);
bodyElement.appendChild(pElement);
document 엘리먼트를 사용하여 웹 페이지의 DOM 트리에 액세스 하면 엘리먼트, 애트리뷰트, 텍스트와 직접 작업할 준비가 된 것이다.
엘리먼트 노드
엘리먼트 노드와 많이 작업했지만 엘리먼트에 대해 수행해야 하는 많은 연산들에는 엘리먼트에만 해당하는 메소드와 속성 보다는 모든 노드들에 공통적인 메소드와 속성들이 포함된다. 단 두 개의 메소드 세트만 엘리먼트에 관한 것이다.
1. 애트리뷰트와 작동하는 것과 관련된 메소드: :
getAttribute(name)는 name이라는 애트리뷰트의 값을 리턴한다.
removeAttribute(name)는 name이라는 애트리뷰트를 제거한다.
setAttribute(name, value)는 name이라는 애트리뷰트를 만들고 이것의 값을 value로 설정한다.
getAttributeNode(name)는 name라고 하는 애트리뷰트 노드를 리턴한다. (애트리뷰트 노드는 아래에서 설명한다.)
removeAttributeNode(node)는 제공된 노드와 매치되는 애트리뷰트 노드를 제거한다.
2. 중첩된 엘리먼트를 찾는 메소드: :
getElementsByTagName(elementName)는 제공된 이름을 가진 엘리먼트 노드의 리스트를 리턴한다.
설명으로도 충분하지만 몇 가지 예제를 보도록 하자.
애트리뷰트 작업
애트리뷰트 작동은 매우 단순하다. 예를 들어, 도큐먼트 객체로 새로운 img 엘리먼트를 만들고, 엘리먼트, 위에서 몇 가지 메소드를 만든다.
var imgElement = document.createElement("img");
imgElement.setAttribute("src", "http://www.headfirstlabs.com/Images/hk240000000085.jpg");
imgElement.setAttribute("width", "130");
imgElement.setAttribute("height", "150");
bodyElement.appendChild(imgElement);
지금까지는 평범해 보인다. 사실 노드의 개념을 이해하고 사용할 수 있는 메소드를 알면 웹 페이지와 자바스크립트 코드에서 DOM으로 작업하는 것은 단순하다. 위 코드에서 자바스크립트는 새로운 img 엘리먼트를 만들고 애트리뷰트를 설정한 다음 이것을 HTML 페이지의 바디에 추가한다.
중첩 엘리먼트 찾기
중첩된 엘리먼트를 찾기도 쉽다. 예를 들어, Listing 3의 HTML 페이지에서 모든 img엘리먼트를 찾아 제거하는데 사용했던 코드가 있다.
// Remove all the top-level![]() elements in the body
elements in the body
if (bodyElement.hasChildNodes()) {
for (i=0; ivar currentNode = bodyElement.childNodes[i];
if (currentNode.nodeName.toLowerCase() == "img") {
bodyElement.removeChild(currentNode);
}
}
}
getElementsByTagName()을 사용하여 비슷한 효과를 얻을 수 있다.
// Remove all the top-level![]() elements in the body var imgElements = bodyElement.getElementsByTagName("img"); for (i=0; i
elements in the body var imgElements = bodyElement.getElementsByTagName("img"); for (i=0; i
애트리뷰트 노드
DOM은 애트리뷰트를 노드로서 나타내고 여러분은 언제나 엘리먼트의 attributes 속성을 얻을 수 있다.
// Remove all the top-level![]() elements in the body
elements in the body
var imgElements = bodyElement.getElementsByTagName("img");
for (i=0; ivar imgElement = imgElements.item[i];
// Print out some information about this element
var msg = "Found an img element!";
var atts = imgElement.attributes;
for (j=0; jivar att = atts.item(j);
msg = msg + "\n " + att.nodeName + ": '" + att.nodeValue + "'";
}
alert(msg);
bodyElement.removeChild(imgElement);
}
attributes 속성은 실제로 엘리먼트 유형이 아닌 노드 유형에 있다. 이것은 코딩에 영향을 주지 않지만 알아둘 필요가 있다.
애트리뷰트 노드에서 작업하는 것이 가능하지만 엘리먼트 클래스에서 사용할 수 있는 메소드를 사용하여 애트리뷰트 작업을 하는 것이 더 쉽다. 메소드는 다음과 같다.
getAttribute(name)는 name이라는 애트리뷰트의 값을 리턴한다.
removeAttribute(name)는 name이라는 애트리뷰트를 제거한다.
setAttribute(name, value)는 name이라는 애트리뷰트를 만들고 이것의 값을 value로 설정한다.
이 세 개의 메소드들로 인해 여러분은 애트리뷰트 노드와 직접 작업할 필요가 없다. 대신 애트리뷰트와 이것의 값과 함께 간단한 스트링 속성을 설정 및 제거할 수 있다.
애트리뷰트의 이상한 측면
애트리뷰트는 DOM에 있어서는 조금 특별하다. 애트리뷰트는 다른 엘리먼트나 텍스트의 경우와는 달리 엘리먼트의 자식이 아니다. 다시 말해서 엘리먼트의 밑에 나타나지 않는다. 동시에 이것은 엘리먼트와 관계를 갖고 있다. 엘리먼트는 자신의 애트리뷰트를 소유한다. DOM은 노드를 사용하여 애트리뷰트를 나타내고 이들을 특별한 리스트를 통해 엘리먼트에 대해 사용할 수 있도록 한다. 따라서 엘리먼트는 DOM 트리의 일부지만 이들은 트리에는 나타나지 않는다. DOM 트리 구조의 나머지에 대한 애트리뷰트의 관계는 다소 어지럽다.
텍스트 노드
여러분이 걱정하고 있는 마지막 노드 유형이자 HTML DOM 트리로 작업하는 유형은 텍스트 노드이다. 텍스트 노드와 작업하기 위해 공통적으로 사용하게 될 거의 모든 속성들은 실제로 노드 객체에서도 사용할 수 있다. 사실 nodeValue 속성을 사용하여 텍스트 노드에서 텍스트를 얻을 수 있다.
var pElements = bodyElement.getElementsByTagName("p");
for (i=0; ivar pElement = pElements.item(i);
var text = pElement.firstChild.nodeValue;
alert(text);
}
몇 가지 다른 메소드들은 텍스트 노드만의 것이다. 이들은 노드에 있는 데이터를 추가하거나 쪼갠다.
appendData(text)는 여러분이 제공한 텍스트를 텍스트 노드의 기존 텍스트의 끝에 추가한다.
insertData(position, text)는 텍스트 노드의 중간에 데이터를 삽입할 수 있다. 이것은 지정된 위치에 여러분이 제공한 텍스트를 삽입한다.
replaceData(position, length, text)는 지정된 위치부터 시작하여 지정된 길이의 문자를 제거하고 여러분이 제공한 텍스트를 제거된 텍스트를 대신하여 메소드에 둔다.
노드의 유형
여러분이 작업할 노드 유형이 무엇인지에 대해 이미 알고 있다는 전제 하에 설명을 해왔다. 만일 DOM 트리를 통해 검색하고 일반 노드 유형들로 작업한다면 엘리먼트나 텍스트로 이동했는지의 여부를 모를 것이다. 아마도 p 엘리먼트의 모든 자식들을 갖게 되고, 텍스트, b 엘리먼트, 아니면 img 엘리먼트로 작업하는지 확신할 수 없다. 이 경우 더 많은 일을 하기 전에 어떤 유형의 노드를 가졌는지를 규명해야 한다.
다행히도 이것을 파악하기는 매우 쉽다. DOM 노드 유형은 여려 상수들을 정의한다.
Node.ELEMENT_NODE는 엘리먼트 노드 유형에 대한 상수이다.
Node.ATTRIBUTE_NODE는 애트리뷰트 노드 유형에 대한 상수이다.
Node.TEXT_NODE는 텍스트 노드 유형에 대한 상수이다.
Node.DOCUMENT_NODE는 문서 노드 유형에 대한 상수이다.
다른 노드 유형들도 많이 있지만 HTML을 처리할 때에는 이 네 가지 외에는 별로 다루지 않는다. 이들 상수의 값이 DOM 스팩으로 정의되었지만 의도적으로 남겨두었다. 여러분은 이 값으로 절대 직접 처리해서는 안된다. 바로 이것 때문에 상수가 있는 것이니까.
nodeType 속성
DOM 노드 유형에 대해 정의되었기 때문에 모든 노드에서 사용할 수 있는 nodeType 속성을 사용하여 노드를 위 상수와 비교할 수 있다.
var someNode = document.documentElement.firstChild;
if (someNode.nodeType == Node.ELEMENT_NODE) {
alert("We've found an element node named " + someNode.nodeName);
} else if (someNode.nodeType == Node.TEXT_NODE) {
alert("It's a text node; the text is " + someNode.nodeValue);
} else if (someNode.nodeType == Node.ATTRIBUTE_NODE) {
alert("It's an attribute named " + someNode.nodeName
+ " with a value of '" + someNode.nodeValue + "'");
}
이것은 매우 단순한 예제이지만 포인트가 있다. 노드의 유형을 얻는 것은 단순하다. 일단 어떤 유형인지를 알면 노드로 무엇을 할 것인지를 규명해야 한다. 하지만 노드, 텍스트, 애트리뷰트, 엘리먼트 유형이 무엇을 제공하는지 확실히 안다면 DOM 프로그래밍을 직접 할 준비가 된 것이다.
작업의 고통
nodeType 속성이 노드로 작업할 수 있는 티켓인 것처럼 들린다. 이것으로 여러분은 어떤 유형의 노드로 작업하고 있는지를 규명하고 그 노드를 다룰 코드를 작성할 수 있다. 문제는 위에 정의된 Node 상수들이 Internet Explorer 상에서는 올바르게 작동하지 않는다는 점이다. 따라서 Node.ELEMENT_NODE, Node.TEXT_NODE 또는 코드의 다른 상수를 사용한다면 Internet Explorer는 그림 4와 같은 에러를 리턴할 것이다.
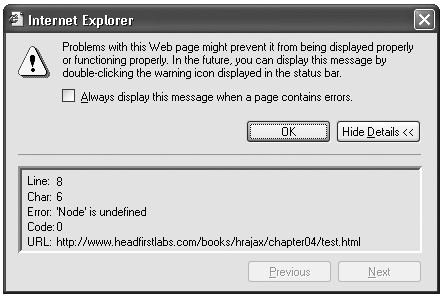
그림 4. Internet Explorer의 에러 리포팅
Internet Explorer는 여러분이 자바스크립트에서 Node 상수를 사용할 때 마다 이러한 에러를 보고 할 것이다. 거의 모든 사람들이 Internet Explorer를 사용하기 때문에 Node.ELEMENT_NODE 또는 Node.TEXT_NODE 같은 구조를 피해야 한다. Internet Explorer 7.0이 이러한 문제를 정정했다 하지만 Internet Explorer 6.x의 대중성에 미치려면 오랜 시간이 남았다. 따라서 Node 사용을 피해라. 여러분의 DOM 코드(그리고 Ajax 애플리케이션)가 모든 주요 브라우저에서 작동해야 하기 때문이다.
결론
본 시리즈를 통해 많은 것을 배웠다. 오늘 배운 것을 그냥 머리로 익히지만 말고 DOM 트리를 직접 사용해 볼 것을 권한다. DOM을 사용하여 멋진 효과나 그럴듯한 인터페이스를 만드는 방법을 연구해 보라. 여러분에게 내주는 숙제이다. 지난 두 개의 기술자료에서 배운 것을 실험해 보기 바란다. 사용자 액션에 대한 응답으로 스크린 상을 돌아다니는 것 같은 웹 사이트를 만든다는 것을 상상해 보라.
스크린 상의 모든 객체 주위의 보더를 없애기 때문에 여러분은 DOM 트리에서 객체들이 어디에 있는지 볼 수 있고 움직일 수 잇다. 노드를 만들고 이것을 기존 자식 리스트에 붙인다. 많은 중첩 노드들을 가진 노드들을 제거한다. CSS 스타일을 노드를 변경하고 그러한 변화가 자식 노드에 상속되었는지를 확인한다. 가능성은 무한하다. 새로운 것을 시도할 때 마다 새로운 것을 배운다. 웹 페이지를 즐겨라.
다음 글에서는 DOM의 멋진 애플리케이션들을 여러분의 프로그래밍과 결합하는 방법을 설명할 것이다. API에 대한 개념적인 설명은 그만두고 코드를 보여주겠다. 그때까지 자신 스스로 어떻게 할 것인지를 생각해 보라.
정상에 설 준비가 되었나요?
여러분이 진정 DOM을 완벽히 이해했다면 웹 프로그래밍 기술 레벨의 꼭대기에 오르게 될 것이다. 대부분의 웹 프로그래머들은 자바스크립트를 사용하여 이미지 롤오버를 작성하는 방법, 폼에서 값을 얻는 방법을 알고 있다. 심지어 서버에서 요청을 만들고 응답을 받는 사람들도 있다. 하지만 웹 페이지의 구조를 바꾸는 일은 소심한 사람이나 경험 없는 사람들은 피해주기 바란다.
참고자료
교육
- Ajax 마스터
- Part 1: Ajax 소개(developerWorks, December 2005) Ajax 마스터하기
- Part 2: JavaScript와 Ajax를 이용한 비동기식 요청 (developerWorks, January 2006) Ajax 마스터하기
- Part 3: Ajax의 고급 요청 및 응답(developerWorks, February 2006) Ajax 마스터하기
- Part 4: 웹 응답에 DOM 활용하기
- 자바 개발자를 위한 Ajax: 동적 자바 애플리케이션 구현
- 자바 개발자를 위한 Ajax: Ajax용 자바 객체 직렬화
- Call SOAP Web services with Ajax, Part 1: Build the Web services client
- Ajax: A New Approach to Web Applications
- The DOM Home Page
- The DOM Level 3 Core Specification
- The ECMAScript language bindings for DOM
- developerWorks Web architecture zone
- developerWorks technical events and Webcasts
제품 및 기술 얻기
-Head Rush Ajax
-Java and XML
-JavaScript: The Definitive Guide
-Head First HTML with CSS & XHTML
-IBM trial software
토론
-developerWorks blogs.
Brett McLaughlin, Author and Editor | O'Reilly Media Inc.
원문 :http://www.dbguide.net/know/know102001.jsp?mode=view&divcateno=14&divcateno_=14&pg=1&idx=3057





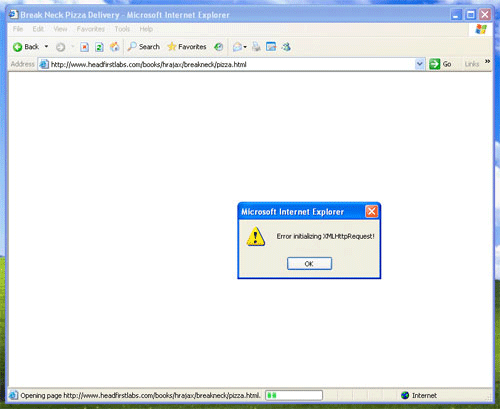
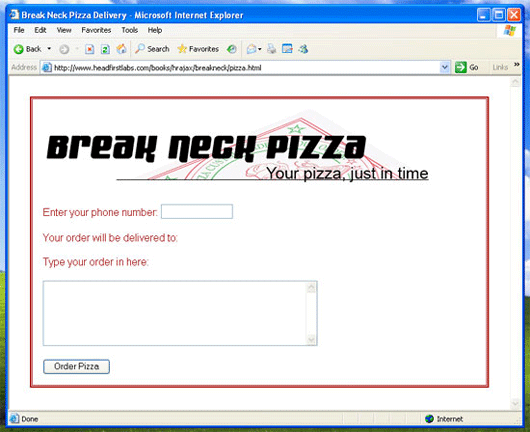
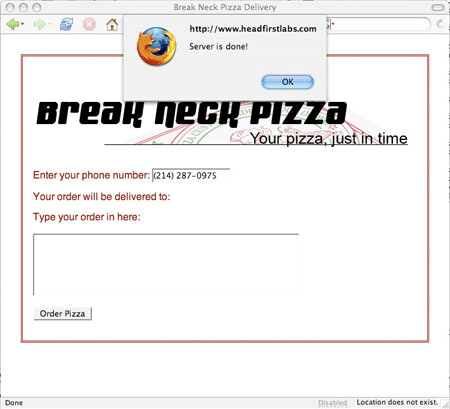
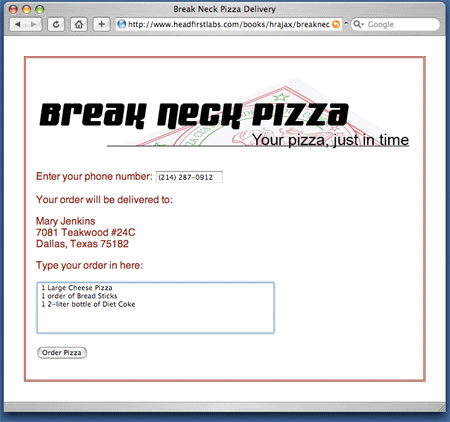
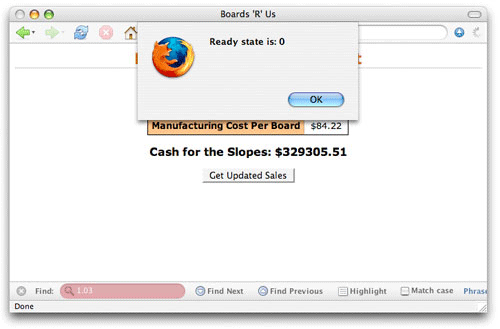
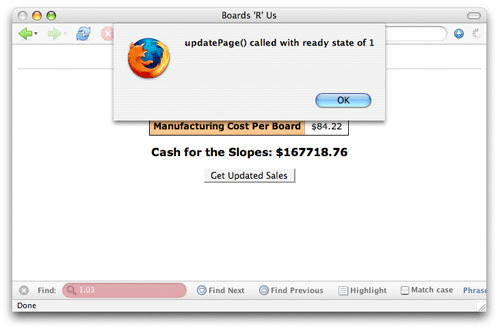
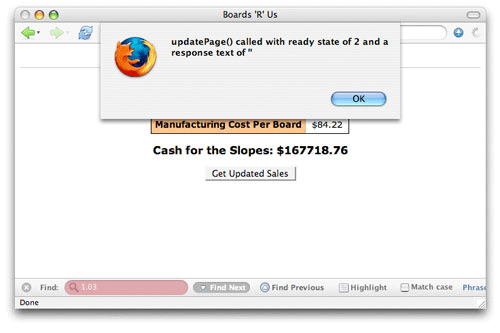
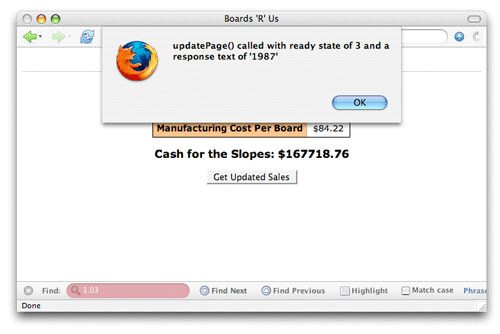
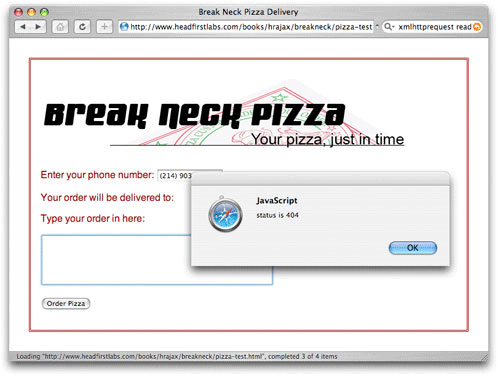
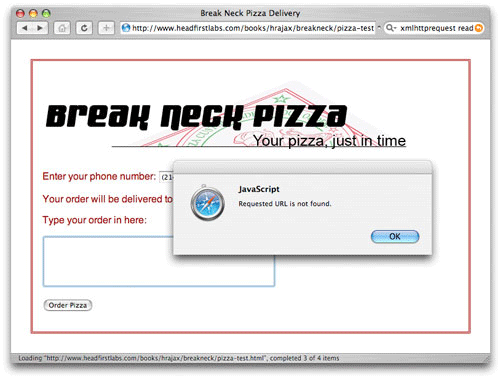
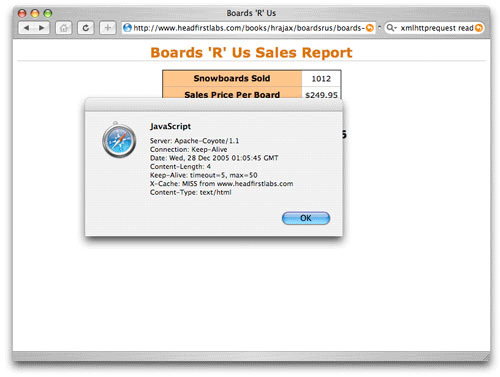
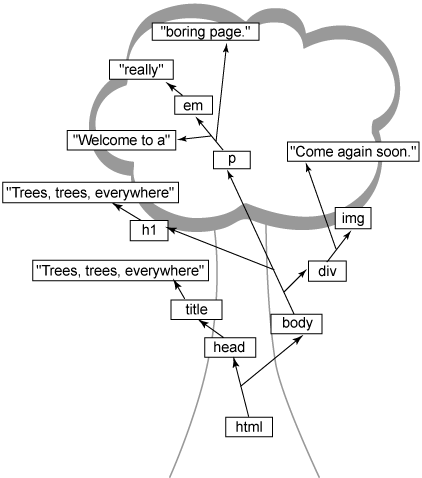
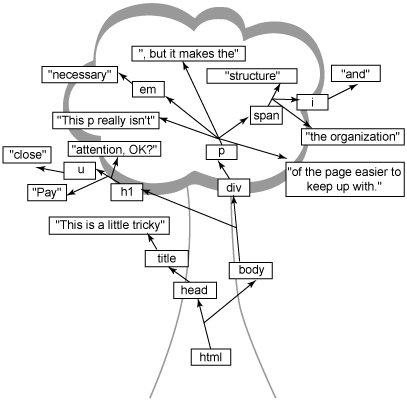
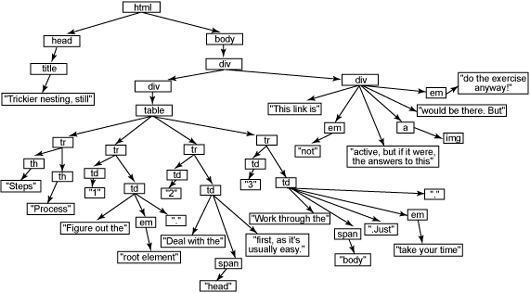


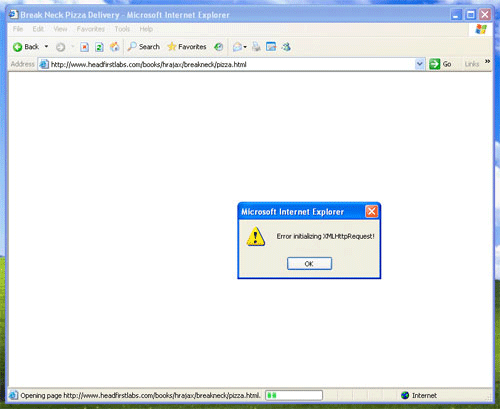
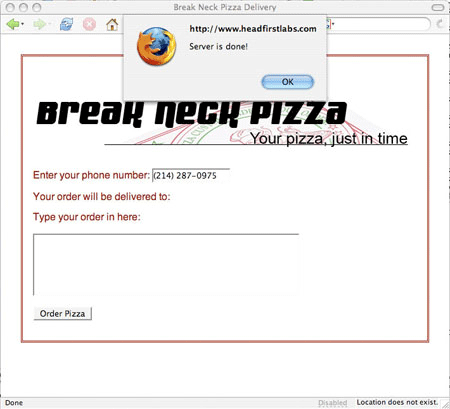
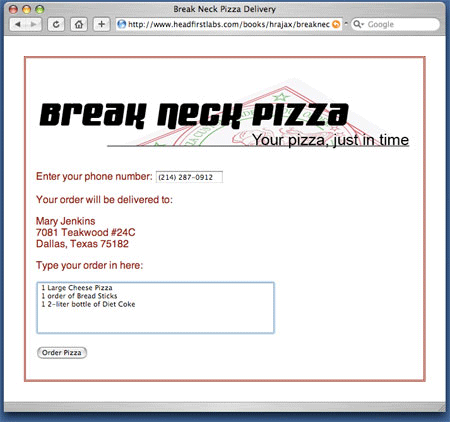
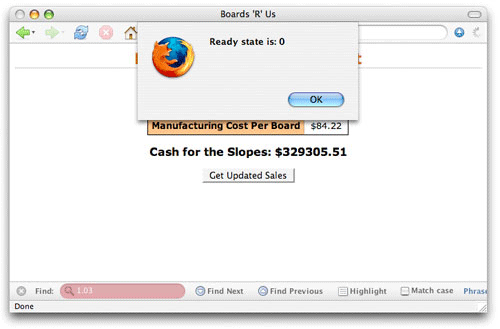
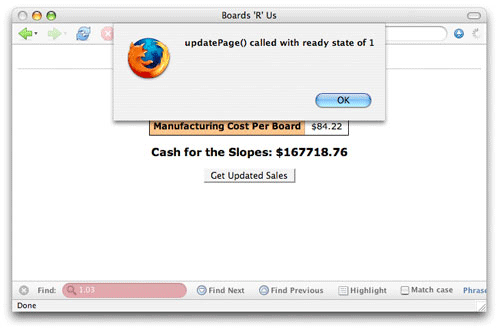
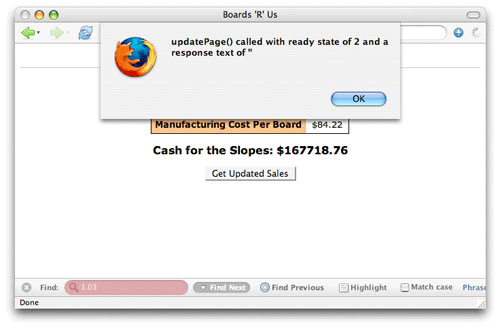
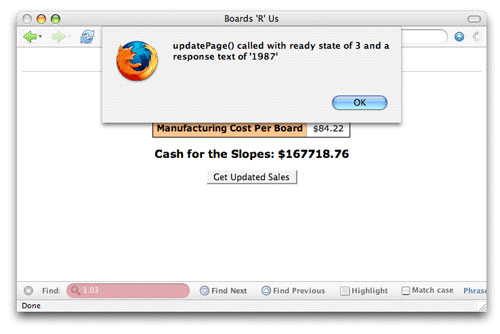
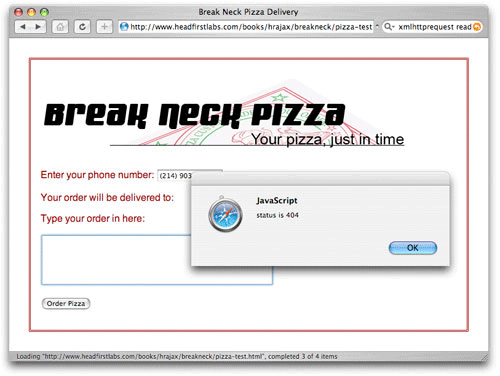
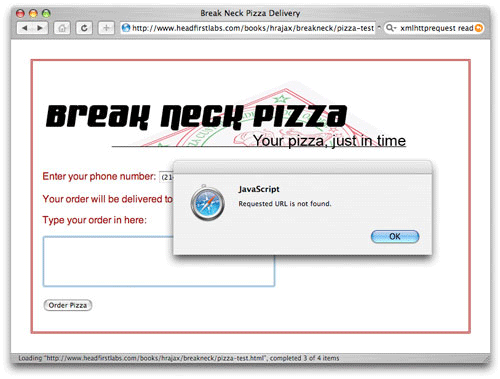
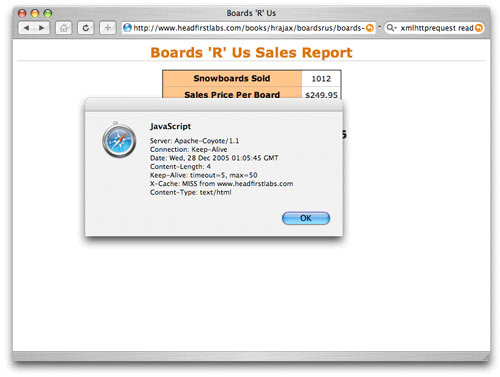


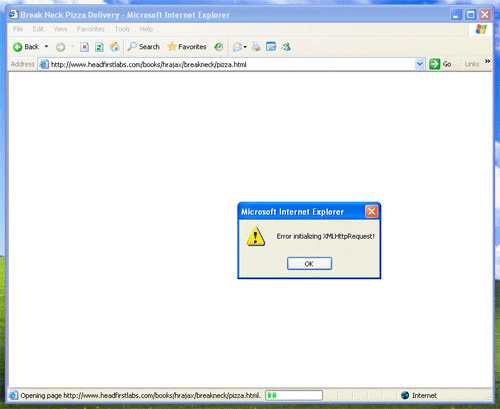
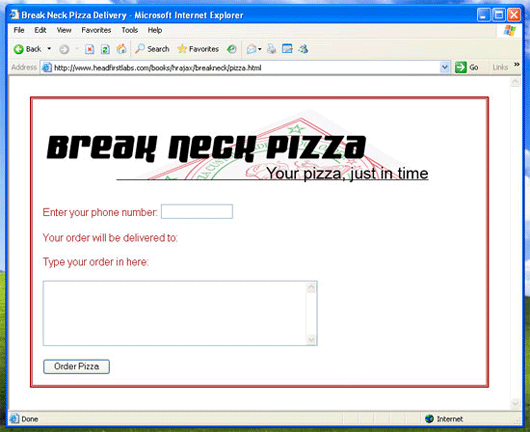
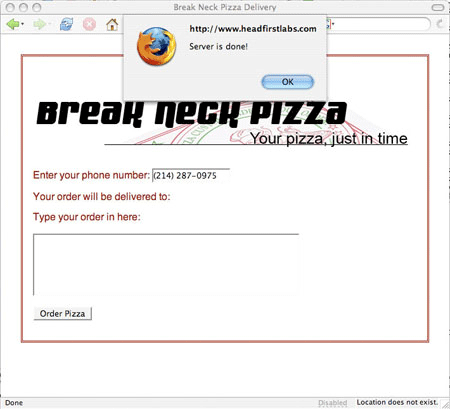
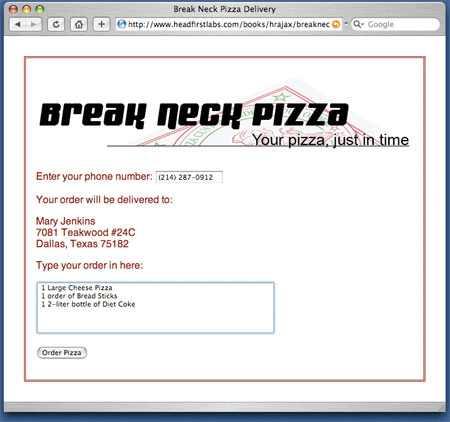






 invalid-file
invalid-file