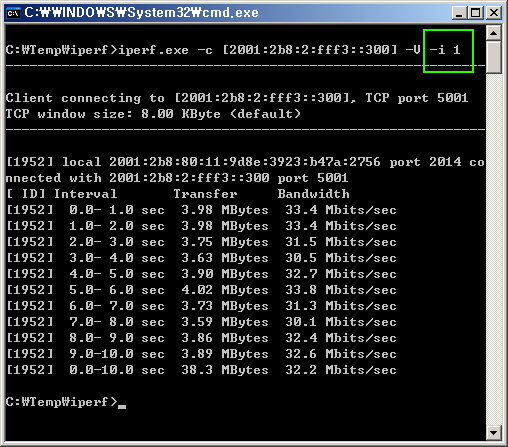
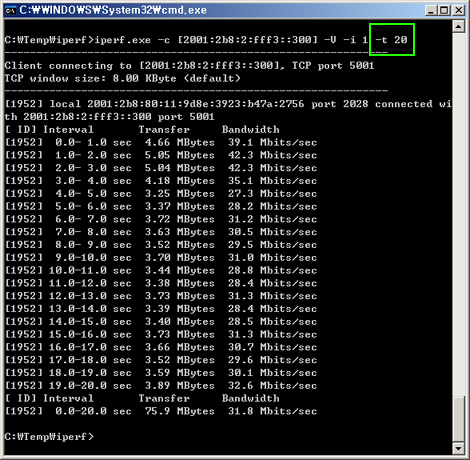
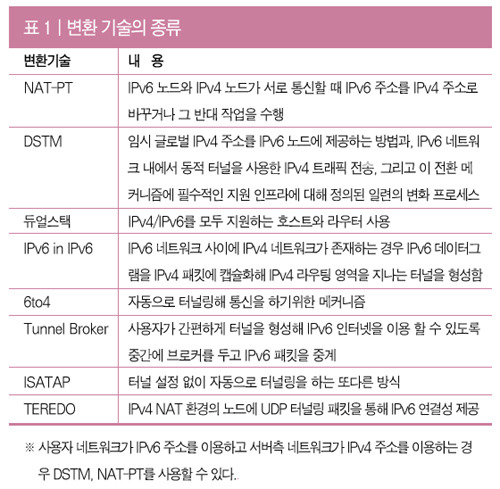
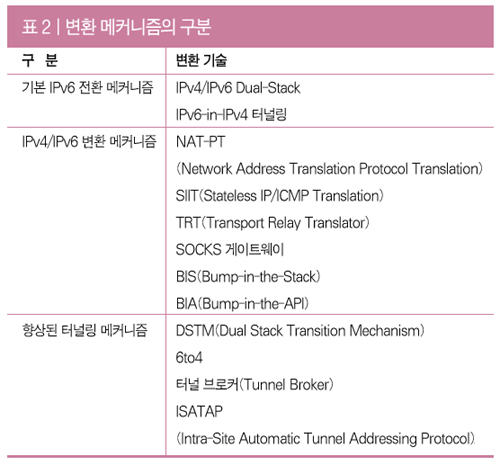
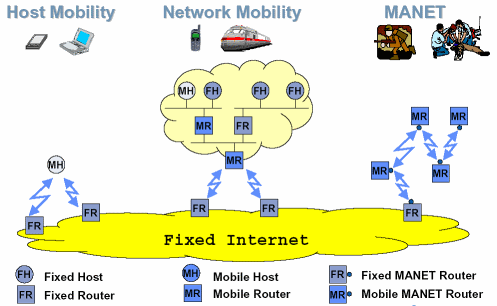
[UML 제대로 알기] ③ 개발 프로세스에 따른 UML 실전 모델링
개발 프로세스에 따른 UML 실전 모델링
연재순서
1회.가능성·확장성 품고 등장한 UML 2.0
2회.초보자를 위해 다각도로 살펴본 UML
3회.바로 알고 제대로 쓰는 UML 실전 모델링
4회.닷넷 환경에서 UML 툴 활용 가이드
5회.표준을 넘나드는 UML의 적절한 사용
UML과 개발 프로세스라는 것이 만나게 되면 각 프로세스 별로 UML을 활용하여 모델링을 하는 방법이 약간씩 달라지기 때문에 사용상 주의가 필요하게 된다. 이와 더불어 웹 애플리케이션 개발을 위한 UML 모델링은 어떻게 하면 좋은지에 대해서도 생각해볼 필요가 있다.
이번 글에서는 지금까지 UML을 이용하여 소프트웨어 개발을 수행하면서 느꼈던 개념상의 모호함과 모델링 시 주의할 점에 대해 살펴보고자 한다.
약 7년 전 필자는 UML에 관하여 세미나를 하려고 어느 업체를 방문한 적이 있었다. 세미나를 막 시작하려고 하는 순간 어느 분께서 'UML이 이번에 새로 나온 XML의 한 종류인가 보죠?'라고 질문을 했다. 과연 이 난관을 어떻게 헤쳐 나가야 할지 막막한 순간이 UML에 관한 이야기를 하려고 하면 지금도 떠오른다.
UML이 우리나라에 처음 소개되던 시기에는 많은 분들이 객체지향이나 모델링 언어에 대한 개념이 일반적이지 않았다. 하지만 약 7년이 지난 지금은 소프트웨어 개발을 하는 대부분의 종사자들은 UML이라는 것이 무엇이고 어디에 쓰는 것인지 알고 있다. 또한 소프트웨어를 개발하기 위해서는 적어도 UML 다이어그램 몇 개 정도는 그려줘야 할 것 같은 생각을 갖고 있다. 많은 인식의 변화가 있었지만 지금 이 순간에도 여전히 UML이라는 것을 제대로 활용하여 소프트웨어를 개발하고 있는지 제대로 알고 있는지는 의문을 갖지 않을 수 없다.
UML과 모델 그리고 산출물
UML과 모델, 산출물은 비슷한 것 같지만 실은 아주 다른 개념이다. 우리가 소프트웨어라는 것을 개발하기 위해 '무엇을 만들 것인가?'라는 질문에 답하기 위해서는 대상이 되는 문제영역을 정확히 알 필요가 있다. 소프트웨어 개발팀 혹은 개발자는 문제영역에 대하여 정확하게 이해하기 위한 가장 좋은 방법은 모델을 통하는 것이다. 모델은 문제영역의 현실을 단순화시킴으로써 우리가 만들고자 하는 시스템을 더 잘 이해할 수 있게 한다.
『The UML User Guide』에 의하면 모델링을 통해 우리는 다음과 같은 4가지 목적을 얻을 수 있다고 한다.
◆ 모델은 시스템을 현재 또는 원하는 모습으로 가시화하도록 도와준다.
◆ 모델은 시스템의 구조와 행동을 명세화할 수 있게 한다.
◆ 모델은 시스템을 구축하는 틀을 제공한다.
◆ 모델은 우리가 결정한 것을 문서화 한다.
즉, 복합한 시스템에 대해 모델을 만드는 이유는 그러한 시스템을 전체적으로 이해할 수 없기 때문이다. UML은 앞에서 언급한 4가지 목적에 충실히 부합하기 때문에 소프트웨어를 개발함에 있어 모델링 언어로 UML을 이용한다.
UML 다이어그램이 산출물인가?
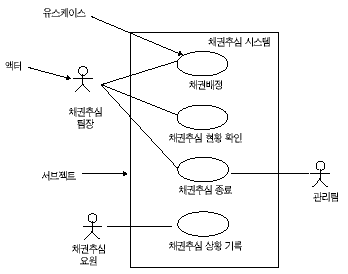
필자는 어느 프로젝트의 개발 프로세스 멘터링를 하기 위해 한 업체를 방문한 적이 있었다. 그 곳에서 도착하여 간단한 미팅을 한 후 가장 먼저 요구했던 정보는 고객과 합의한 활동과 산출물의 목록이었다. 그 문서에는 역시 예상대로 요구사항 산출물에 '유스케이스 다이어그램'이라는 것이 있었고 분석 산출물에 '클래스 다이어그램'이라는 것이 들어 있었다. 이외 여러 부분에 'XXX 다이어그램'이 눈에 띄었다.
UML 다이어그램이 산출물이 될 수 있는가? 결론적으로 말하자면 UML 다이어그램은 산출물이 아니다. 나중에 자세히 설명하겠지만 산출물의 한 종류가 모델이고 모델을 표현하기 위한 수단 중에 하나가 UML 다이어그램이다.
예를 들어 UML의 클래스 다이어그램을 생각해 보자. 다양한 종류의 산출물은 그 산출물이 표현하고자 하는 정보를 보여주기 위해 UML 다이어그램을 이용한다. 유스케이스 실현(Realization)의 VOPC(View of Participating Classes)에서도 사용하고 비즈니스 조직을 표현하고자 할 때도 클래스 다이어그램을 사용할 수 있다. 또한 아키텍처 메커니즘을 표현하고자 할 때도 클래스 다이어그램을 이용한다. 유스케이스 다이어그램의 경우도 비즈니스 유스케이스 모델을 표현할 때도 쓰이고 시스템 유스케이스 모델을 표현할 때도 쓰인다. 다양한 산출물에 UML 다이어그램을 쓴다.
요구사항에서 혹은 분석/설계에서 산출물로 클래스 다이어그램이라고 명시해 놓으면 과연 어떤 클래스 다이어그램인지 알 수 있을까? 또한 시퀀스 다이어그램이 산출물 목록에 버젓이 들어있다면 그 다이어그램은 과연 어떤 정보를 표현하려고 하는 다이어그램인지 알 수 없다. 다이어그램은 산출물의 의도를 표현하기 위해 사용하는 하나의 표현도구이다. 산출물은 절대로 아니다.
우리의 목적은 산출물이다
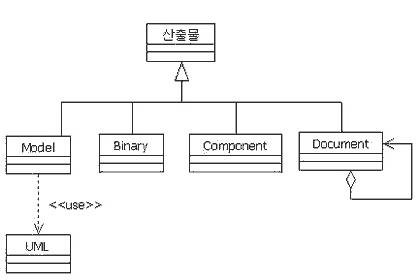
앞에서 UML은 산출물이 아니며 모델은 산출물의 한 종류라는 것의 이야기했다. 그렇다면 산출물을 무엇을 의미하는가? 일반적으로 산출물이라는 것은 종이 형태의 문서로 알고 있다. 하지만 산출물은 프로세스를 통해 프로젝트 기간 동안 만들어지는 의미를 갖는 모든 것을 일컫는다. 그 중 하나가 모델이며 실행 가능한 바이너리 형태의 컴포넌트, 문서, 소스코드, 스크립트 등이 해당한다. 산출물(Artifact)의 정의를 보면 다음과 같다.
산출물은 어떤 정보의 일부로서 1) 프로세스를 통해 만들어지고 변경되고, 사용되며 2) 책임영역을 정의하며 3) 버전컨트롤의 대상이 된다. 산출물은 모델, 모델요소, 또는 문서 등이 될 수 있으며 문서는 다른 문서의 일부분으로 포함 될 수 있다(A piece of information that: 1) is produced, modified, or used by a process, 2) defines an area of responsibility, and 3) is subject to version control. An artifact can be a model, a model element, or a document. A document can enclose other documents).
◆모델(model) :유스케이스 모델, 분석 모델, 설계 모델과 같이 다른 산출물을 포함하는 형태를 갖는 산출물
◆모델 요소(model element) :다른 산출물 내부에 포함되어 있는 산출물로 예를 들면 유스케이스 모델 안의 유스케이스, 액터와 설계 모델 내부의 설계 클래스, 설계 서브시스템 등과 같은 산출물
◆문서(document) :문서로 존재하는 산출물로 비즈니스 케이스, 소프트웨어 아키텍처 문서 등과 같은 산출물
◆ 소스코드나 실행 가능한 것(컴포넌트) 등
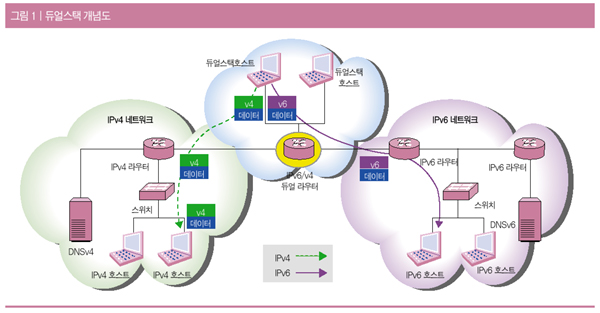
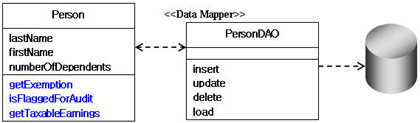
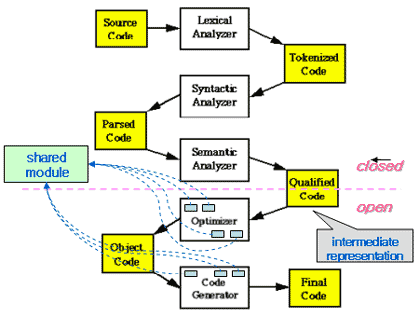
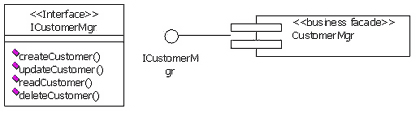
<그림 1>은 산출물과 모델 그리고 UML과의 관계를 클래스 다이어그램으로 표현한 것이다.
모델링은 개발기간을 늘이는 원흉?
필자는 지금까지 여러 프로젝트에서 직접 개발에 참여하기도 했고 컨설팅 또는 멘터링 형태로 참여하면서 사람들로부터 많은 질문을 받아왔지만 그 중에 가장 많이 하는 질문은 “우리 프로젝트에 UML이 꼭 필요하겠습니까? 프로젝트 규모가 좀 작으면 UML을 적용하지 않아도 괜찮지 않을까요?”라는 것과 “UML을 적용하면 개발이 좀 늦어지지 않겠습니까?”라는 두 가지 질문이 대표적이다.
우선 첫 번째 질문의 의미를 생각해 보자. 프로젝트 규모가 작으면 UML을 굳이 적용하지 않고 두어 명 개발자들이 그냥 뚝딱뚝딱 시스템을 만들면 되지 않을까 하는 것이다. 필자도 비슷한 생각으로 모델링을 하지 않고 프로젝트를 진행해 본적이 있었다. 개발자 3명이 기능 수 약 100개 정도의 시스템을 개발한 적이 있었는데, 작고 간단한 시스템이었으므로 순진한 생각에 그냥 테이블 정도만 정리해 놓고 코딩부터 시작하면 쉽고 금방 될 줄 알았다.
하지만 상황은 그렇게 호락호락하지 않았다. 용어와 기능부터 명확히 정의되지 않았고, 시작부터 개발자간의 서로 다른 이해수준은 프로젝트를 암울하게 만들었다. 어렴풋한 이해를 바탕으로 만들어지는 코드는 만들고 나서 뜯어고치는 코드가 더 많아 졌고 비즈니스 컴포넌트간의 인터페이스로 수시로 어긋났다. 결국 간단하게나마 모델을 만들면서 진행하기로 했고 모델링 시간 약간 줄이려고 하다가 우왕좌왕한 만큼 시간을 허비한 결과로 나타났다. 꼭 UML이 아니더라도 어떤 형태로든지 모델링은 해놓았어야 했고 그것이 업계 표준인 UML로 했더라면 더 좋지 않았을까 하는 후회가 든다.
혼자 만들더라도 역시 UML로 모델링을 하는 것이 개발하는 중에도 좋고 개발하고 난 뒤를 생각해봐도 반드시 필요하다는 생각이다. 개발을 마치고 난 뒤에 누군가 그 시스템을 유지보수 해야 한다면 전 개발자가 UML을 이용하여 만들어 놓은 모델을 보고 아마 감사하게 생각 할 것이다. 또 개발하고 있는 순간에도 몇 명밖에 없지만 그 사람들끼리 의견 교환이나 문제 영역에 대한 공통적인 이해를 돕기 위해서도 필요하다. 혼자 개발하더라도 생각이 정리가 잘 안되면 UML로 아이디어를 정리하는 판에 다른 사람과 생각을 맞추는데 필요가 없겠는가?
“UML을 적용하면 개발 기간이 늦어진다”. 어떻게 보면 약간 황당할 정도의 이야기임에 틀림없다. UML 때문에 개발기간이 늘어나는 것이 아니라 익숙지 않은 UML을 모델링 언어로 선택함으로써 배우는 기간이 더 늘어나는 것이 정확한 의미가 아닐까 싶다. 심지어 어떤 프로젝트 매니저는 개발은 그냥 개발대로 나가고 산출물은 산출물대로 만들어 나가서 나중에 소스코드가 나오게 되면 역공학(Reverse Engineering)을 통해 UML 모델을 만들어내자는 제안을 하기도 했다. 모델과 코드간의 동기화를 위해 역공학을 이용하지만 과연 이것이 시간을 줄이는 방법일까?
개발 프로세스와 과도한 모델링
무엇을 모델링 할 것인가? 어느 정도의 정밀도 수준으로 모델링 할 것인가? 모델링의 범위는 어떻게 설정해야 하는가? 이러한 질문에 답하기 위해 이것저것 고민해보기도 하고 업계에 종사하는 분들과 메신저로 혹은 술자리에서 때로는 프로젝트 회의 시간에 토의를 많이 해 보았다. 그 중 필자가 알고 지내는 대부분의 개발자들의 한결같은 주장은 '과도한 모델링'의 압박에 시달린다는 것이었다. 이야기를 해 본 결과 실제로 개발자들이 느끼는 '과도한 모델링'의 기준은 주관적이었지만 몇몇 주장은 일견 수긍이 가기도 했다.
그 중에 하나가 프로세스의 적용 문제였는데 지구상에 존재하는 모든 프로젝트는 서로 다른 시스템을 만들고 있기 때문에 모든 프로젝트 천편일률적으로 적용되는 모델링 범위나 정밀도 수준은 없다. 하지만 그것을 프로젝트의 규모나 도메인의 종류 등의 일반화된 기준으로 묶고 그 기준에 해당하는 개발 프로세스를 제공해야 한다. 예를 들어 현재 우리나라에서는 RUP(Rational Unified Process)나 마르미와 같은 프로세스 프레임워크를 많이 사용한다. 또 SI 업체에서는 자체적으로 발전시켜온 방법론이나 앞에서 언급한 RUP 또는 마르미를 기반으로 하여 자체 프로세스를 개발하여 사용한다.
문제는 각 프로젝트마다 프로세스를 조정(Tailoring)해서 적용해야 하는데 현실은 그렇지 않다는 것이다. 심지어 이런 이야기를 들은 적도 있다. "CBD를 적용하기엔 우리 프로젝트 규모에 좀 안 어울리지 않나요? 아는 사람한테 물어봤더니 규모가 작으면 CBD가 안 어울린다고 하더라고요. 대신 굳이 CBD를 하려면 UML 모델링 툴을 반드시 도입해서 진행해야 한다고 하던데…" 누가 이 분에게 그런 이야기를 했는지 모르지만 이 정도 되면 거의 사기에 가깝다. 그 분이 생각한 CBD라는 것이 무엇이었는지 어림짐작되는 대목인데 마치 신발에 발을 맞추는 꼴이 되어 버렸다.
발을 보호하는 것이 1차적인 목표이고 멋도 부리는 것이 신발을 신는 2차 목표라고 보면, 우선 성공적인 프로젝트를 수행하기 위해 프로세스를 도입하고 이왕 개발할 것 좀 체계적으로 가이드를 받아보자는 목적도 있을 것이다. 객체지향이나 CBD와 같은 단어의 의미는 일단 논외로 하고 앞에서 언급한 프로세스 조정에 관하여 이야기 해보자.
프로세스 조정
앞에서 언급했듯이 RUP나 마르미는 일반적이고 범용적인 개발 프로세스이다. 세 달간 3명이 개발하는 프로젝트와 2년간 50명이 개발하는 프로젝트 모두 개발 프로세스가 같을 수 있겠는가? MS 워드와 같은 워드프로세서를 개발하는 것과 은행을 위한 전산 시스템을 개발하는 개발 프로세스가 같을 수 있겠는가?
서로 다른 특성을 갖는 프로젝트를 위해 프로세스 조정(Tailoring)이란 작업을 하게 되는데 여기서 유의해야 할 것은 조정할 수 있는 영역을 제한해야 한다는 것이다. 프로젝트 현장에서 편의대로 프로세스를 고치거나 누락시켜서는 안되고 프로세스 조정의 결과는 승인되어야 한다. 더 나아가 프로젝트 세부 유형에 따른 개발 프로세스를 제공한다면 더할 나위 없이 좋을 것이다. 프로세스의 대표적인 구성 요소로는 작업 영역, 작업 흐름, 활동, 산출물, 역할 등이 있다. 필자는 이 모든 것이 프로세스 조정 대상이 될 수 있다고 생각한다.
RUP의 경우 '프로세스 엔지니어'가 프로세스 조정 작업을 진행하고 마르미 경우 ‘도구 및 방법론 관리자’가 그 역할을 수행한다(XP의 경우는 코치라고 한다. 편의상 이 글에서는 모두를 프로세스 엔지니어라고 칭하겠다). 이런 역할의 특성상 다른 사람과의 의견 교환이나 대립이 있기 때문에 프로세스 엔지니어는 소프트웨어 개발에 관한 폭넓은 지식을 갖고 있어야 하며 의사소통 능력이 있어야 한다. 프로젝트 관리자나 프로젝트 리더 또는 시스템 분석가나 아키텍트를 설득해야 할 일이 있을 수도 있다.
프로젝트 관리자나 프로젝트 리더는 프로젝트 관리 관점으로 개발 프로세스를 바라볼 것이고 시스템 분석가나 아키텍트는 소프트웨어 시스템을 개발하는데 중요한 결정을 내리기 위한 관점으로 프로세스를 바라보며 자신의 의견을 제시 할 것이다. 이들의 의견을 통합하고 조정하며 고객의 요구를 반영하여 해당 프로젝트의 상황에 맞는 프로세스로 조정하게 된다.
|
|
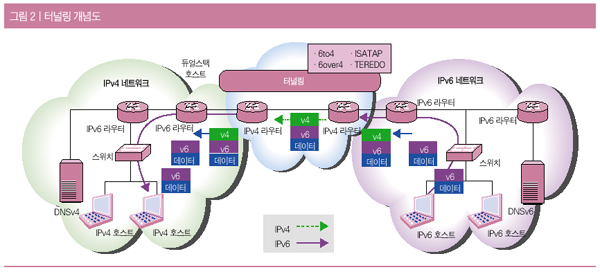
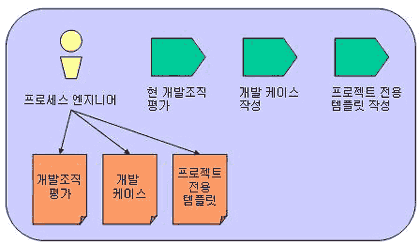
| <그림 2> 프로세스 엔지니어의 활동과 산출물 |
<그림 2>에서 프로세스 엔지니어는 현 개발 조직 평가, 개발 케이스(Development Case) 작성, 프로젝트 전용 템플릿 작성의 세 가지 활동을 하게 된다. 이에 따른 개발 조직 평가, 개발 케이스 프로젝트 전용 템플릿의 세 가지 산출물을 작성하는데 여기서 가장 핵심적인 산출물은 개발 케이스이다. 특정 프로젝트를 위한 프로세스를 조정하고 개발 케이스를 작성하기 위해서는 프로젝트의 상황을 이해 할 필요가 있는데 이를 위하여 현 개발 조직에 대한 평가가 이루어져야 한다. 또한 개발 조직 이외에도 고객에 대한 평가도 동시에 이루어져야 한다.
예를 들어, 기업을 위한 애플리케이션을 개발한다고 가정한다면 개발 완료 후에 고객은 유지보수를 위한 산출물을 요구할 것이다. 프로세스 엔지니어는 개발 조직 및 고객을 대상으로(좀 더 의미를 확장하자면 이해관계자를 의미 할 수 있다) 현 개발 조직에 대한 평가를 할 때 프로세스, 툴, 사람들의 능력, 사람들의 태도, 고객들, 사용 기술, 문제점, 개선 분야의 관점에서 개발 조직의 현재 상태를 평가한다.
프로세스 조정을 위한 요구사항을 파악하고 이를 근거로 프로세스 조정을 실시한다. 프로세스 조정의 결과는 개발 케이스이다. 프로세스 조정에 관한 자세한 사항을 알고 싶으면 RUP나 마르미 또는 Barry Boehm과 Richard Turner가 쓴 『Rebalancing Your Organization's Agility and Discipline』를 참조하면 도움이 될 것이다.
케이스 툴을 쓰면 생산성이 높아지는가?
Steve McConnell은 그의 저서인 『Professional Software Development(2003)』에서 코끼리에 관한 재미있는 이야기를 소개했다. 이야기를 요약하면 이렇다.
고대 이집트 어느 왕의 피라미드를 만드는 공사가 한 참 진행 중이었다. 엄청나게 큰 암석을 사람들이 일일이 날라야 했으므로 공사의 진척은 매우 더디었다. 그래서 공사 프로젝트 관리자는 고민 끝에 어디선가 코끼리라는 엄청난 동물이 있는데 이 동물은 사람이 운반하는 것 보다는 몇 배 혹은 몇십 배 높은 생산성은 낸다는 이야기가 얼핏 기억이 기억났다. 이 동물만 들여오면 지금까지 지연되었던 일정을 단번에 만회할 수 있을 것 같은 생각이 들었다.
공사 프로젝트 관리자는 그 동물을 도입하기로 결심하고 일을 추진했다. 코끼리라는 동물을 들여놓고 보니 과연 듣던 대로 몸집도 엄청나고 그에 걸맞게 힘도 대단했다. 공사 프로젝트 담당자는 입가에 미소를 머금으며 공사현장에 코끼리를 투입하라는 지시를 내렸다. 그러나 그 동물을 투입하는 순간 순조롭게 진행될 것 같은 공사가 점점 이상하게 진행되고 일정도 생각했던 것만큼 줄여지지 않았다. 줄여지기는커녕 오히려 사람이 진행했던 것보다 더 늦어지는 조짐이 보였다.
공사 프로젝트 관리자는 상황파악에 나섰는데 공사 현장에 가서 자세히 관찰을 해보니 문제를 바로 파악할 수 있었다. 바로 코끼리를 다룰 수 있는 사람이 없었던 것이었다. 그의 공사팀은 그런 동물을 부리면서 일을 한 적이 단 한번도 없었기 때문에 기존의 공사프로세스와 엄청난 혼선을 빗었다. 또 코끼리에 대해 아는 것이 전혀 없었기 때문에 코끼리를 돌보지 못해 걸핏하면 앓아눕기 일 수였고 몇몇 코끼리는 도망가 버려 엄청난 비용을 들여 도입한 코끼리가 무용지물이 되어 버렸다. 공사 진행은 그 만큼 지연되었고 코끼리를 포기할 수밖에 없었다"
필자가 보기엔 그 코끼리가 바로 케이스 툴이 아닌가 싶다. 프로젝트 생산성을 높이기 위해 케이스 툴을 도입하는 것은 바람직하지만 그 생산성을 높이기 위해서는 일정 기간의 훈련이 필요하다. 요즘 나오는 케이스 툴은 기능도 막강하고 더불어 복잡하다. 또 종류도 많아 수많은 케이스 툴과 연동도 필요하다. 일례로 IBM 래쇼날의 스위트 제품은 내장하고 있는 서브 제품만 해도 10여 가지가 넘는다. 다른 케이스 도구도 사정은 다를 바 없다.
프로젝트 현장의 요구는 이러한 제품을 좀 편하게 사용하고 싶어 한다. 소프트웨어 개발 라이프 사이클 전반에 걸쳐 케이스 툴을 적용하려고 서로 다른 회사 목적이 다른 툴을 서로 연계시켜야 한다. 이 일은 대단히 복잡하고 가변적이어서 앞의 요구를 충족시키려면 프로세스적으로나 케이스 툴에 대한 상당한 지식과 수준의 기술이 요구된다.
요구사항관리 도구와 분석/설계를 위한 모델링 도구와의 연계 부분, 모델링 도구와 개발 및 테스팅 도구와의 연계 부분이 대표적인 연계 부분이다. 또한 각 케이스 툴에서 쏟아져 나오는 다양한 모델과 문서들을 통합적으로 관리할 수 있는 형상 및 변경 관리와 각 작업영역(요구사항, 분석/설계, 구현, 테스트 등)을 기반으로 하여 반복 개념으로 프로젝트를 관리해야 하므로 실제 케이스 툴이 소프트웨어 개발을 도와주려면 아주 많은 것들을 고민해야 한다.
특히 프로젝트 현장에서 따르고 있는 프로세스를 정확히 지원해줘야 하므로 케이스 툴 자체의 유연성도 갖춰야 한다. 케이스 툴은 단어의 의미에서와 같이 소프트웨어 개발을 정말로 도와주는 케이스 툴이 되어야 하지 않을까 싶다.
머릿속 아이디어를 모델로 구체화하기
필자는 항상 프로젝트를 진행하다 보면 항상 딜레마에 빠지는 문제가 있다. 프로젝트에 참여하는 사람들이 UML을 잘 모르는 경우이다. UML을 모델링 언어로 채택한 프로젝트는 그 프로젝트에 참여하는 모든 사람들이 UML을 알고 있어야 한다는 전제조건이 따른다.
하지만 현실은 어떠한가? 프로젝트를 수주해야만 먹고 사는 개발 업체의 경우 UML을 알던 모르던 일단 수주를 해야만 하는 상황이다. 그 회사의 개발팀 구성원이 UML을 잘 알고 있다면 문제가 없겠지만 잘 모르는 경우 심하면 그 구성원 중 단 한 명도 제대로 알지 못하는 경우 문제가 아닐 수 없다.
이 때 가장 많이 활용하는 방법은 UML을 알고 있는 사람이나 업체를 고용하여 먼저 샘플을 만들게 한 후 그것을 템플릿으로 하여 모델링을 진행하는 것이다. 물론 이런 프로젝트가 많아야 필자 같은 사람들이 먹고 살긴 하겠지만 프로젝트 입장에서는 참 못마땅한 일이 아닐 수 없다.
예를 들어 UML을 알고 있는 사람이 시스템의 한 부분에 대하여 클래스 다이어그램을 그렸다고 하자. 그 클래스 다이어그램이 샘플로 나오면 다른 모든 사람들은 그 샘플을 기반으로 모델링을 시작하게 된다. 맞는지 틀리는지 자신의 판단 기준이 없는 채로 샘플을 '다른 이름으로 저장하기'로 해서 따로 하나는 만들어 놓은 다음 다이어그램을 그리고 저장을 한다. 예전에 학교에서 다른 친구 소스코드 구해다가 변수명 좀 바꾸고 약간 짜깁기해서 리포트를 제출하는 것과 비슷한 상황이 된다.
다이어그램이야 만들어 졌지만 모델링을 하는 사람이 그 모델이 적합한지 아닌지 판단할 수 없으므로 그려진 다이어그램을 들고 샘플을 만든 사람에게 달려와 이것저것 물어본다. 물론 어쩔 수 없는 상황이고 그런 과정을 거치면서 사람들의 모델링 실력이 향상되겠지만 모르면서 그림을 그리는 사람도 답답하고 프로젝트 진행에도 문제가 많다.
잘 모르는 사람이 프로젝트를 하는, 어떻게 보면 시작부터 이상하긴 하지만 어쩔 수 없다고 보고 조금이나 도움이 되도록 머릿속의 아이디어를 모델로 구체화 하는 과정을 소개하면 조금 낫지 않을까 싶다.
시작은 글쓰기부터
만들고자하는 모델이나 그리고자 하는 다이어그램에 따라 접근 방식이 다르겠지만 결국 시작은 머릿속의 생각을 글로 정리하는 것부터 시작한다. 글로 쓰기 귀찮다면 메모장이나 화이트보드에 본인의 생각을 간단하게나마 자유로운 형식으로 정리하면서 시작하게 된다.
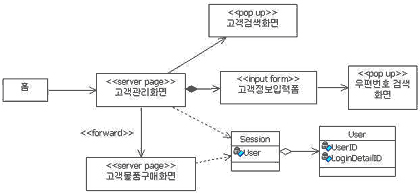
예를 들어, 고과장이 애플리케이션 프레임워크를 모델링 한다고 가정해 보자. 프레임워크를 모델링하는 사람이 UML을 설마 모르진 않겠지만 이 사람이 어떤 과정을 거치면서 머릿속 아이디어에서부터 구체적인 모델을 만들어 가는지 살펴보자. 고과장은 프레임워크의 한 부분을 모델링하기 위해 고심하다가 머릿속에서만 맴도는 아이디어를 글로 써보기로 했다.
클라이언트에서 어떠한 메시지를 보내면 프레임워크에서는 그 메시지를 해석하여 어떤 비즈니스 로직을 수행할 지 결정하여 수행한다. 메시지에 따라 수행하는 비즈니스 로직은 메시지가 변해도 동일한 비즈니스 로직이 수행되어야 하거나 동일한 메시지에도 상황에 따라 비즈니스로 로직이 바뀔 수 있어야 한다.
써 놓고 읽어보니 대충 어떤 방향으로 만들어야 할지 느낌이 좀 오기 시작했다. 왠지 잘 될 것 같은 느낌으로 입가엔 미소를 머금으며 모델링 도구를 실행시켰다.
모델링을 시작하다
우선 고과장은 클라이언트와 클라이언트가 보내는 메시지를 받는 무엇인가가 있어야 하지 않을까 하는 생각이 들었다. 또 어떤 비즈니스 로직을 수행할지 판단하는 객체도 있어야 할 것 같고, 클라이언트가 보낸 메시지에 대응하는 비즈니스 로직을 갖고 있는 정보를 갖고 있는 객체도 있어야 할 것 같다.
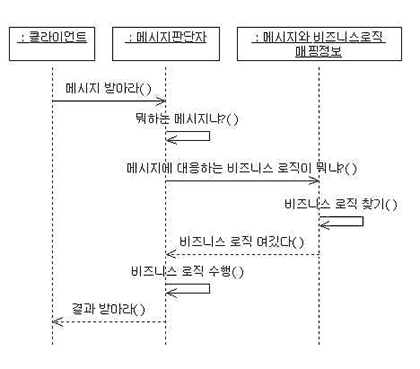
고과장은 우선 '클라이언트', '메시지 판단자', '메시지와 비즈니스 로직 맵핑 정보' 등이 객체가 되지 않을까 생각했다. 모델링 툴을 띄워놓고 세 가지 객체를 그리고 나니 이들 간의 관계와 각 객체가 어떤 일을 해야 하는지(Responsibility)가 알쏭달쏭 했다. 그래서 이 세 가지 객체를 놓고 이들 객체가 서로 어떻게 인터랙션(Interaction)하는지 알아보기 위해 시퀀스 다이어그램을 그려보기로 했다.
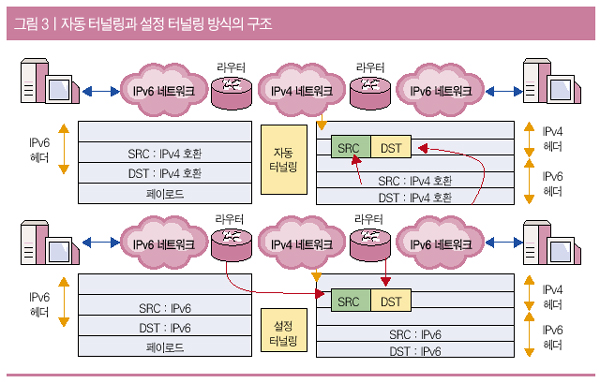
|
|
| <그림 3> 개념 정리를 위한 시퀀스 다이어그램 |
이렇게 그려놓고 보니 객체 간에 어떻게 교류하는지 눈에 들어와 더 구체적으로 생각할 수 있게 되었다. 고과장은 시퀀스 다이어그램을 보면서 차근차근 짚어보기로 했다. 클라이언트가 메시지를 '메시지 판단자'에게 보내면 해당 메시지에 대응하는 비즈니스 로직을 알려주고 메시지 판단자가 비즈니스 로직을 수행하여 클라이언트에게 보내주는 깔끔한 형태로 정리된 것 같았다.
뭔가 빠진 것 같은데?
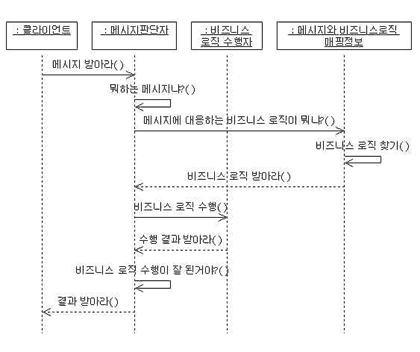
하지만 객체 간에 어떻게 교류하는지 눈에는 보였지만 왠지 무엇인가 빠진 듯한 느낌이 들었다. 시퀀스 다이어그램을 쳐다보고 있으니 메시지 판단자가 '비즈니스 로직 수행'을 하는 것이 메시지 판단자의 역할에 비해 좀 오버하는 듯한 느낌이 들었다. 또 비즈니스 로직 수행이 잘 되었는지 아닌지 판단하는 부분도 있어야 할 듯 했다. 그래서 '비즈니스 로직 수행자'라는 이름은 좀 이상하지만 이런 객체를 따로 빼 두어 시퀀스 다이어그램을 보완하기로 했다.
비즈니스 로직 수행자를 넣어 시퀀스 다이어그램을 다시 그려보니 이제 뭔가 맞아 돌아가는 느낌이 들었다.
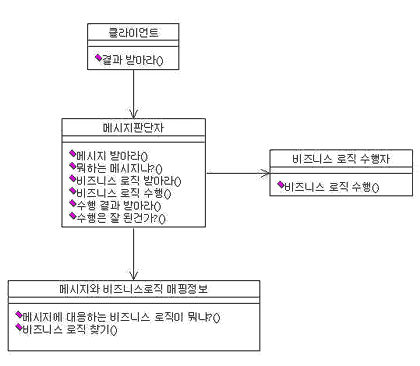
UML의 시퀀스 다이어그램과 클래스 다이어그램을 통해 객체간에 교류와 각 객체의 책임(Responsibility)를 찾아냈다.
설계를 위한 모델로 발전
이제 개념적으로 정리한 모델을 바탕으로 좀 더 구현하기 좋은 형태로 발전시켜 보자. 구현을 위해서는 좀 구체적인 형태로 정의하고 실제적인 비즈니스 로직 처리와 에러 처리를 표현하기 위한 무엇인가가 필요했다. 고과장은 고민 끝에 웹 서버로부터 아이디어를 얻었다. 웹 서버는 웹 브라우저와 커뮤니케이션을 위해 Request와 Response를 사용한다. 브라우저의 요청은 Request에 담아 웹 서버로 보내고 웹 서버의 응답은 Response에 담아 브라우저로 보내게 된다. 이런 비슷한 개념을 프레임워크에 적용해보면 어떨까 생각했다.
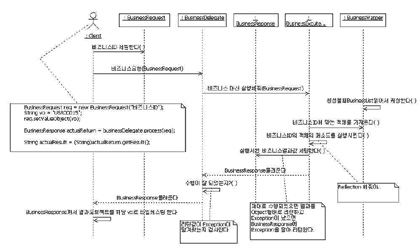
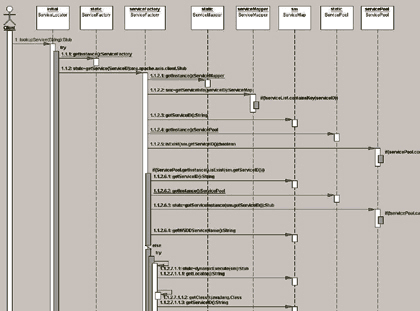
즉, 클라이언트의 요청은 BusinessRequest에 담아 보내고 서버의 응답은 BusinessResponse에 담아 보내되, 비즈니스 로직 수행시 Exception이 발생하면 BusinessResponse에 담아 메시지 판단자가 처리하게 하면 어떨까 하는 생각을 했다. 고과장은 이렇게까지 생각이 정리되자 시퀀스 다이어그램을 통해 아이디어를 구체화 해보기로 했다. 시퀀스 다이어그램은 <그림 6>과 같다.
|
|
| <그림 6> 보다 더 구체화된 시퀀스 다이어그램 |
클라이언트 쪽의 예상 소스코드도 넣어 보고 메시지를 비즈니스ID라는 용어로 바꿔봤다. 또한 비즈니스ID의 해당 비즈니스 로직을 실행시키기 위해서는 리플렉션(Reflection)이라는 기술도 써야 할 것 같고 Exception 처리를 위한 부분도 따로 둬야겠다는 생각이 들어 BusinessResponse에 BusinessExcuteHelper가 Exception을 담아주는 형태로 모델링을 했다.
<그림 6>의 시퀀스 다이어그램을 보면 중간 중간 노트가 많이 달려있는 것을 볼 수 있다. 시퀀스 다이어그램의 중간 중간을 보면 샘플 코드나 리플랙션, Exception과 같은 구현을 염두 한 노트를 볼 수 있다. UML로 모델링을 할 때 노트의 역할은 필수 불가결한데 해당 다이어그램의 이해를 돕기 위해서나 모델러의 의도를 명확히 하기 위해서 또는 아직 불분명한 부분이 있을 경우 판단에 도움이 될 만한 주석을 달기 위한 수단으로 이용하면 좋다.
구체화된 모델
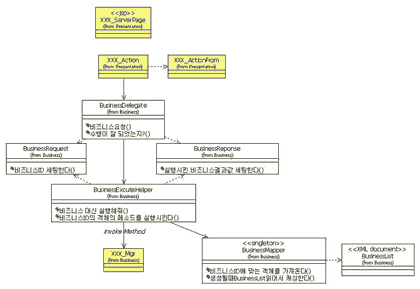
자 이제 구현을 위한 시퀀스 다이어그램도 그렸고 구체적으로 어떻게 접근하면 될지 방안이 섰기 때문에 최종 클래스 다이어그램을 그려보기로 했다. 클래스 다이어그램을 그리면서 고과장은 클라이언트가 보내는 메시지와 해당 비즈니스 로직 정보를 어떤 형태로 할 까 고민하다 XML 형태로 하는 것이 가장 좋을 것 같다는 판단이 들었다.
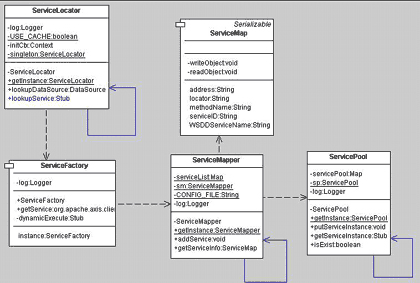
애플리케이션이 실행되면서 XML에 있는 정보를 읽어 캐싱하고 있는 형태로 만들고 그 역할은 BusinessMapper라는 객체에 해당 정보를 Map에 담아 두기로 했다. BusinessMapper는 단 하나만 존재해야 하므로 싱글턴(Singleton) 패턴을 적용하기로 했다(실제 구현을 하기 위해서는 보다 더 구체적으로 모델링을 해야겠지만). <그림 7>는 고과장의 아이디어를 반영한 최종 클래스 다이어그램이다.
|
|
| <그림 7> 고과장 생각을 정리한 최종 클래스 다이어그램 |
이 클래스 다이어그램에서 XXX_ServerPage나 XXX_Action, XXX_ActionForm, XXX_Mgr과 같이 XXX라는 접두어가 붙은 클래스는 비즈니스 로직 개발자들이 직접 만들어야 하는 부분이다. 개발자들은 XXX라는 접두어가 붙은 클래스만 개발하면 되고 고과장이 만든 프레임워크에 끼워 넣어 어떤 메시지가 어떤 비즈니스 로직과 맵핑되는지 XML 파일만 편집하면 되는 구조로 모델링이 되었고 고과장의 생각대로 메시지와 비즈니스 로직과의 느슨한 관계를 유지할 수 있는 모델이 만들어 졌다.
일단 이런 구조의 프레임워크가 좋은 것인지 아닌지는 일단 논외로 하고 머릿속의 아이디어를 모델로 구체화하는 과정을 다시 한번 정리하자면 우선 1) 머릿속의 아이디어를 글로 정리하고 2) 정리한 글을 바탕으로 UML로 바꿔 본다. 이때 동적인 측면과 정적인 측면을 고려하고 전에 정리한 글에서 UML로 변환하는 과정에서 빠진 것은 없는지 미처 생각하지 못한 것들이 있는지 확인한다. 그냥 글로 확인하는 것보다는 UML의 시퀀스 다이어그램이나 엑티비티 다이어그램 등을 이용하여 확인하면 보다 더 정확하게 모델링할 수 있다. 3) 이렇게까지 진행이 되었으면 실제 구현을 위한 모델로 발전시켜 본다. 특정 플랫폼이나 개발언어, 미들웨어 등을 고려하면서 그려나간다.
결국 1)~3)까지가 실제 모델링을 통해 아이디어를 구체화 시켜나가는 모든 것이다. 1)번을 잘 하기 위해 각종 기법(예를 들어, 유스케이스나 유저스토리 등)이 동원되고 2)번을 잘 하기 위해 CRC 카드와 같은 기법이 사용된다. 3)번 역시 마찬가지로 각종 설계 패턴이나 J2EE 패턴과 같은 것을 참조한다. 개발 프로세스에 따라 어떤 모델을 만드는가, 어떤 산출물을 만드는가에 따라 그려야 할 다이어그램이나 모델의 정밀도가 다르겠지만 결국 1)~3)까지의 행위를 반복함으로써 우리가 얻고자 하는 모델을 얻어낼 수 있다.
쉽고도 어려운 유스케이스 모델링
1960년대 후반쯤 이바 야콥슨에 의해 만들어진 유스케이스는 1990년대에 들어서면서 아주 폭넓게 사용하는 요구사항 파악 및 분석 기법으로 자리 잡았다. 우리나라의 경우 아마도 대부분의 프로젝트에서는 유스케이스라는 이름의 산출물을 만들고 있고 만들었을 것이다. 필자도 여러 프로젝트를 하면서 유스케이스를 써서 요구사항 분석을 했었다.
초기 접근하기에 개념적으로 어려운 부분이 별로 없기 때문에 누구나 의욕적으로 참여하여 유스케이스를 작성해 해 나간다. 하지만 이 유스케이스라는 것이 단순해 보이지만 결코 만만치 않은 특성을 갖고 있다. 처음에는 쉬운 듯하지만 진행해 나갈수록 어려워지는 경향이 있다. 또한 프로젝트의 진행 상태나 규모에 따라 유스케이스 작성 방식이 달라진다. 이러한 특성 때문에 바쁜 프로젝트에서 뭔가 별 고민을 하지 않고 쉬운 작성 형식이나 방법을 목말라하는 개발자들에게는 혼돈의 연속일 수밖에 없다.
필자 개인적으로 유스케이스에 관해 잘 설명한 도서는 Alistair Cockburn의 『Writing Effective Use Cases (2001)』이다. 영어에 어려움을 겪는 분들은 번역본도 나와 있으니 구해서 한번 꼭 읽어보길 바란다. 이 책의 내용 중에 유스케이스 작성시 주의할 점이 있는데 그 중 현장에서 실제로 많이 나타나는 몇 가지를 소개하고자 한다. 일부 주의사항은 책에서 발췌하고 필자가 느낀 점을 중심으로 설명해본다.
유스케이스는 산문체 수필이다
유스케이스 다이어그램을 갖고 지지고 볶던 독자들에게는 약간 의아한 말일 수 있다. 사실 유스케이스는 텍스트 기반의 서술이다. UML의 유스케이스 정의를 보아도 '유스케이스는 시스템 전체나 유스케이스 일부 행동을 명세화 하고 순차적으로 발생하는 활동들을 서술하는 것이다. 시스템은 이러한 활동을 수행하여 액터에게 원하는 결과를 준다'라고 되어 있다. 그래픽으로는 타원으로 표현하고 중심에는 몇 단어로 이루어진 이름이 있다.
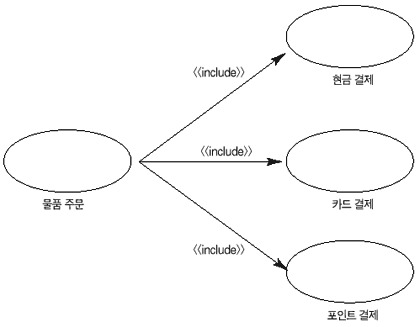
프로젝트를 진행하면서 다이어그램에 얽매여 오로지 다이어그램만으로 유스케이스를 작성하려고 하면 관련 팀은 점점 어려움으로 빠져 들게 된다. 유스케이스 다이어그램 그 자체가 담고 있는 정보는 매우 한정적이다. 유스케이스명과 어떤 액터와 관계가 있는지를 나타내는 선 몇 개, 복잡하게 뒤 얽힌 '포함(include)와 확장(extends)을 표현하는 점선들이 뒤덮여 있을 뿐이다. 사람들이 그 다이어그램을 보고 요구사항이 뭔지 정확하게 알 수 있을까?
단어 몇 개로 이루어진 유스케이스 명을 보고 무엇을 하는 유스케이스인지 추측을 할 뿐이다. 다이어그램의 정보가 충분치 않으므로 답답한 마음에 다이어그램에 갖가지 정보를 넣으려고 하고 유스케이스의 목표 수준은 점점 내려가고 복잡해지는 현상이 나타난다. 결국 아무도 이해할 수 없는 다이어그램이 만들어지면서 오히려 팀간의 명확한 이해의 공유는커녕 혼란만 가중시키는 결과를 낸다. 유스케이스 다이어그램만을 놓고 이틀 동안 논쟁만 하는 개발팀을 실제로 보았다. 다시 한번 강조하지만 유스케이스는 텍스트 형식의 서술이다. 액터와 유스케이스 간에 어떤 일이 일어나는지 글로 적음으로써 이해를 명확히 할 수 있다.
유스케이스와 사용자 매뉴얼
유스케이스 교육을 들어 봤거나 프로젝트를 해 본 분들이면 아마도 귀가 따갑게 유스케이스는 GUI에 관한 부분은 적지 않는 것이라고 들어왔을 것이다. 유스케이스를 작성하면서 유저 인터페이스에 관한 내용을 언급하기 시작하면 유스케이스가 점점 사용자 매뉴얼이나 화면 설계서처럼 변해간다.
유스케이스는 향후 작성할 분석/설계 모델이나 화면 설계 등의 모델의 기본 정보를 제공한다. 또한 유스케이스로 추적(Trace)할 수 있다. 아니 추적되어야 한다. 사용자 매뉴얼이나 화면 설계서가 분석/설계 모델의 상위 요건이 될 수 있는가? 결코 그렇지 않다. 유스케이스는 적당한 목표수준으로 작성함으로써 상위 요건으로써의 역할을 다 할 수 있어야 한다.
포함과 확장의 오남용
어떤 유스케이스 다이어그램을 보면 다이어그램 가득히 실선과 점선이 어지럽게 꼬여 있는 그림을 가끔 본다. 왜 이런 다이어그램이 나오는지는 앞에서 언급하였다. 필자의 경우 이런 다이어그램은 십중팔구 뭔가 잘못되었을 것이라는 예감이 뇌리를 스친다. 우선 복잡하면 제대로 파악할 수 없고 서로 이해를 명확하게 하지 못했을 가능성이 높으며 이해도가 떨어지는 상황에서 유스케이스가 제대로 작성되었을 리가 없다.
유스케이스 다이어그램이 복잡하면 각 유스케이스의 이벤트 흐름을 작성하면서 아주 여러 부분에 포함(include)과 확장(Extends)이 나타나게 되고 결국 전체적으로 유스케이스의 유지보수를 어렵게 만든다. 유지보수가 어렵게 되면 요구사항을 정확히 담는데 점점 힘들어지고 현실과 동떨어진 그저 서로 다른 이해수준으로 각자의 머릿속에만 존재하는 요구사항이 나오게 된다.
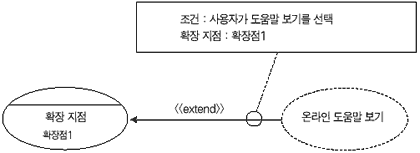
최초 확장이라는 개념이 등장하게 된 이유는 이전 시스템의 요구사항 파일을 건드릴 수 없다는 실행 지침 때문이었다(Alistair Cockburn, 2001). 그 당시 개발팀의 임무는 새로운 서비스를 추가하는 것이었고 기존의 요구사항 문서를 건드릴 수 없는 상황에서 원래의 요구사항은 한 줄도 건드리지 않은 채 새로운 요구사항을 추가했다. Alistair Cockburn은 확장이 필요할 경우 다이어그램 상에서 보여주지 말고 기존 유스케이스 안에서 확장 유스케이스의 참조를 그저 텍스트로 서술할 것을 권유한다. 다이어그램에 복잡하게 확장을 표현함으로써 정작 중요한 유스케이스를 볼 수 없게 만들기 때문이다. 필자도 그의 주장에 동의 한다.
케이스 툴로 유스케이스 작성하기
케이스 툴로 유스케이스를 작성한다는 것이 잘못되었다는 것은 아니다. 오히려 케이스 툴이 활용상의 문제로 인해 정확한 유스케이스를 작성하는데 걸림돌로 작용하는 현상을 이야기하고 싶은 것이다. 필자는 지금까지 프로젝트를 진행하면서 유스케이스의 고단함에 대해 무척 많은 고민을 했었다. 일반적으로 개발자들은 작문을 싫어하는 습성이 있지만 요구사항을 파악하고 분석하는 사람들은 일반 고객과의 의사소통이 많기 때문에 산문 형식의 문서 작성(Technical Writing)에 능숙해야 함에도 불구하고 대부분의 프로젝트에서는 이러한 사실을 애써 외면한다.
작성하기 귀찮은 유스케이스를 케이스 툴로 그리고 끝내 버리려는 생각을 한다. 사실 필자도 예외는 아니어서 웬만하면 케이스 툴에서 모든 걸 해결하고 싶은 유혹에 항상 시달렸다. 하지만 대부분의 케이스 툴은 유스케이스를 서술하기 위한 조그만 다이얼로그 창만을 제공한다. 유스케이스를 기술한 문서를 따로 하이퍼링크 방식으로 케이스 툴과 연결하는 방법을 주로 취했는데 사실 힘들고 불편하다. 만약 어떤 케이스 툴의 기능 중에 일정한 유스케이스 작성 형식의 레이아웃을 디자인할 수 있고 그 템플릿 안에서 유스케이스를 작성하면 다이어그램이 역으로 만들어지는 케이스 툴이 있다면 얼마나 좋을까 하는 생각을 해본다. 언제쯤이면 편하게 유스케이스 모델링을 할 수 있는 케이스 툴이 나올까?
분석/설계 모델과 MDA
분석(分析)은 그 단어의 의미에서도 알 수 있듯이 무엇인가를 어떠한 목적 때문에 나누어(分) 쪼개는(析)것이다. 소프트웨어 개발에서 나누어 쪼개야 할 필요가 있는 부분은 문제 영역으로 시스템을 개발하는 사람들이 문제 영역을 올바로 이해하기 위한 목적으로 분석을 한다. 이해한 것을 즉시 시스템으로 만들 수 없으므로 중간에 문제 영역의 이해와 실 시스템간의 가교역할을 하는 것이 있는데 그것이 바로 설계이다.
사실 웬만하면 설계를 하지 않고 시스템을 만들고 싶은데 구현 언어나 플랫폼 등의 영향을 많이 받기 때문에 분석한 결과를 바로 시스템화하기 힘든 것이다. 현재 분석에서 설계를 거치지 않고 바로 실 시스템으로 건너가기 위한 노력이 진행되고 있는데 독자 여러분들도 잘 알다시피 MDA(Model Driven Architecture)가 그것이다.
현재 소프트웨어를 만드는 사람들의 작업 행태는 당연하게 생각되지만 지루하게도 4단계를 거친다. 문제 영역을 파악하고 분석하여 그 결과를 바탕으로 설계한 후 소프트웨어를 구현한다. 만약 정말 MDA가 활성화 된다면 중간에 1가지 단계가 빠지는 3단계 개발 공정이 나올 것이며 그저 요구사항 파악해서 분석 모델을 만들어 놓으면 실행 시스템이 튀어나오는 정말 환상적인 세상이 오지 않을까 싶다. 그런데 정말 이런 세상이 가능할까?
현 컴퓨팅 시스템은 다 계층 분산 시스템인 관계로 많은 설계 요소와 다양한 관련 기술이 필요하다. 이 모든 기술을 모두 알 수 없으므로 특정 기술 기반을 가진 사람들이 한 프로젝트에 모여 개발을 하고 그 중 충분한 경험과 깊은 지식을 갖고 있는 누군가가 아키텍트라는 역할로 소프트웨어 개발을 이끌고 나간다.
아키텍트라는 일반 비즈니스 로직 개발자들의 개발 자유도를 통제하기 위해 '메커니즘'이 라는 것도 만들어 놓고, 마음이 안 놓이는지 '프레임워크'라는 것도 만들어 놓아 오직 비즈니스 로직 구현에 몰두할 수 있게 만들어 놓는다. 비즈니스 로직 개발하는 것도 '패턴'이라는 이름으로 개발하는 방식을 제한하는 경우가 많다. MDA에서는 이러한 부분을 프로파일로 작성한다. 이 프로파일을 바탕으로 비즈니스 분석 모델을 빌드하면 실행 컴포넌트가 나오게 된다.
현재도 제품으로 출시되어 있는 MDA 솔루션들이 있다. 필자가 보기엔 어떤 솔루션은 무늬만 MDA인 것도 있고 실제 MDA의 비전에 상당히 근접한 솔루션도 있었는데 모델링 도구에서 모델을 만들고 OCL을 작성해 놓으면 놀랍게도 실제로 시스템이 작동했었다. 다만 일부 표준을 지원하지 않아 문제가 되긴 했지만 말이다.
하지만 언젠가는 MDA가 우리 피부에 와 닿을 정도로 현실화 되리라 믿는다. 초창기 컴퓨팅 환경에서 고급 언어로 일컫는 3세대 언어들은 그 당시 개발자들에겐 환상적인 꿈의 개념이었다고 한다. 기계어와 어셈블리 수준에서 프로그래밍을 하던 그들에게는 자연어와 비슷한 모양의 개발 언어는 얼마나 환상적으로 보였을까? 지금 우리는 이와 같은 과도기를 겪고 있다고 필자는 생각한다. 독자 여러분들도 그런 시대를 대비하여 하루빨리 모델링 능력을 한껏 끌어올리기 바란다.
자바 웹 애플리케이션 모델링
만약 개발 프로세스가 비슷하다면 그 프로세스를 적용하여 개발하는 모든 애플리케이션 모델링의 방법은 거의 유사하다. 웹 애플리케이션이라고 해서 별다르게 특이한 것은 없겠지만 웹 애플리케이션의 특성상 몇 가지 짚고 넘어갈 부분이 있다. 사실 엄밀하게 말 하면 웹이라는 특성도 있지만 자바의 특성으로 인해 모델링 방법이 약간 달라지는 수준으로 볼 수 있다. 특히 현 엔터프라이즈 컴퓨팅 환경은 다 계층 분산 시스템이므로 계층과 분산에 관한 부분의 모델링이 강조된다.
또한 사용자 웹 인터페이스 모델링도 중요한 부분으로 생각할 수 있다. 웹 페이지의 특성상 HTML이라는 제약으로 인해 약간 특이한 점이 있다. 웹 페이지 모델링에서 폼(form)과 같은 구성요소는 스테레오 타입(stereo type)으로 정의하여 모델링을 한다. 또 웹 페이지는 화면의 흐름에서 해당 정보를 갖고 다니거나 세션을 참조하기 때문에 어디까지 해당 정보를 갖고 다닐지 세션을 어떻게 참조할 지가 모델링의 주요 포커스가 된다. 일단 개요 수준은 여기까지 하고 실제 예제를 보면서 모델링이 어떻게 진행되는지 살펴보자.
분석 모델
좀 전에도 언급했듯이 웹 애플리케이션도 역시 다른 시스템과 마찬가지로 요구사항 파악 및 분석으로부터 시작한다. 요구사항을 위한 모델링으로 유스케이스를 이용하는 것은 이미 앞에서 이야기했고 특집 4부에서 자세히 다룰 예정이므로 유스케이스 자체에 관한 설명은 하지 않겠다. 또한 웹 애플리케이션이나 다른 기술을 이용한 애플리케이션이나 요구사항과 분석 모델링의 기법은 사실 별반 다르지 않다. 분석 모델은 구현과 관계가 없는데 분산(distribution), 영속성(persistency), 커뮤니케이션(communication), 인증(authentication)과 같은 메커니즘과 상관없는 개념적인 모델이기 때문이다. 즉, 유스케이스 모델을 기반으로 분석관점으로 유스케이스 실현(realization)을 표현한 객체모델이 바로 분석 모델이다.
<그림 8>은 분석 모델의 유스케이스 실현(realization)에 참여하는 분석클래스 다이어그램이다. RUP에 의하면 분석클래스는 <<boundary>>, <<control>>, <<entity>> 등 세 가지 종류의 스테레오 타입을 갖는다. 원래 스테레오 타입은 태기드 벨류(tagged value)와 함께 UML의 확장 메커니즘의 한 종류이기 때문에 필요하다면 추가적인 스테레오타입을 정하여 사용하여도 무방하다.
사용자 웹 인터페이스 모델링
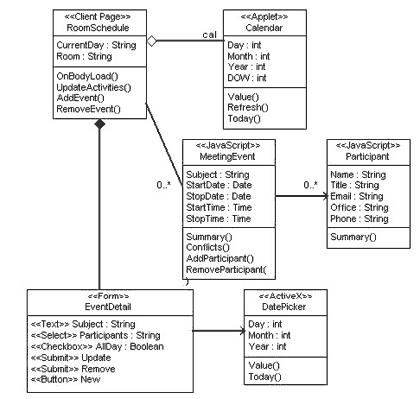
사용자 웹 인터페이스 모델링 부분은 웹 애플리케이션을 개발하면서 모델링 하기에 가장 껄끄러운 부분이 아닌가 생각된다. Jim Conallen은 그의 저서 『Modeling Web Application Architectures with UML(2002)』에서 웹 인터페이스 모델링을 자세히 설명하고 있다. 한마디로 요약하자면 웹 애플리케이션 모델링을 위한 다양한 '스테레오 타입'을 만들어 냈다.
필자가 보기에는 실무 프로젝트에서 과연 이런 노가다 작업을 할 필요가 있을까 생각이 되지만 순수 모델링 관점에서 볼 때 웹 페이지를 모델링 하기 위한 작업으로서 의미는 있다고 본다. <그림 9>는 그가 제안한 웹 페이지를 모델링 예제이다. 참고하기 바란다.
|
|
| <그림 9> Jim Conallen이 제안한 웹 인터페이스 모델링 예 |
실무 프로젝트에서 Jim Conallen이 제안한 방법으로 모델링 하는 경우를 본적은 없고 필요한 부분만을 발췌해 많이 단순화시킨 형태로 모델링을 진행한다. 사용자 인터페이스 모델은 화면 흐름, 참여 화면의 설명, 화면 이동 맵, 화면 클래스 다이어그램, UI 프로토타입 등으로 구성된다. 이중 UML로 모델링 하는 몇 가지를 소개하겠다.
화면 흐름
화면 흐름의 경우 비즈니스 로직 처리와는 전혀 관계없이 오직 해당 작업을 수행하기 위한 화면 관점에서 모델링을 한다.
|
|
| <그림 10> 시퀀스 다이어그램으로 표현한 화면 흐름도 |
화면 이동 맵
화면 이동 맵은 각 화면의 구성 요소를 클래스 다이어그램으로 표현한 것이다.
|
|
| <그림 11> 클래스 다이어그램으로 표현한 화면 이동 맵 |
웹 애플리케이션을 위한 프레임워크 모델링
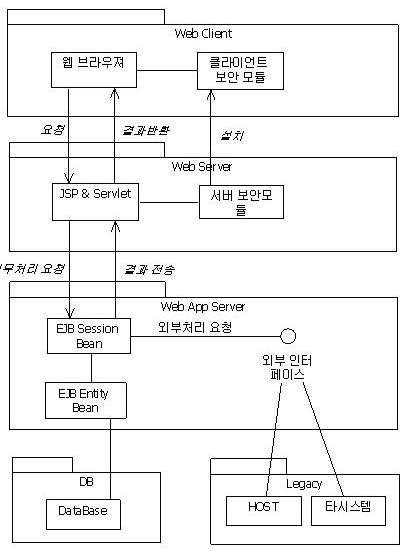
자바를 이용하여 웹 애플리케이션을 개발하게 되면 우선 여러 제약 사항들이 나타나게 된다. 앞서 이야기한 페이지 제어 문제, 세션 처리 문제, 데이터 처리 문제, 다양한 프로토콜의 처리 문제, 까다로운 보안 문제, 웹과 분산 컴포넌트간의 동적 호출 문제, 예외처리 문제, 웹 애플리케이션과 레거시(legacy)와 인터페이스 문제 등 각 메커니즘에 관해 다루어야 할 부분이 많다. <그림 12>는 각 메커니즘을 고려한 일반적인 웹 애플리케이션의 시스템 구성도이다.
|
|
| <그림 12> 일반적인 웹 애플리케이션의 시스템 구성도 |
이 그림에서 메커니즘으로 정리해야 할 주요 부분은 여러 가지가 있지만 그 중에서 Web Server와 Web App Server와의 연동 부분으로 JSP에서 어떠한 Action을 통해 EJB 비즈니스 컴포넌트를 수행시키고자 하는 부분과 데이터 처리하는 부분, 타 시스템과 인터페이스 기술을 만약 웹 서비스로 할 경우 웹 서비스 클라이언트와 웹 서비스 서버간의 메커니즘 등을 들 수 있다. 몇 부분에 대한 메커니즘에 대하여 모델을 보면서 살펴보자.
JSP에서 Action을 통해 비즈니스 컴포넌트를 수행하는 부분
이 부분의 경우 프리젠테이션 레이어와 비즈니스 레이어간의 느슨한 결합을 지원하기 위해 J2EE 패턴 중에 '비즈니스 델리게이트 패턴(business delegate pattern)'을 사용할 수 있다. 원래 비즈니스 델리게이트 패턴은 비즈니스 서비스 컴포넌트와 일어나는 복잡한 원격 통신에 관련된 사항을 클라이언트로부터 숨기기 위해 사용한다. 비즈니스 델리게이트에 관해 자세한 것을 알고 싶으면 자바 웹 사이트나 코어 J2EE 패턴을 참고하면 된다.
다음에 소개할 프로젝트의 상황 때문에 약간 변경이 되었는데 비즈니스 델리게이트는 원격 통신에 관한 처리와 함께 해당 프로젝트의 사정으로 EJB 비즈니스 컴포넌트와 일반 자바 클래스 형태의 비즈니스 컴포넌트, 그리고 웹 서비스를 통해 타 시스템의 비즈니스 컴포넌트도 함께 수행해야 했다.
따라서 비즈니스 컴포넌트가 EJB건 일반 자바 클래스건 SOAP 기반의 통신이던 간에 클라이언트는 그저 비즈니스 컴포넌트 아이디와 비즈니스 컴포넌트 쪽에 넘겨줘야 할 파라미터만 알고 있으면 되도록 설계하였다. 해당 비즈니스 컴포넌트는 비즈니스 델리게이트에서 리플렉션을 이용해 동적으로 수행되도록 했다.
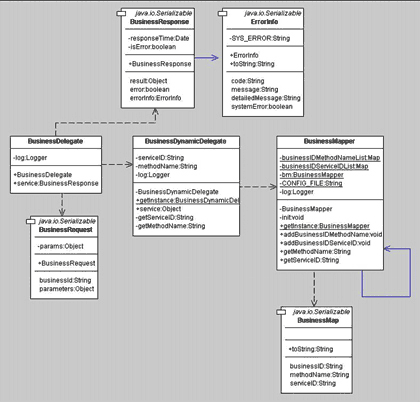
|
|
| <그림 13> 비즈니스 델리게이트 부분의 클래스 다이어그램 |
<그림 13>에서 BusinessMapper의 역할은 XML 형태의 컨피규레이션(Configuration)로 빠져있는 파일을 읽어 웹 애플리케이션이 기동할 때 캐싱하게 된다. 이 컨피규레이션 파일에 담겨있는 정보를 바탕으로 BusinessMap 클래스가 모델의 역할을 하게 되는데 BusinessMapper는 BusinessMap을 자신이 갖고 있는 Map에 담아 갖고 있는다. 또한 BusinessMapper는 JVM상에 오직 하나만 존재해야 했으므로 '싱글턴 패턴(singleton pattern)'을 적용하였다. 이것을 실제로 구현하기 위해서 필자는 자카르타의 커먼스(commons)의 다이제스터(digester)를 이용하여 구현했다.
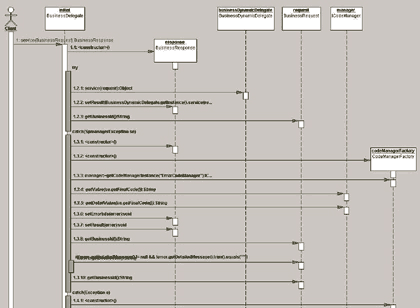
|
|
| <그림 14> 비즈니스 델리게이트 부분의 시퀀스 다이어그램 |
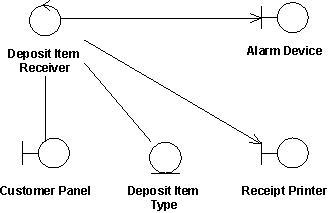
외부 시스템과 연동 부분
웹 서비스의 SOAP을 이용한 통신을 하기 위해서는 웹 서비스 RMI 리모트 인터페이스를 상속한 인터페이스를 상속한 스텁(stub)을 통해 비즈니스 컴포넌트를 수행하게 된다. 이 부분은 위에서 설명한 비즈니스 델리게이트 부분과 아주 관련이 깊은데 일반 자바 비즈니스 컴포넌트의 경우 같은 머신의 동일 컨텍스트에 존재하므로 스트럿츠 액션(Struts Action)에서 비즈니스 델리게이트를 통해 바로 부르면 비즈니스 델리게이트는 그저 리플렉션을 통해 해당 비즈니스 컴포넌트를 실행하면 된다.
하지만 웹 서비스 비즈니스 컴포넌트인 경우는 다른 머신에 존재하는 컴포넌트이므로 원격 호출에 대한 부분 동일한 방법으로 서비스의 위치를 찾아낼 수 있도록 J2EE 패턴 중에 '서비스 로케이터 패턴(service locator pattern)'을 이용하였다. 이 부분 역시 약간의 변형이 가해졌는데 다이내믹 바인딩 시간이 비교적 길기 때문에 서버에서 받아온 스텁을 웹 애플리케이션 서버 쪽에 풀(pool)을 하나 만들어 스텁을 한번 가져온 이후 풀에 넣어놓고 다음 호출부터는 풀에서 꺼내어 쓰도록 설계하였다. 필자는 이런 설계를 구현하기 위해 자카르타 커먼스에 있는 풀(pool)을 이용하였다. EJB의 경우도 이와 거의 유사하다. <그림 15, 16>은 웹 서비스 부분의 클래스 다이어그램과 시퀀스 다이어그램이다.
|
|
| <그림 15> 웹 서비스 부분의 클래스 다이어그램 |
|
|
| <그림 16> 웹 서비스 부분의 시퀀스 다이어그램 |
데이터 처리 부분
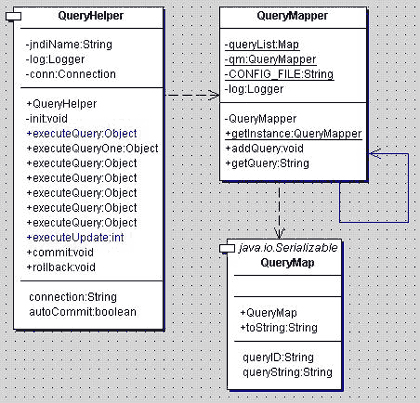
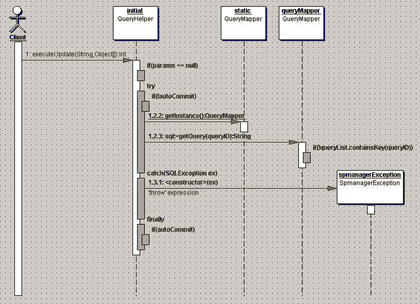
필자가 이 부분을 설계하고 구현해 놓고 보니 사실 메커니즘이라기보다는 일종의 유틸리티성의 헬퍼 클래스 성격이 짙었다. 주요 특징 중에 하나는 SQL 쿼리를 소스코드에 직접 넣지 않고 XML 형식의 파일로 뽑아내었다는 것이다. 데이터베이스를 통해 데이터를 주고받아야 하는 비즈니스 컴포넌트 입장에서는 쿼리 아이디와 Object 배열에 담긴 파라미터를 QueryHelper에 넘겨주면 쿼리를 실행하고 결과를 넘겨준다.
결과는 여러 형태로 받을 수 있는데 종류로는 Map 형태, Map의 리스트 형태, 특정 Bean 형태, Bean의 List 형태로 Object 객체에 담아 받아 올 수 있다. 필자는 이런 설계를 구현하기 위해 자카르타 커먼스에 있는 디비유틸(DBUtil)을 이용하였다. <그림 17, 18>은 데이터 처리 부분의 클래스 다이어그램과 시퀀스 다이어그램이다.
|
|
| <그림 17> 데이터 처리 부분의 클래스 다이어그램 |
|
|
| <그림 18> 데이터 처리 부분의 시퀀스 다이어그램 |
컴포넌트 모델링
컴포넌트 모델링의 과정은 컴포넌트를 식별하고 그것의 인터페이스를 정의하고 컴포넌트의 내부는 어떻게 작동하며 구현을 어떻게 할 건지에 대한 종합적인 과정이 필요하다. CBD(Component Based Development)에는 많은 이견들이 있지만 이 글에서는 현존하는 기법을 통해 컴포넌트 식별 방법을 아주 간략하게 설명하고 컴포넌트 모델링과정이 어떻게 진행되는지 궁금해 하는 독자들을 위해 각종 다이어그램을 보면서 살펴보기로 한다.
◆Catalysis :타입과 조인트 액션을 중심으로 상호작용을 분석하여 네트워크 다이어그램을 만들고, 결합력과 응집력을 고려한 메트릭을 만들어 컴포넌트 식별한다.
◆마르미III :유스케이스/클래스 연관 메트릭을 사용하여 각 유스케이스와 관련 있는 클래스를 클러스터링 하여 컴포넌트 후보로 등록한 다음 다른 유스케이스도 분석하여 이전에 후보로 등록되었던 컴포넌트가 쓰이면 나머지 유스케이스도 활용할 수 있도록 인터페이스를 공개한다. 유스케이스/클래스 연관 메트릭을 분석하기가 좀 어려운 것 같다. 실무에서 활용 가능할지 의문시 된다.
◆UML Components :비즈니스 타입 모델에서 타입을 식별하고 이 타입을 관리할 책임이 있는 인터페이스를 정의한다. 식별된 인터페이스의 상호작용을 분석함으로써 서로간의 의존관계를 파악/정제하여 컴포넌트를 제안한다. 분석가의 경험에 많이 의존하는 경향이 있다.
◆RUP :분석/설계가 상당히 진행된 후 각 클래스를 종횡으로 묶는 방식을 취한다. 초기 컴포넌트 식별은 불가능 하다.
컴포넌트 인터페이스 정의
어찌됐던 간에 컴포넌트를 식별했으면 인터페이스를 정의한다. 이 단계에서 정의되는 컴포넌트 인터페이스는 Business Facade의 성격으로 각 인터페이스를 명세화 한다.
컴포넌트 내부 설계
컴포넌트 내부 설계는 앞에서 정의한 인터페이스를 구현하기 위한 설계를 일컫는다.
|
|
| <그림 20> 컴포넌트 내부 설계 클래스 다이어그램 |
EJB 컴포넌트 설계
EJB 컴포넌트 자체에 관한 설계로 <그림 21>은 Customer 비즈니스 컴포넌트의 워크플로우를 관리하고 클라이언트 요청에 대해 Facade 역할을 수행하는 Stateless Session Bean 에 대한 클래스 다이어그램이다.
|
|
| <그림 21> EJB 컴포넌트 설계 클래스 다이어그램 |
유능한 모델러로 거듭나기
지금까지 개발 프로세스 측면에서 바라본 모델링과 자바 웹 애플리케이션을 위한 모델을 보았다. 사실 아주 많은 내용을 한정된 페이지에 집어넣으려고 하다 보니 주마간산 격이 되어버렸는지도 모르겠다. 모델링이라는 것이 개인적인 주관과 경험에 많은 영향을 받는 것은 사실이다.
필자는 지금까지 모델링과 관련된 프로젝트와 교육을 여러 번 해보았지만 아직까지 잘된 모델링은 바로 이런 것이라고 꼭 집어 이야기하기 힘들다. 다만 어떤 모델은 보면 왠지 푸근하고 어떤 모델은 왠지 어색하다는 느낌이 든다. 그 느낌이 뭐라는 것도 아직 정확히 모르겠지만 말이다. 모델링을 잘 하기 위해 어떻게 트레이닝을 해야 할까라고 고민하던 중에 필자가 겪었던 짧은 경험이 떠올랐다.
올해 여름에 비슷한 일을 하는 사람들과 함께 어느 업체에 방문했던 적이 있었다. 날씨는 아주 더웠지만 차 안은 에어컨을 켜서 시원했다. 문제는 주차장에 차를 세워놓고 몇 시간 동안 뜨거운 여름 뙤약볕 아래 차를 세워놔야 하므로 일을 마치고 돌아올 시점에는 차 안이 불가마 찜질방 수준으로 될 거라는 것은 충분히 예상할 수 있는 상황이었다. 그때 누군가 “그늘 아래 세워놔야 할 텐데”라고 하자 어떤 사람이 “그늘 오리엔티드(Oriented)구먼”이라고 응수했다. 그러자 또 누군가 “오리엔티드는 아니지, 오리엔티드는 왠지 그늘 자체가 되어야 하는 듯한 느낌을 준다고, 그늘 드리븐(Driven)이 맞지 않을까? 드리븐은 목표를 향해 돌진하는 느낌을 주자나? 결국 우리는 지금 그늘을 찾아가고 있는 거고”라고 했다. 이때 필자는 “음~ 정확히 말하자면 그늘 베이스드(Based)가 어울릴 것 같은데? 우리는 그늘을 베이스로 깔고 앉아야 하잖아?”라고 주장하여 모두들 웃으며 짧은 말장난을 했던 기억이 있다.
예로 든 이야기에서 그 상황에 오리엔티드(Oriented)나 드리븐(Driven), 베이스드(Based)라는 용어의 의미에 정확하게 맞았는지는 일단 논외로 하겠지만 실제 모델링을 하는 상황에서는 이와 같은 일들이 자주 일어난다. 모델링을 하는 사람들은 그 상황에 맞는 의미를 정확히 파악하여 모델을 만들기 위한 노력을 끊임없이 해야 하고 특히 용어, 단어의 의미, 그리고 단어간의 관계에 대하여 고민해보고 정확하게 짚고 넘어가는 버릇을 들여야 하지 않을까 싶다.
우리가 지금 주제로 이야기하는 UML을 이용한 모델링이라는 것이 결국 모호성이 아주 높은 자연 언어를 몇 개의 모델링 요소로 표현하는 작업이기 때문에 소프트웨어 모델링을 할 때만 모델에 대하여 생각하는 것이 아니라 실생활 속에서 패러다임에 맞게 사고하는 지속적인 훈련을 해야만 한다.
앞에서 MDA에 관하여 짧게 언급 했지만 아마 앞으로 소프트웨어 개발에 있어서 모델은 점점 더 중요한 요소로 부각될 것이다. 필자도 그렇고 이 글을 읽는 독자 여러분도 지속적인 수련을 통해 더욱 유능한 모델러로 거듭나리라 믿는다.@
* 이 기사는 ZDNet Korea의 제휴매체인마이크로소프트웨어에 게재된 내용입니다.
고재현
2005/03/26
[UML 제대로 알기] ① 가능성·확장성 품고 등장한 UML 2.0
연재순서
1회.가능성·확장성 품고 등장한 UML 2.0
2회.초보자를 위해 다각도로 살펴본 UML
3회.바로 알고 제대로 쓰는 UML 실전 모델링
4회.닷넷 환경에서 UML 툴 활용 가이드
5회.표준을 넘나드는 UML의 적절한 사용
UML을 중심으로 소프트웨어 업계에서 벌어지는 경제적, 사회적 현상들을 알아보고 UML 2.0 발표 이후 소프트웨어 업계에 불어 닥칠파장에 대해 알아본다. 또한 UML 2.0에서 개발자들이 주목해야 하는 세부 내용도 간단히 검토해 보자.
UML 2.0의 실로 엄청난 중요성을 미리 알고 대비할 것인지, 뒷짐 지고 좀 더 지켜볼지는 이번 글을 보고 판단해 주기를 바란다.
필자는 지난 2004년 마이크로소프트웨어 8월호에 MDA 관련 글을 기고하던 당시부터 지금까지 필자의 소속 회사가 지난 10여 년간 전문적으로 개발해 오던 인적 자원 관리(HRM) 시스템에 대한 획기적인(?) 개선 방안으로 MDA 기반의 시스템 개발을 추진하고 있다. 필자가 본격적으로 UML 2.0을 검토하기 시작한 것도 8월을 전후해서였다.
그러나 회사에서 표준으로 사용하는 모델링 도구 제작 업체에서는 4개월 전만 해도 UML 2.0을 지원하지 않았고, MDA 패러다임을 표방하면서도 아쉽게도 그 요체인 UML 2.0은 그저 각종 문서나 자료들을 통해서만 접할 수 있었다. 인사 비즈니스 프로세스 개선 작업(BPI)과 같은 초기 설계 작업은 UML 1.4 기반으로 추진해야 했고, 올 연말로 예정됐던 도구 공급사의 차기 버전을 기대해야 하는 상황이었다.
그러던 얼마 전, 필자는 해당 업체로부터 UML 2.0을 충실히 지원하게 된 새 버전의 케이스 도구를 입수했다. 비록 필자가 이미 여러 책이나 자료들을 통해 UML 2.0을 검토했었음에도, 막상 본격적으로 UML 2.0 지원 모델링 도구를 설치하고 작업을 착수하려던 그 순간의 첫 느낌을 말로 하자면 막막함 그 자체였다.
그 모델링 도구의 새로운 버전이 완전히 개편된 새로운 사용자 인터페이스로 구성됐으며 내부적으로도 상당한 기술적인 패러다임 전환이 있었던 것도 한 원인이었겠지만, 무엇보다도 근본적으로 UML 2.0이 내포한 그 가능성과 확장성에 대한 놀라움과 설렘이 교차하면서 만들어낸 미묘한 흥분과 두려움이었다는 것이 적절한 것 같다. 1620년 메이플라워호를 타고 미지의 땅 아메리카에 첫 발을 내디뎠던 이주민들의 마음이 이렇지 않았을까?
UML의 사회적 파장
UML 2.0 발표와 더불어 개발자들이 주목해야 하는 세부 내용을 살펴보기 전에 우선, UML을 중심으로 소프트웨어 업계에서 벌어지는 경제적, 사회적 현상들을 통해 향후 UML 2.0 발표 이후 소프트웨어 업계에 불어 닥칠 파장에 대해 미리 가늠해 보는 시간을 가져 보기로 하겠다.
IT 시장 변화에 주목하자
이 시대 소프트웨어 산업에 종사하는 사람이, 딴 세상에 사는 사람(beings in heaven)이 아닌 이상, 자본주의 시대를 살아가는 현대인으로서 공급과 수요를 결정하는 시장 논리로부터 자유로울 수는 없다.
우리는 종종 뛰어난 기술력을 갖추고 있음에도 망하는 반면, 특별한 기술력을 가지고 있지 않음에도 번창하는 사람이나 기업을 종종 목격하곤 한다. 즉, 기술력이 곧 성공을 의미하지는 않는다. 마찬가지 논리로, UML 2.0이 아니라 그 어떤 뛰어난 기술이 존재한다 하더라도 IT 시장에서 그 기술력을 필요로 하지 않거나 수용할 수 없다면, 그 기술력의 시장 가치는 무의미할 수밖에 없다.
2000년을 전후해서 전세계적으로 Y2K 문제가 사회적 문제로 부각되고 시스템의 대공황 사태가 예고되던 시절, 아이러니컬하게도 당시 소프트웨어 산업에서는 사양길로 접어들었던 프로그래밍 언어의 전문가들이 국내의 IMF 사태와 맞물려 고액 연봉으로 대접 받으면서 해외로 진출했던 일이 기억난다. 역시 기술의 가치(technology value)는 시장 원리(market behavior)에 의해 결정될 수밖에 없음을 인정하지 않을 수 없다.
그런 관점에서 UML 2.0이 공식적으로 공표되는 전후의 소프트웨어 산업계 판도를 살펴보는 것은 의의가 있다. 세계적으로 이미 프로그램 개발 도구 시장은 그 성장세가 둔화됐고, 모델링 도구는 빠른 속도로 보편화되어 가고 있다. 지난 몇 년간 일어났던 IT 업계의 큰 사건들을 살펴보면 그러한 사실을 쉽게 확인할 수 있다.
이를테면 예전에는 비싸게 판매하던 개발 도구를 점차 저렴하게 행사 가격으로 판매한다거나, 개발자 저변 확산이라는 명목 하에 학교나 학원을 중심으로 무료로 배포하고 있다. 심지어는 이클립스 등과 같은 막강한 개발 도구를 오픈소스로서 인터넷을 통해 무료로 배포하고 있다.
몇 년 전 세계적인 소프트웨어 업체인 MS에서는 비지오(Visio)라는 2D 전용 도구 개발 업체를 인수했고, IBM은 세계적인 모델링 도구 전문 개발 업체인 래쇼날을 인수합병했으며, 연이어 볼랜드에서는 투게더를 사들였다. 한편, 국내외 UML 관련 포럼이나 협회들에서는 앞다퉈 UML 관련 인증 제도를 만들어 발표하면서 그 인지도를 넓혀 가기 위한 대대적인 작업을 벌이고 있다.
UML 인증 제도의 필요성이라든지, 인증 제도 자체의 신빙성이나 효용성에 대해 논하기 이전에, 어떠한 사상이나 개념이 제도화 되는 과정을 거치고 있다는 사실은 그 사상이나 개념이 해당 분야에서 도입기(intro)와 성장기(growth)를 거쳐 성숙기(mature)에 진입하고 있음을 암시하는 것이다.
표준화의 숨은 뜻
UML을 논하면서 표준화(standardization)라는 키워드를 빼놓을 수 없다. UML이 발표되기 전에 국방이나MIS분야 엔지니어들에게 친숙한 IDEF라든지 DFD, ER 혹은 Petri nets 등과 같은 정형 기법(formal method)으로 통칭되는 수많은 표기법(notation)과 지원 케이스 도구들이 존재했음에도 불구하고(참고자료:[1]번혹은[2]번등), UML은 가장 단기간 동안 소프트웨어 공학 분야에서만큼은 빠른 속도로 사실상의 표준(de-facto)의 위치를 확보했다. 언뜻 생각해 보면 UML이 여타 표기법들을 교통정리해 준 안도감(?)이 들 수도 있겠지만, 겉으로 잘 드러나지 않는 그 내막에는 무서운 음모(?)가 도사리고 있다.
표준화 작업에 주도적인 역할을 수행하는 업체들이 왜 그토록 천문학적인 자본을 투자하면서 공개적인 표준화 작업에 동참하는 것일까? 여러 가지 복합적인 이유들이 있을 수 있겠지만, 결론적으로 표준화 경쟁이다.
유명한 예로, 1970년대부터 시작됐던 빅터(Victor)의 VHS 방식과 소니의 베타 방식으로 대표되는 비디오 표준 전쟁을 들 수 있고, 최근에는 유럽과 미국을 중심으로 벌어지고 있는 위성방송 표준화 전쟁을 들 수 있다. 표준화 전쟁에서의 승패는 곧 기업의 운명을 좌우하는 것이다.
표준화의 이면에는 높은 진입 장벽을 통해 허가 받지 않은 침입자(intruder)를 봉쇄하려는 무서운 저의가 자리 잡고 있다. 시야를 좀 더 넓혀 보면, 의사나 판사, 회계사 등. 통속적인 표현으로 소위 ‘사’자로 끝나는 직업들에 대한 사회적 가치관을 살펴보면 쉽게 이해할 수 있다.
사람 몸을 열어서 칼질하고, 같은 인간으로서 다른 인간을 판단하고, 숫자 가지고 씨름하는 직업이 산업혁명 이전에는 별볼일 없는 직업이었다. 인류의 보편적인 가치관으로 판단하더라도 결코 즐거운 일이 될 수 없음에도 불구하고 전세계적으로 공히 가장 선호하는 직업이자 사회적으로도 가장 대접받는 직업이 된 현실에 미루어 짐작해 보면, 왜 그토록 세계적인 소프트웨어 업체들이 표준화를 통해 높은 진입 장벽을 구축하고 제도화에 전념하는지 그 이유를 충분히 이해할 수 있다.
어려운 시험을 통과하지 않고 누구라도 일정한 요건만 갖추면 수행할 수 있는 일반적인 직종 중의 하나라면 그렇게들 동경하는 직종이 됐겠는가? UML 2.0이 경제적으로나 사회적으로 주목 받는 이유 중의 하나는 바로 그러한 맥락에서 비전문인과 전문가를 구별하는 높은 장벽(?)을 쌓을 수 있는 재료(material)를 확보하고 토대를 마련했다는 점에서 의의가 있는 것이다.
주목해야 할 UML 2.0의 핵심 메커니즘
1997년 11월 UML 1.1로 시작된OMG의 표준화 노력은 2001년 5월 UML 1.4 발표와 더불어 부분적인 개정 작업(minor version upgrade)의 막을 내리고, 대대적인 수술 작업을 거쳐 2004년 연말을 전후로 드디어 그 실체를 드러내었다.
그 동안 쟁쟁한 세계적인 소프트웨어 벤더들간의 보이지 않는 이해 관계(?)에 얽혀 2002년 말로 예정됐던 최종 발표 시한을 2년여를 연장하면서 이제서야 그 대단원의 막이 마무리되고 있다. 향후 UML 2.0의 일정은 명실상부한 국제 표준(de jure)으로 자리매김하기 위해 ISO 설계 표준으로 추진 중인 것으로 알려져 있다.
UML 2.0이 주목 받는 가장 중요한 이유는 무엇일까? 처음 세상에 나오고 나서는 여기저기서 수많은 비판을 받았지만, 그것은 UML이 어떠한 플랫폼이나 도메인에도 의존하지 않고 소프트웨어 개발의 전 공정(SDLC)을 지원하는 방향으로 지향해왔다는 데에 그 원인을 찾을 수 있다. 즉, 요구사항 획득으로부터 마지막 테스트까지 모두 지원하는 표기법으로서 진화해 왔다는 것이다.
그리고 점진적으로 UML 2.0부터는 실행 모델(executable UML)이라는 기법을 수용함으로써, 소프트웨어 공학에서 궁극적으로 염원하던 분석 설계(analysis & design)와 실제 구현(implementation) 간의 차이(chasm)를 극복하는 성과를 보였기 때문이다.
OMG의 UML 2.0에 대한 제안요청서(RFP)의 주제이자 현재 채택된 명세서 초안은 크게 4가지의 영역으로 분류된다. CASE 도구 벤더들간의 모델 호환성 문제를 다루고 있는 다이어그램 호환(Diagram Interchange) 영역과 모델 수준에서의 요소(elements) 제어 및 제약 문제를 다루고 있는 OCL(Object Constraint Language) 영역, UML뿐만 아니라 OMG가 주관하는 각종 표준의 통합과 정의에 활용되는 메타 모델 수준의 기본 구조체(constructs)를 명시하고 있는 하부구조(Infrastructure), 그리고 메타 모델을 기반으로 사용자 수준에서 모델을 활용하여 시스템의 구조(structure)와 행위(behavior)를 정의하고 있는 14개의 다이어그램을 정의하고 있는 상부구조(Superstructure)로 분류할 수 있다.
UML 2.0의 본질을 제대로 이해하려면 핵심인 하부구조로부터 차근차근 살펴보는 것이 순서이겠지만, 지면과 주제를 고려할 때, 일반인들이나 설계자들이 UML 2.0을 처음 대면하는 경우 가장 먼저 관심을 가지게 되는 UML 구조체(user-level constructs)인 상부구조로부터 이야기를 풀어가는 방식을 택하기로 하겠다.
*빨간 밑줄: 새롭게 추가된 다이어그램, 녹색 밑줄: 명칭이 변경된 다이어그램
상부 구조는 크게 6개의 다이어그램으로 구성된 구조형 다이어그램(Structural Diagram)군과 7~8개의 다이어그램으로 구성된 행위형 다이어그램(Behavioral Diagram) 군으로 분류할 수 있는데, 각 군의 대표적인 복합 구조 다이어그램(Composite Structure Diagram)과 순차도(Sequence Diagram)를 중심으로 그 특징과 의의를 살펴보도록 하겠다.
이어서 UML 2.0의 기반을 설명하고 있는 하부구조의 의미는 무엇인지, 그리고 실제 설계 작업에서 하부구조의 접근법은 어떠한 방식으로 활용하게 될 것인지 논의하기로 하겠다.
상부구조 - 구조형 다이어그램
일명 아키텍처 다이어그램(architectural diagram)이라고도 불리는 복합 구조 다이어그램(composite structure diagram)은 UML의 핵심 다이어그램인 클래스 다이어그램의 변형된 형태이다. 이는 시스템 구조 설계에 있어 또 다른 핵심 축으로 평가 받고 있으며 가장 주목 받는 다이어그램 중의 하나이다.
복합 구조 다이어그램은 기본적으로 시스템 혹은 컴포넌트의 내부 구조(internal structure)를 명시적으로 중첩시켜 표현하고 있으며, 시스템 아키텍처의 보다 섬세한 분석과 설계 사상을 담을 수 있게 된 점이 가장 큰 매력으로 꼽을 수 있다.
그렇다면 왜 복합 구조 다이어그램이 주목받는지, 그리고 복합 구조 다이어그램은 왜 탄생하게 되었으며, 향후 어떠한 용도로 활용하게 될까? 보는 시각에 따라 의견을 달리 할 수 있겠지만, UML 1.x은 근본적으로 OOAD 수준의 설계 사상을 표현하기에 최적화된 표기법으로 평가되어 왔다.
UML 1.x에도 비록 컴포넌트 다이어그램이라는 것이 있기는 했지만, 실제 너무 빈약한 문맥(semantics)으로 인해 별로 활용되지 못했으며, 강경한 컴포넌트 신봉자들이나 대용량 시스템 혹은 전체 시스템을 통합적으로 표현하기 원했던 아키텍처 전문가 진영 개발자들에게는, 그저 객체 옹호론자들이 제시하는 옹색한 명분(?)에 지나지 않았다. 사실 UML 1.x 자체에도 명시하고 있듯이, 컴포넌트 다이어그램은 몇몇 다이어그램들과 더불어 클래스 다이어그램에 일종의 간단한 확장 메커니즘을 통한 단순한 관점(view) 변경 수준에 지나지 않았다.
비즈니스 컴포넌트에 관심이 많았던 컴포넌트 신봉자들의 경우, UML 1.x의 스테레오타입(stereotype)등의 확장 메커니즘을 통해 그럭저럭 UML 1.x과의 관계를 유지하면서도 BPM이라는 포괄적이고 확장된 별도의 비즈니스 컴포넌트 표기법을 병행하며 UML 1.x의 미비한 부분을 채워 나갔다.
아키텍처 전문가 진영에서는 상황이 조금 달랐는데, 대다수의 아키텍처 전문가 진영에서 관심을 가지고 있던 임베디드 혹은 리얼타임 도메인에서는 단순히 UML 1.x 정도의 확장 메커니즘으로는 그들이 필요로 하는 아키텍처를 통한 시뮬레이션 등과 같은 시스템의 섬세한 분석 및 설계라는 목적 달성이 거의 불가능했고, 그러한 목적 달성을 위해 UML의 확장 메커니즘을 활용한다는 것은 차라리 자신들만의 특정 영역에 필요한 표기법을 자체 정의하여 사용하는 것이 훨씬 경제적이었다는 것이다.
왜냐하면 이미 아키텍처 전문가 진영에서는 UML 1.x가 발표되기 이전에 광범위하게 수많은 ADL(Architectural Description Language)과 관련 시뮬레이션 도구들이 개발되어 활용되고 있었으며, 굳이 UML에 순응하는(compliant) 방안을 모색하기 위해 UML을 연구하고 고민할 시간적 여유나 명분이 없었던 것이다.
그러나 그러한 두 진영에서 근본적으로 해결하지 못한 결정적인 문제는 자신들이 독자적으로 발전시켰던 표기법 중에 어떠한 것도 명실상부한 사실 표준(de-facto)으로 합의하지 못했다는 것이다. 가령, 아키텍처 전문가 진영에서 필요로 하는 시스템 시뮬레이션 기능을 구현하는 데 사용하는 정형 기법의 경우 동일한 도메인에서조차 연구소나 익숙한 기법에 따라 서로 달리 정의하고 필요한 시뮬레이션 도구를 개발해야 했다.
국제적인 공동 작업은 말할 것도 없이 국내에서 서로 다른 연구기관이 공동 작업을 수행하기 위해서도 사전에 일정한 표준 정형 기법을 합의하고 정립한 후 과제를 수행해야 했으며, 최종적으로 통합하는 과정에서는 결국에 모델 수준에서의 통합을 포기하고 구현 수준에서 테스트를 통해 통합하는 방식을 따라야 하는 문제점을 내포하고 있었다.
덧붙여 두 진영에서 해결하지 못한 결정적인 문제 중의 하나는 실제 구현(code)에 필요한 낮은 추상화 수준의 설계에 대해서만큼은 어설픈 UML 1.x의 메커니즘만한 수준의 방안을 제시하지 못했다는 것이다.
UML 2.0에서 새롭게 등장한 복합 구조 다이어그램은 바로 지금까지 앞서 살펴 본 아키텍처 전문가 진영으로 대표되는 임베디드 혹은 리얼타임 도메인의 핵심 개념이자 도구였던 SDL(Specification Description Language)을 수용하여 탄생한 다이어그램이다.
|
|
| <그림 2> UML 2.0 복합 구조 다이어그램 예 |
UML을 잠시라도 살펴 본 경험이 있는 개발자들이라면, 복합 구조 다이어그램의 개략적인 형태만을 보고서도 쉽게 그 특징을 이해할 수 있을 것이다. 즉, 복합 구조 다이어그램은 매우 직관적인 형태를 취하고 있으며, 기존의 UML 1.x에서 단순한 패키지 개념의 서브시스템 내부를 구성하고 있는 클래스 다이어그램으로만 표현이 가능하던 시스템 내부 구조를 보다 섬세하게 설계할 수 있게 됐다.
그렇다고 <그림 2>와 같이 대부분의 UML 2.0을 기반으로 한 샘플들처럼 임베디드나 리얼타임 도메인과 같이 상대적으로 소프트웨어의 비중이 작은 단위 시스템이나, 특정 MIS 분야의 단위 서브시스템의 내부 설계에만 국한되어 복합 구조 다이어그램을 활용하겠다고 생각한다면, UML 2.0의 본질을 제대로 이해하지 못하고 있는 것이다.
복합 구조 다이어그램의 형태는 앞서 언급한 아키텍처 전문가 진영에서 아키텍처를 표기하는데 가장 많이 활용하는 아키텍처 스타일인 C&C(Component & Connector) 뷰 타입(view type)과도 일맥상통하는데, 복합 구조 다이어그램을 활용하고자 하는 모델의 추상 수준을 높이면 대규모 시스템의 아키텍처도 매우 유용하게 설계할 수 있게 된다.
<그림 2>에서 벤딩머신(VendingMachine)으로 되어 있는 부분을 인사시스템이라 정의하고 내부 부분(parts)들을 그것을 구성하고 있는 단위 시스템으로 정의하게 되면, 외부 인터페이스를 통해 회계시스템(AS)이나 고객관리시스템(CRM) 등과 주고받아야 할 데이터나 정보를 명시적으로 설계에 반영할 수 있을 것이다.
바로 설계자가 의도하는 어떠한 추상화 수준의 모델이라도 UML 2.0의 복합 구조 다이어그램은 보다 섬세하게 설계할 수 있도록 일관된 문맥(context)과 의미(semantics)를 제공하고 있는 것이다.
상부구조 - 행위형 다이어그램
UML 2.0 상부구조 중 구조형 다이어그램은 말 그대로 구조적인 혁명을 꾀했다면, 행위형 다이어그램 군에서는 시스템의 동적 설계를 제대로 반영하기 위해 기존의 행위형 다이어그램 군 소속 다이어그램의 의미(semantics)를 보강하고 정제함으로써, 진화 방식을 선택했다는 표현이 적절할 것 같다.
그 근거로서 앞서 복합 구조 다이어그램으로 대표되는 구조형 다이어그램에서 수용한 SDL의 경우와는 다르게 UML 1.x에서 이미 수용하던 MSC(Message Sequence Chart) 개념을 UML 2.0에 와서는 전폭적으로 수용하여 순차도(Sequence Diagram)를 중심으로 행위형 다이어그램들의 유기적 결합 통로를 확보함으로써 시스템의 모델 수준에서의 논리적인 실행을 그대로 설계에 반영할 수 있는 발판을 마련했다.
<그림 3>에서 보는 바와 같이 UML 2.0 순차도의 가장 두드러진 특징은, 기존의 UML 1.x에서 지원하지 못했던 시스템의 분기, 참조, 병렬 실행 등과 같은 세세한 부분들까지도 지원이 가능하도록 중첩된(nested) 표기법 체계를 설계 기법으로 도입했다는 사실이다.
MSC와 같은 기법에 익숙한 개발자들에게는 언뜻 보기에 별로 특이할 것이 없어 보일지 모르지만, 중요한 사실은 UML 2.0을 표준 표기법으로 수용함으로써 어떠한 비즈니스 도메인이나 기술 영역에서도 <그림 3>의 순차도 뿐만 아니라 UML 2.0의 다른 다이어그램들과 유기적인 연결고리를 가지고 활용함으로써 거의 무한대에 가까운 표현 수단을 확보할 수 있다는 사실이다.
UML 2.0 상부구조 중 행위형 다이어그램의 갱신에 대해 많은 관심을 가지는 사람은 임베디드 혹은 리얼타임 진영에 종사하고 있는 개발자들이겠지만, 기존의 비즈니스 프로세스 모델링 분야에서 종사하던 개발자 진영도 깊은 관심과 기대를 가지고 있다.
필자 또한 비즈니스 프로세스 모델링과 관련하여 행위 형 다이어그램의 특성과 최적 방안을 모색하고 있는데, 동일 비즈니스 도메인에서조차 개별 기업마다 그 특성과 비즈니스 프로세스 처리 방식이 천차만별인 문제를 해결하고자 등장했던 워크플로우 엔진 혹은 설계 시스템(workflow engine or system)과 같은 전문적인 도구의 기능을 충분히 대치할 방안이 마련된 것으로 평가되고 있다.
하부구조 - 메타 모델
소프트웨어 공학 분야에서는 이런 속설이 있다. 자신의 분야에서 메타 모델 기반의 접근을 하게 되면 하나의 논문이 된다. 매일 고객들과 씨름하면서 현장에서 일하는 개발자들에게는 먼 나라 이야기처럼 들리고, 현실적으로는 일정 규모의 연구소 혹은 학교에서나 다루어질 만한 주제로 치부됐던 것이 사실이다.
UML 2.0 하부구조(Infrastructure)는 일반적으로 UML 2.0을 지칭할 때 생각하는 UML 2.0 상부구조뿐만 아니라 OMG의 또 다른 메타 모델 집합인 MOF, CWM 뿐만 아니라 미래의 새로운 표준을 정의하기 위해 심혈을 기울여 정의한 메타 모델이다.
OMG에서 처음 메타 모델 4계층 개념을 발표했을 때에는 그저 개념적인 내용으로만 인식하지 못했지만, UML 2.0의 실체가 드러나고 그것을 지원하는 케이스 도구들의 기능들이 메타 모델 기반 설계 방식을 지원함으로써, 이제는 메타 모델이라는 주제가 현장에서조차 피해갈 수 없는 현실 문제로 다가올 것이다. 그러므로 이제는 메타 모델 4계층 개념을 충분히 이해하고 응용하는 노력을 기울일 필요가 있다.
글의 주제와 지면 관계상 메타 모델에 대한 깊이 있는 논의를 하지는 못하지만, <그림 4>의 예로 간단히 살펴보자. 시스템 분석가나 설계자들이 일반적인 모델링 케이스 도구를 통해 특정 도메인 시스템을 설계한다고 했을 때의 메타 모델 수준(level)이 바로 사용자 모델을 도식하게 되는 M1 수준이다.
M2 수준은 그러한 UML 기반의 설계를 가능케 하는 어트리뷰트, 클래스, 인스턴스 등과 같은 모델 요소를 정의하는 메타 모델이며, UML 2.0의 하부구조는 바로 위 4계층 메타 모델 관점에서 M2 수준의 UML 메타 모델이 된다. M3 수준에 위치한 MOF(Meta Object Facility)는 M2 수준에 속한 메타 모델을 정의하는 메타메타 모델이 된다.
참고로 CWM(Common Warehouse Metamodel)은 M2 레벨이며, MOF의 내부 구조는 추상화된 UML 하부구조와 동일한 방식으로 정의하고 있다. 자세한 사항은 OMG UML 2.0 Infrastructure, 7. Language Architecture를 참조한다.
앞에서 살펴 본 바와 같이 OMG에서 UML 2.0 관련 제안요청서(RFP)를 제기한 목적은 단순히 UML 2.0을 체계적으로 정리하고자 한 것이 아니라, OMG의 또 다른 표준인 MOF와 CWM 및 미래의 새로운 표준을 체계적으로 정의하기 위한 용도로 제기됐던 것이다. 여기서 우리가 주목해야 할 사항은 UML 2.0 하부구조에 대한 제안요청서를 통해 제기한 또 다른 목적이다.
그것은 바로 지금까지 M1 수준에서 UML을 활용하던 사용자들이 보다 수월하게 M2 수준에서 UML을 커스터마이징하여 활용할 수 있는 메커니즘을 제공하는, 즉 이원화된 메커니즘을 제공하여 사용자들이 유연하게 특정 기술 도메인이나 비즈니스 도메인에 최적화된 방식으로 설계를 수행할 수 있도록 하자는 데 그 취지가 있었다.
그 핵심이 바로 UML 프로파일(UML Profiles)이다. 지금 UML 2.0 작업과 동시에 진행되고 있는 대표적인 기술 도메인 프로파일로는 우리들에게 친숙한 EJB 프로파일(Profile for EJB), 닷넷 프로파일(Profile for .Net)을 들 수 있다. 프로파일을 간단히 설명하면, 일종의 특정 기술이나 비즈니스에 적절한 커스터마이징된 확장 메커니즘을 사전 정의해 놓고, 추상화 수준이 서로 다른 모델들간의 전환(transformation)을 자동화시키는 핵심 메커니즘이다.
플랫폼 독립 모델(PIM: Platform Independent Model)로부터 특정 플랫폼 종속 모델(PSM: Platform Specific Model)로의 자동화된 전환이라는 MDA의 사상이 바로 대표적인 일례라고 볼 수 있다. UML 프로파일은 향후 MDA를 통해서 달성하려고 하는, 아니 궁극적으로 UML 2.0을 통해 달성하게 될 소프트웨어 공학의 핵심 화두인 소프트웨어 개발 생산성 향상의 핵심 메커니즘으로 평가 받고 있다.
만약 이 글을 읽는 개발자가 속한 관련 분야에 MIS 분산 시스템 개발의 사실 표준으로 통용되는 J2EE나 닷넷 등과 같은 개발 기술 표준 프레임워크가 존재한다면 다행스러운 일이다. 모델링 도구 벤더에서 제공하는 EJB 프로파일이나 닷넷 프로파일과 같은 기술 메타 모델은 그대로 활용하고, 관심 비즈니스 영역에 해당하는 표준 도메인 프로파일을 활용하거나, 독자적으로 정의해 설계 작업을 추진해 나갈 수 있기 때문이다.
하지만 최악의 경우 관련 분야에 기술이나 도메인 프로파일이 존재하지 않고, 더욱이 활용할 만한 케이스 도구조차 존재하지 않는다면 난감하다. 하지만 UML 2.0을 충분히 지원하는 범용 혹은 상용 케이스 도구를 통해 구현된 방식이나 기능을 살펴보면 놀랄 만큼 간결하다. 문제는 UML 2.0의 프로파일 방식과 같은 메커니즘을 이해하는 것이 아니라, 그 동안 개발자들이 간과해 왔던 문제, 가령 “해당 비즈니스 도메인을 제대로 이해하고 있었는가?” 등과 같은 근본적인 문제를 되돌아보는 계기가 될 것으로 생각된다.
어떻게 대처할 것인가
지금까지 UML 2.0 출시를 전후해서 전개되어 왔던 소프트웨어 산업계의 전반적인 흐름과 사회적 파장, 그리고 UML 2.0의 상부 및 하부구조의 핵심 메커니즘을 중심으로 간단히 살펴보았다. 그렇다면 과연 어디서부터 어떻게 UML 2.0을 시작할 것인가?
기본 원칙에 충실하자
우선 스스로에게 UML 1.4는 제대로 이해하고 활용해 왔는가라는 질문을 던져 보아야 한다. 필자의 경우 하는 일이 하는 일인만큼 UML 2.0이 발표되기 이전에도 자바나 비주얼 베이직 등과 같은 프로그래밍 용어나 주제에 비해 상대적으로 UML(1.x), OOAD, CBD, 방법론 등이라는 용어가 훨씬 낯설지 않았다.
당연히 주변에는 상대적으로 코딩보다는 현장에서 분석(analysis)이나 설계(design)를 전문으로 하거나, 학교나 학원 등에서 학생들을 가르치는 사람들이 많았지만 그 중에 UML 1.x 관련된 OMG 무료 명세를 제대로 살펴보았거나, 가까이 두면서 참조하는 사람은 찾아보기 어려웠다.
필자 가까이에 ‘UML 1.4 사용자 지침서’를 한글로 번역했던 분을 통해 확인해 보아도, 국내 출판사에서 출간한 책 부수로 미루어 UML 원문은 차치하고서라도 핵심 내용만을 추려서 발간한 그 UML 사용자 지침서마저 꼼꼼히 살펴 본 사람은 별로 보지 못한 것 같다. 필자도 예외는 아닌데, 돈이 없어서 혹은 원서이기 때문에라는 것은 이유가 되지 않았던 것이다.
그런데 UML 2.0이 공식 발표되는 이 시점에도 상황은 예전이나 별반 다르지 않은 것 같다. UML 2.0으로 공식 공표되기 전에 이미 오래 전부터 OMG에는 UML 관련 명세를 1.5의 형태로 인터넷에 배포하고 있었지만, 살펴본 사람은 찾기 어려웠다. UML 1.1이 처음 발표되던 시점에는 표기법으로서의 표준화 경쟁에서 판정승이 나지 않았던 때여서 그랬다고 하더라도, UML 2.0이 공표되는 이 시점에는 이미 국내외 많은 대학의 컴퓨터 관련학과에서 필수 과목으로 개설되었을 만큼 그 중요도와 필요성이 검증된 마당에 애써 그 사실을 외면하는 것은 더 이상 이유가 될 수 없다.
물론 지금까지의 현실은 그렇지 못했던 것이 사실이다. UML 전문가들마저도 UML 1.x의 설계 도구로서의 완성도가 받쳐주지 못했고, 무엇보다도 고객들도 유기적으로 논리적인 설계 모델을 기대하지 않았기 때문에 UML이라는 포장지를 가지고 피상적이고 개념적으로 대충 구색 맞추기식 설계 산출물을 만들어 주면 그만이었다.
그러나 앞으로의 상황은 그렇지 못할 것이다. 당장은 아니겠지만 UML 2.0 표기법이 소프트웨어 산업 시장에서 보편적으로 활용되고 국내외에서 하나 둘 그 무한한 잠재력과 가능성이 증명되어 그 시장 가치가 확연히 드러나기 시작하는 시점에는 우리 주변의 고객들 또한 단순히 보기 좋은 산출물 정도의 설계를 요구하지는 않을 것이다.
그렇다면 어디서부터 어떻게 준비해야 할 것인가? 그 실마리는 처음 접하면 이해하기 어렵고 복잡한 UML 2.0 관련 명세나 두꺼운 책에서 찾을 것이 아니고, 누구나 알고 있으면서도 충실하지 못했던 가장 기본적이고 원칙적인 원리를 고민하는 것부터 시작해야 한다.
원칙 하나, 도메인을 철저하게 분석하자
시스템을 설계한다고 했을 때, UML과 같은 설계 기법을 동원하여 작업하는 시스템 분석 및 설계자 그룹 외에 매우 중요한 역할을 수행하는 집단이나 개인을 가리켜 도메인 전문가 혹은 비즈니스 분석가라고 한다. 가장 이상적인 시스템 설계자는 두 가지 능력 즉, 해당 도메인에 대한 공인된 전문적인 지식을 가지고 있으면서 동시에 설계 능력을 고루 갖춘 인재일 것이다.
그러나 현장에서 그런 핵심 인재를 찾기는 어려운 것이 사실이다. IT 업계로만 보더라도 시스템 설계자와 개발자 간에 차이가 좀처럼 좁혀지지 않는데, 전혀 그 분야와 전공이 다른 비즈니스 전문가와 시스템 전문가 간에 느끼는 갈등은 말할 필요도 없다. 시스템을 설계해 본 사람은 누구라도 공감하겠지만, 시스템을 제대로 설계하려면 해당 도메인을 충분히 이해하고 철저하게 분석해야 한다. 그렇지 않으면 제대로 된 시스템을 설계할 수 없다.
시스템 설계자 입장에서 문제는 해당 도메인을 제대로 이해하기 위한 충분한 시간도 주어지지 않고, 나름대로 시스템 설계자가 충분히 이해한 것을 객관적으로 검증해 줄 만한 기준도 마련되어 있지 않다는 것이다. 설사 객관적 기준이 있더라도 그것은 현실적으로 거의 불가능하다는 것이다.
가령 회계 시스템을 설계하려면 회계사 자격증을 갖춰야 하는가? 물론 아니다. 그런데 우리는 주변에서 타의든 자의든 특정 도메인 시스템을 반복해서 설계하는 설계자의 경우 점점 해당 도메인에 대한 이해력이 높아지고, 회계사와 같은 공인된 자격증은 취득하지 못하더라도 나름대로 그 전문성을 인정받아 시장에서 높이 평가되는 경우를 보곤 한다.
비단 시스템 설계자에게만 해당되는 문제는 아니다. 조각조각 할당된 부분만 열심히 해야 하는 개발자에게도 비슷한 현상은 쉽게 찾아 볼 수 있다.
설계하고자 하는 해당 도메인에 대한 철저한 분석 없이는 일정한 추상화 수준을 유지한 유기적인 모델을 만들어 낼 수가 없다. 몇몇 책이나 발표 자료에서 설계 팁으로 이야기 하듯이 해당 도메인에서 반복적으로 등장하는 명사(nouns)를 클래스명으로 명명한다는 식으로 설계를 진행하다 보면 점점 헤어나지 못하는 미궁으로 빠져들게 된다. 결국에는 UML 2.0이라는 강력한 설계 도구를 가지고도 설계 따로, 코딩 따로라는 늪에서 벗어날 수 없다.
UML 표준화를 주도하는 OMG에 대해서 많은 사람들은 단순히 CORBA, ORB 등과 관련한 국제적인 기술 표준화 단체 정도로만 인식하고 있다. 하지만 앞서 주장한 도메인 지식 혹은 도메인 표준에 대한 중요성에 대해서는, 그러한 기술 표준화 단체로 출범한 OMG에서 2002부터 발족하여 추진하고 있는 DTF(Domain Task Forces) 위원회의 활동을 살펴보면 쉽게 이해할 수 있다.
이미 전략전술 통제(C4I), 재무(finance), 의료(healthcare), 제조(manufacturing), 우주항공(space), 통신(telecommunications), 운송(transportation) 등의 도메인을 필두로 그 표준화 작업을 진행 중에 있으며, 여러 표준화 단체들과 연합하여 다른 도메인으로까지 표준화 작업을 확장 중에 있다.
물론 아직까지 그 시도는 기술적인 관점에서의 접근이라는 한계를 크게 뛰어 넘고 있지는 못하지만 인터넷, 즉 IT 기술을 배제한 고전적 의미의 비즈니스는 점차 그 경쟁력을 잃어 가고 있는 현실을 생각할 때 OMG의 영향력은 쉽게 무시할 수 없는 것이 될 것이다.
원칙 둘, 모델의 추상 수준
사전적 의미로도 알 수 있듯이 모델은 본질적으로 어떤 특정 사물이나 현상에 비해 상대적으로 추상화되어 있는 무엇이기 때문에 똑같은 실체에 대한 서로 다른 모델은 서로 다른 추상화 수준(level of abstraction)을 가질 수밖에 없다.
<그림 5>를 보면 똑같은 자동차를 모델로 만든 것이지만, 상단의 자동차 그림(혹은 모델)은 추상화 수준이 높고 하단의 자동차는 추상화 수준이 낮다. 여기서 중요한 것은 추상화 수준의 높고 낮음은 상대적이라는 것이다. 우리가 UML에서 제시하는 여러 다이어그램을 가지고 모델을 제작한다는 것은 결국 목표하는 자동차나 건물 등과 마찬가지의 실체 즉, 특정 시스템 하나를 완성하기 위한 노력인 것이다.
즉, 설계 작업을 수행한다는 UML 1.4의 표기법을 동원하든 UML 2.0의 표기법을 동원하든 아니면 제3의 표기법을 활용하든 목표하는 시스템을 완성하기 위한 과정이지 다이어그램 혹은 표기법 자체가 목적이 되지는 않는다는 것이다. 이러한 똑같은 모델의 원리를 UML의 다이어그램을 가지고 설명할 수 있다. <그림 5>는 UML 1.4에서 제시하는 9개의 표준 다이어그램의 추상화 수준을 계량화하는 방안으로 방사형의 표로 도식해 본 것이다.
|
|
| <그림 6> UML 1.4 다이어그램 추상화 분포 |
<그림 6>의 중앙에 위치한 지점을 설계자가 목적하는 목표 시스템의 코드 혹은 운영(run-time) 시스템이라고 한다면, 유스케이스 축에서 0.8으로 표시된 지점 정도의 추상화 수준으로 유스케이스를 작성한 것을 비즈니스 유스케이스라 할 수 있겠고, 0.4 정도의 지점 추상화 수준으로 작성한 것을 시스템 유스케이스라고 할 수 있을 것이다. 그렇게 가정해 본다면, 중앙에 가까운 지점의 추상화 수준으로 낮게 모델을 작성한다면 설계자가 목적하는 시스템은 보다 세세하게(detailed) 보이게 될 것이다.
유럽의 모든 길이 로마로 향하듯이, 어떠한 길(다이어그램)을 선택하더라도 종국에는 목적지(목표 시스템)에 도달할 수 있다. 하지만 각 다이어그램은 각자 목표하는 시스템으로 접근할 수 있는 추상화 수준의 한계를 가지고 있다.
가령, 유스케이스 다이어그램만을 가지고 시스템 설계를 완성할 수는 없는 것이다. 반면에, 클래스 다이어그램만 가지고 시스템 설계에 접근하다 보면 나무는 보고 숲을 보지 못하는 우를 범할 수 있다. 그러한 이유로 소프트웨어 설계에서 UML을 활용하여 목표 시스템을 설계할 때는 하나 이상의 다이어그램을 활용하게 된다.
대표적으로 많이 활용되는 다이어그램으로는 유스케이스, 클래스, 시퀀스 등을 들 수 있을 것이다. 문제는 여기서부터 시작 된다. 시스템 설계에 대표적인 3개의 다이어그램을 활용하든 아니면 9개의 다이어그램을 모두 활용하든 활용하는 다이어그램들이 각자 따로 존재하게 되는 것이다.
유스케이스 다이어그램 따로 클래스 다이어그램 따로 심지어는 동일한 시스템에 대한 유스케이스 다이어그램을 그리더라도 그리는 사람에 따라 서로 다른 추상화 수준(level of abstraction) 혹은 입도(granularity)의 유스케이스가 작성된다는 것이다. 이건 비즈니스 유스케이스니 이건 시스템 유스케이스니 하면서 무의미한 논쟁으로 치닫게 된다.
이러한 문제를 본질적으로 해결책하기 위해서는 그것이 UML 1.4이든 UML 2.0이든 각 다이어그램의 주된 용도(usage)와 목적(objectives), 그리고 그 한계를 충분히 이해하고, 각 다이어그램이 그러한 용도와 목적을 충족시키기 위해 제시하는 특성 표기법의 명확한 의미와 용도를 숙지해야 한다. 그 후에 활용하려는 다이어그램의 핵심 표기들 간의 추상화 수준에 대해 일관된 원칙(principle)을 우선 정립하고 설계 작업을 수행해야 한다.
가령 이러한 원칙 수립이 가능하다. 유스케이스 다이어그램을 통해 작성한 하나의 유스케이스를 하나의 활동도(Activity Diagram)로 도식하기로 했다면, 활동도의 활동(Activity)은 유스케이스 시나리오로 작성하는 사건 흐름(flow of event) 상의 단일 스텝(step)이라는 원칙을 설정하게 되면 일관된 설계 작업을 수행할 수 있다. 그러한 설계 전략을 위 <그림 6> 위에 상징적으로 표현해 보면, <그림 7>과 같이 도식할 수 있을 것이다.
|
|
| <그림 7> 다이어그램 간의 추상화 수준 조정 |
지금까지 UML 1.4를 중심으로 모델의 추상 수준이라는 원리에 대해 살펴보았다. 그러한 모델의 추상 수준이라는 핵심 메커니즘은 본질적으로 UML 2.0이라고 해서 다르지 않다. 앞선 <그림 1>과 <그림 7>을 언뜻 비교해 보아도 UML 2.0에서는 표준 다이어그램의 개수로도 UML 1.4에 비해 수적으로 많이 늘어났으며(<그림 4>에서 빨간색으로 표시된 다이어그램), 이전부터 있었던 몇몇 다이어그램들은 명칭이 변경됐고(<그림 4>에서 초록색으로 표시된 다이어그램), 무엇보다도 전반적으로 모든 다이어그램들이 보다 섬세한 설계자의 의도를 반영할 수 있도록 세부적인 표기들이 많이 추가되고 세분화됐다. 즉, 사용할 수 있는 다이어그램 선택의 폭(width)이 넓어졌고, 설계자의 의도를 보다 정밀하게 반영할 수 있는 깊이(depth)도 깊어졌다.
원칙 셋, 모델 자체의 완성도를 높이자
앞서 소프트웨어 업계에서 최근 발생하고 있는 현상들을 통해 잠시 언급했지만, UML 관련 국내외 포럼이나 협회들을 중심으로 UML 자체 혹은 설계 능력 인증 제도가 점차 많아지고 있다. 필자가 인증 제도의 본질적인 목적이나 그 가치 자체를 부정하는 것은 아니지만, 올해 사회적으로 충격을 던져 주었던 대입 수능 시험에서의 대량 부정 사태라든지, 얼마 전부터 공공연하게 제기됐던 영어 관련 인증 제도 등에서 발생하고 있는 문제점 등에 비추어 UML 인증 제도에서도 충분히 발생할 수 있는 그 변별력 문제에 대해 우려를 감출 수 없다.
그러나 다행히도 UML 2.0이 가지고 있는 그 강력한 표현력(semantic expressiveness)과 섬세함(elements precision) 그리고 다이어그램들간의 유기적 연결성 지원(support for diagram interchange) 능력으로 인해 인증서를 가지고 있다고 들먹이지 않아도 모델 결과물 자체로 그 완성도를 검증(self verification)할 수 있다. 즉, 모델 결과물만으로도 충분히 설계자의모델링 역량을 충분히 증명할 수 있는기반을 제공하고 있는 것이다.
UML 2.0이 공식으로 발표되기 이전 특정 케이스 도구들을 중심으로 시도됐지만 UML 1.4의 제약으로 그 실효성(efficiency)을 의심받았던 코드 자동 생성(automatic code generation) 기능은 케이스 도구들이UML 2.0 엔진으로 교체함으로써 그 완성도를 높일 수 있게 됐다. 더 나아가 UML 2.0이 내포한 그 풍부한 표현력과 정교함은, 특정 플랫폼에 종속적인 코드를 생성해 내기 이전에 케이스 도구의 도움을 통해 모델들만을 가지고 사전에 시뮬레이션마저도 어려운 문제가 되지 않는다.
앞으로의 전망
지금까지 개발자들은 새로운 기술이나 제품이 출시되면, 여기저기서 화려한 수식어와 찬사로 밝은 미래를 전망하는 이야기에 너무나도 익숙해져 있다. 1997년 UML 1.1이 처음 세상에 나왔을 때도 마찬가지였다. 그런 맥락에서 단순히 UML 2.0이라는 새로운 패러다임에 무조건 주목하자고 주장하고 싶지는 않다. 실리에 밝은 국내외 소프트웨어 업체들과 협회들의 행보와 여러 가지 상황을 종합해 보아도 UML 2.0이 소프트웨어 산업계에 미칠 파장의 크기는 실로 엄청날 것으로 예상된다.
그것이 더 이상 거스를 수 없는 현실이라면 그러한 도전에 수동적으로 대처할 것인가, 아니면 능동적으로 대처할 것인가의 문제는 독자 스스로 선택할 문제이다. 혹시 이솝 우화에 나오는 거짓말하는 늑대 이야기에서처럼 중요하다는 말을 너무 자주 들어 개발자들이 UML의 중요성을 공허한 메아리 정도로만 치부하고 지나칠까 걱정될 뿐이다.@
* 이 기사는 ZDNet Korea의 제휴매체인마이크로소프트웨어에 게재된 내용입니다.

원문 :http://www.zdnet.co.kr/techupdate/lecture/etc/0,39024989,39134178,00.htm
원문 :http://www.zdnet.co.kr/techupdate/lecture/etc/0,39024989,39134557,00.htm